 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Navigate in Turbulent Flows with Aerial Robot Swarms: A Cooperative Deep Reinforcement Learning Approach
Jun 07, 2023Aerial operation in turbulent environments is a challenging problem due to the chaotic behavior of the flow. This problem is made even more complex when a team of aerial robots is trying to achieve coordinated motion in turbulent wind conditions. In this paper, we present a novel multi-robot controller to navigate in turbulent flows, decoupling the trajectory-tracking control from the turbulence compensation via a nested control architecture. Unlike previous works, our method does not learn to compensate for the air-flow at a specific time and space. Instead, our method learns to compensate for the flow based on its effect on the team. This is made possible via a deep reinforcement learning approach, implemented via a Graph Convolutional Neural Network (GCNN)-based architecture, which enables robots to achieve better wind compensation by processing the spatial-temporal correlation of wind flows across the team. Our approach scales well to large robot teams -- as each robot only uses information from its nearest neighbors -- , and generalizes well to robot teams larger than seen in training. Simulated experiments demonstrate how information sharing improves turbulence compensation in a team of aerial robots and demonstrate the flexibility of our method over different team configurations.
Event-Triggered Control for Weight-Unbalanced Directed Networks
Aug 22, 2021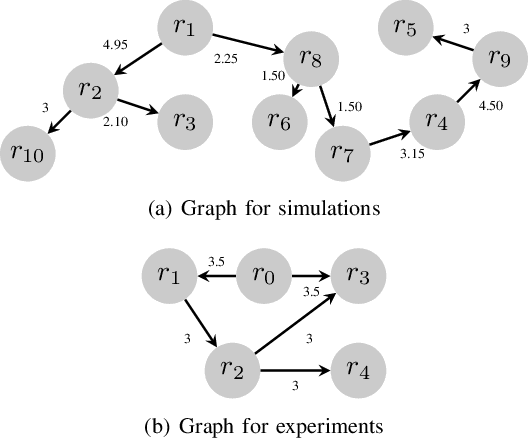
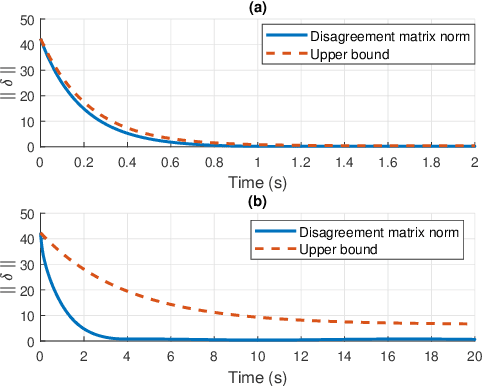
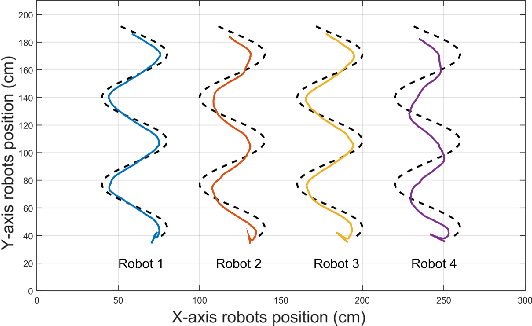
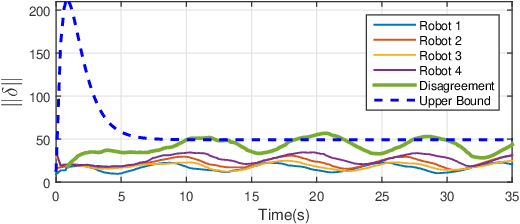
We develop an event-triggered control strategy for a weighted-unbalanced directed homogeneous robot network to reach a dynamic consensus in this work. We present some guarantees for synchronizing a robot network when all robots have access to the reference and when a limited number of robots have access. The proposed event-triggered control can reduce and avoid the periodic updating of the signals. Unlike some current control methods, we prove stability by making use of a logarithmic norm, which extends the possibilities of the control law to be applied to a wide range of directed graphs, in contrast to other works where the event-triggered control can be only implemented over strongly connected and weight-balanced digraphs. We test the performance of our algorithm by carrying out experiments both in simulation and in a real team of robots.