 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe state of the art in kidney and kidney tumor segmentation in contrast-enhanced CT imaging: Results of the KiTS19 Challenge
Dec 02, 2019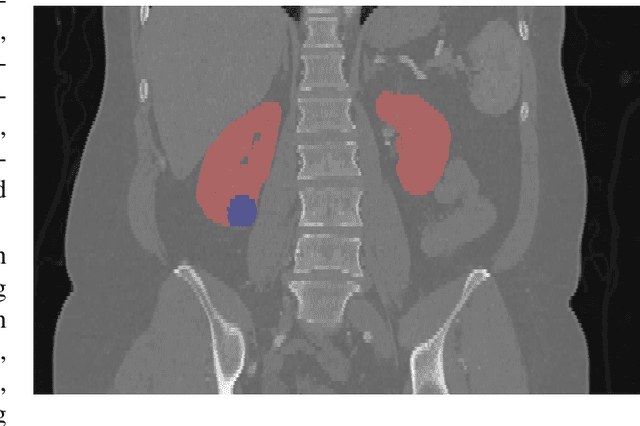
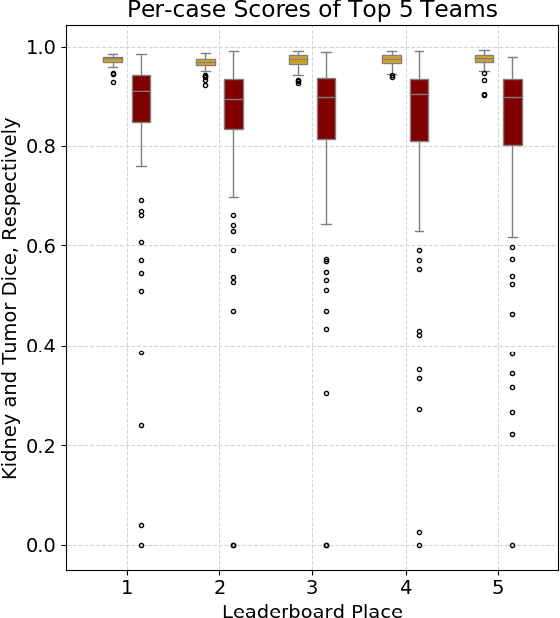
There is a large body of literature linking anatomic and geometric characteristics of kidney tumors to perioperative and oncologic outcomes. Semantic segmentation of these tumors and their host kidneys is a promising tool for quantitatively characterizing these lesions, but its adoption is limited due to the manual effort required to produce high-quality 3D segmentations of these structures. Recently, methods based on deep learning have shown excellent results in automatic 3D segmentation, but they require large datasets for training, and there remains little consensus on which methods perform best. The 2019 Kidney and Kidney Tumor Segmentation challenge (KiTS19) was a competition held in conjunction with the 2019 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) which sought to address these issues and stimulate progress on this automatic segmentation problem. A training set of 210 cross sectional CT images with kidney tumors was publicly released with corresponding semantic segmentation masks. 106 teams from five continents used this data to develop automated systems to predict the true segmentation masks on a test set of 90 CT images for which the corresponding ground truth segmentations were kept private. These predictions were scored and ranked according to their average So rensen-Dice coefficient between the kidney and tumor across all 90 cases. The winning team achieved a Dice of 0.974 for kidney and 0.851 for tumor, approaching the inter-annotator performance on kidney (0.983) but falling short on tumor (0.923). This challenge has now entered an "open leaderboard" phase where it serves as a challenging benchmark in 3D semantic segmentation.
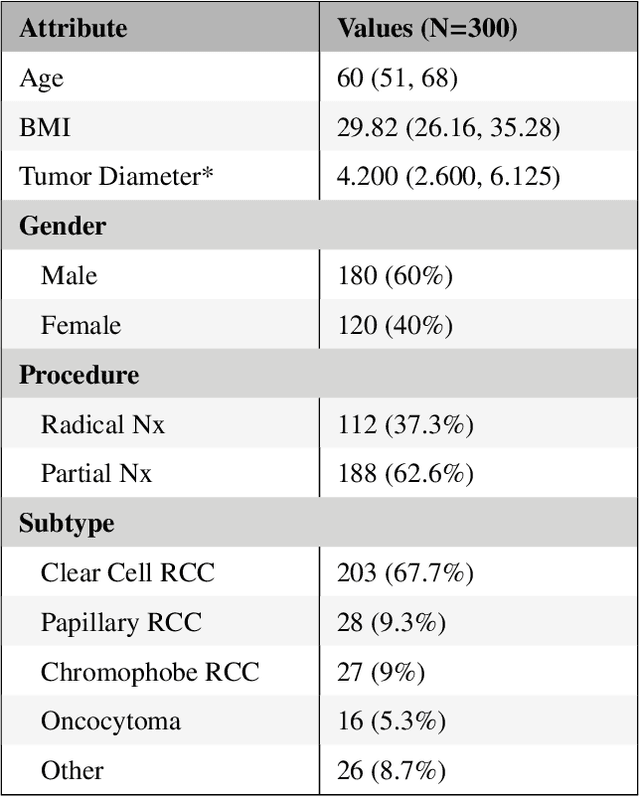
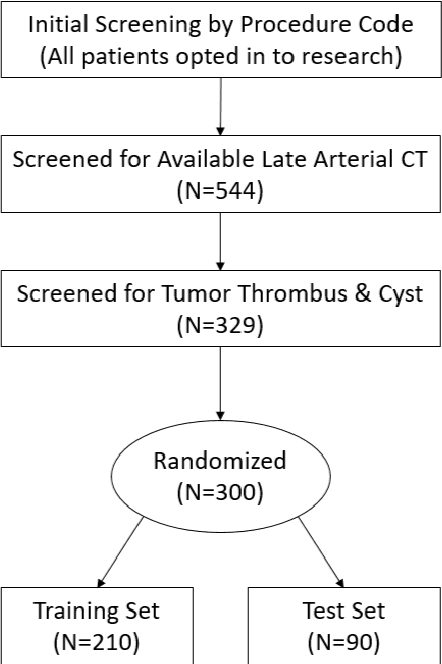
The KiTS19 Challenge Data: 300 Kidney Tumor Cases with Clinical Context, CT Semantic Segmentations, and Surgical Outcomes
Mar 31, 2019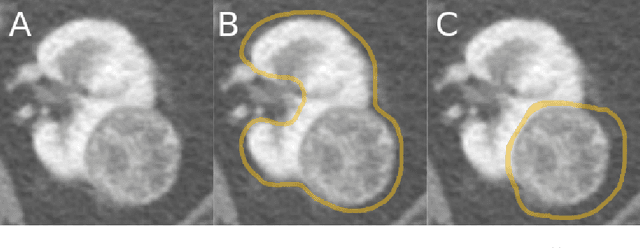
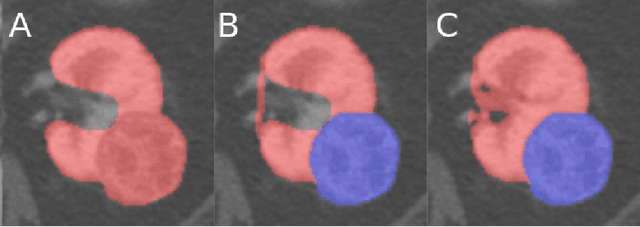
The morphometry of a kidney tumor revealed by contrast-enhanced Computed Tomography (CT) imaging is an important factor in clinical decision making surrounding the lesion's diagnosis and treatment. Quantitative study of the relationship between kidney tumor morphology and clinical outcomes is difficult due to data scarcity and the laborious nature of manually quantifying imaging predictors. Automatic semantic segmentation of kidneys and kidney tumors is a promising tool towards automatically quantifying a wide array of morphometric features, but no sizeable annotated dataset is currently available to train models for this task. We present the KiTS19 challenge dataset: A collection of multi-phase CT imaging, segmentation masks, and comprehensive clinical outcomes for 300 patients who underwent nephrectomy for kidney tumors at our center between 2010 and 2018. 210 (70%) of these patients were selected at random as the training set for the 2019 MICCAI KiTS Kidney Tumor Segmentation Challenge and have been released publicly. With the presence of clinical context and surgical outcomes, this data can serve not only for benchmarking semantic segmentation models, but also for developing and studying biomarkers which make use of the imaging and semantic segmentation masks.
Imperfect Segmentation Labels: How Much Do They Matter?
Sep 24, 2018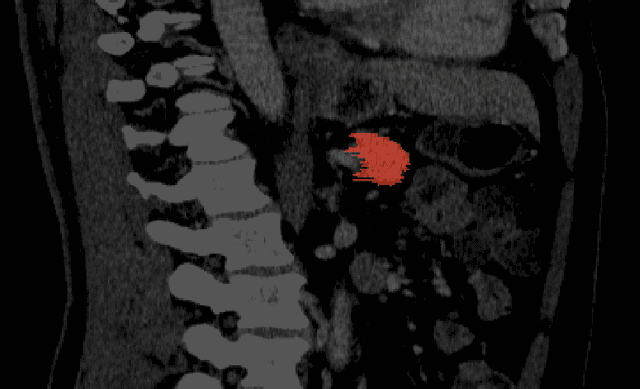
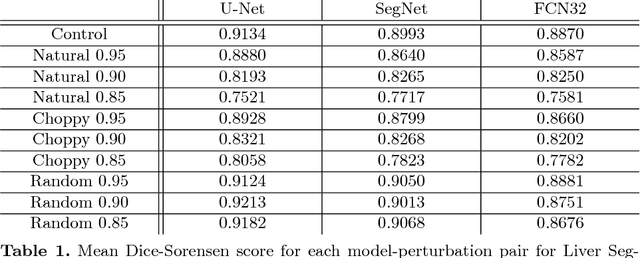

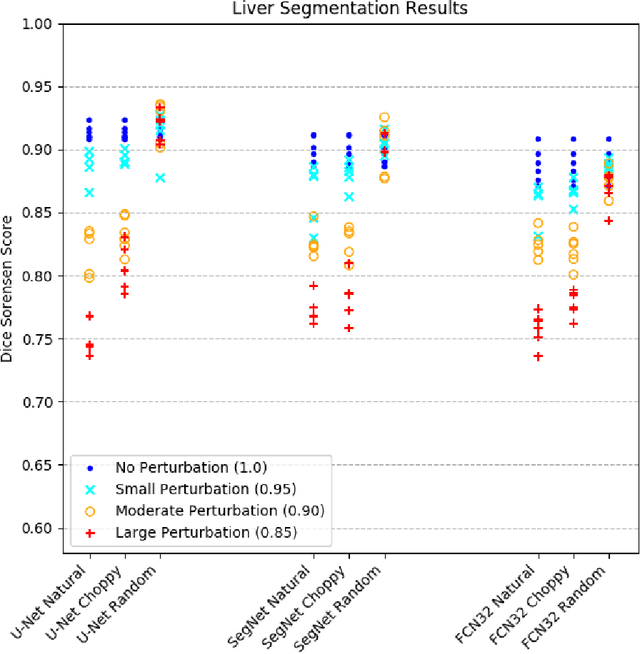
Labeled datasets for semantic segmentation are imperfect, especially in medical imaging where borders are often subtle or ill-defined. Little work has been done to analyze the effect that label errors have on the performance of segmentation methodologies. Here we present a large-scale study of model performance in the presence of varying types and degrees of error in training data. We trained U-Net, SegNet, and FCN32 several times for liver segmentation with 10 different modes of ground-truth perturbation. Our results show that for each architecture, performance steadily declines with boundary-localized errors, however, U-Net was significantly more robust to jagged boundary errors than the other architectures. We also found that each architecture was very robust to non-boundary-localized errors, suggesting that boundary-localized errors are fundamentally different and more challenging problem than random label errors in a classification setting.