 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperfect Segmentation Labels: How Much Do They Matter?
Paper and Code
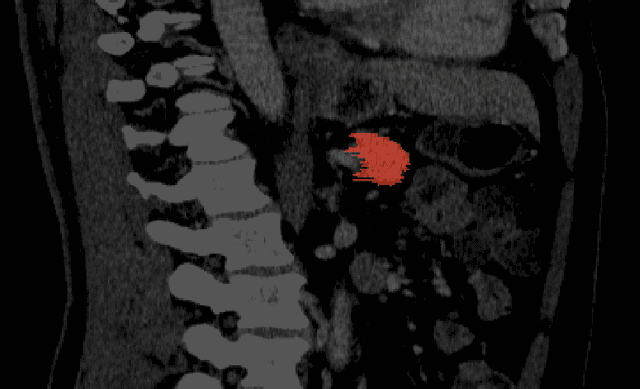
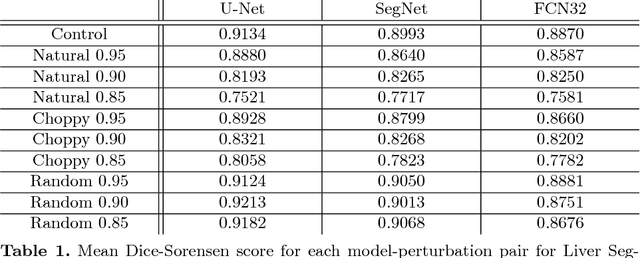

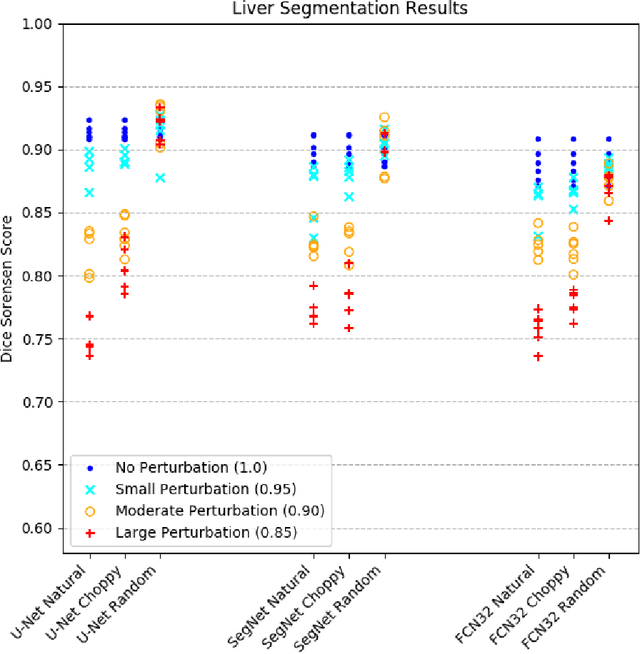
Labeled datasets for semantic segmentation are imperfect, especially in medical imaging where borders are often subtle or ill-defined. Little work has been done to analyze the effect that label errors have on the performance of segmentation methodologies. Here we present a large-scale study of model performance in the presence of varying types and degrees of error in training data. We trained U-Net, SegNet, and FCN32 several times for liver segmentation with 10 different modes of ground-truth perturbation. Our results show that for each architecture, performance steadily declines with boundary-localized errors, however, U-Net was significantly more robust to jagged boundary errors than the other architectures. We also found that each architecture was very robust to non-boundary-localized errors, suggesting that boundary-localized errors are fundamentally different and more challenging problem than random label errors in a classification setting.