 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchelling Games with Continuous Types
May 11, 2023



In most major cities and urban areas, residents form homogeneous neighborhoods along ethnic or socioeconomic lines. This phenomenon is widely known as residential segregation and has been studied extensively. Fifty years ago, Schelling proposed a landmark model that explains residential segregation in an elegant agent-based way. A recent stream of papers analyzed Schelling's model using game-theoretic approaches. However, all these works considered models with a given number of discrete types modeling different ethnic groups. We focus on segregation caused by non-categorical attributes, such as household income or position in a political left-right spectrum. For this, we consider agent types that can be represented as real numbers. This opens up a great variety of reasonable models and, as a proof of concept, we focus on several natural candidates. In particular, we consider agents that evaluate their location by the average type-difference or the maximum type-difference to their neighbors, or by having a certain tolerance range for type-values of neighboring agents. We study the existence and computation of equilibria and provide bounds on the Price of Anarchy and Stability. Also, we present simulation results that compare our models and shed light on the obtained equilibria for our variants.
Towards Explainable Real Estate Valuation via Evolutionary Algorithms
Oct 11, 2021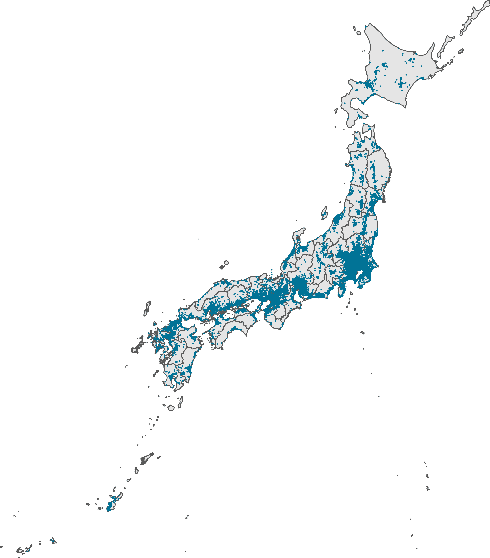
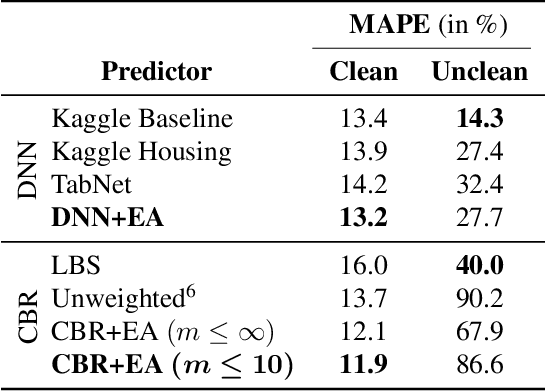
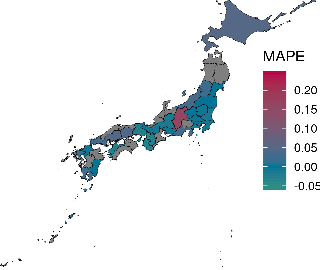
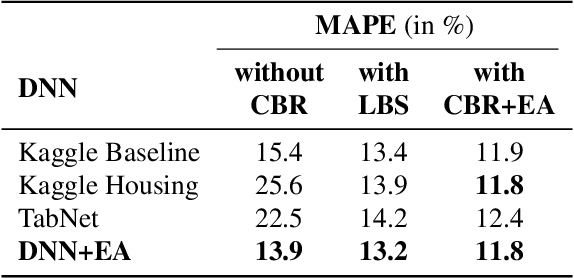
Human lives are increasingly influenced by algorithms, which therefore need to meet higher standards not only in accuracy but also with respect to explainability. This is especially true for high-stakes areas such as real estate valuation, where algorithms decide over the price of one of the most valuable objects one can own. Unfortunately, the methods applied there often exhibit a trade-off between accuracy and explainability. On the one hand, there are explainable approaches such as case-based reasoning (CBR), where each decision is supported by specific previous cases. However, such methods are often wanting in accuracy. On the other hand, there are unexplainable machine learning approaches, which provide higher accuracy but are not scrutable in their decision-making. In this paper, we apply evolutionary algorithms (EAs) to close the performance gap between explainable and unexplainable approaches. They yield similarity functions (used in CBR to find comparable cases), which are fitted to the data set at hand. As a consequence, CBR achieves higher accuracy than state-of-the-art deep neural networks (DNNs), while maintaining its interpretability and explainability. This holds true even when we fit the neural network architecture to the data using evolutionary architecture search. These results stem from our empirical evaluation on a large data set of real estate offers from Japan, where we compare known similarity functions and DNN architectures with their EA-improved counterparts. In our testing, DNNs outperform previous CBR approaches. However, with the EA-learned similarity function CBR is even more accurate than DNNs.