 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Training with Asymmetric Crosspoint Elements
Jan 31, 2022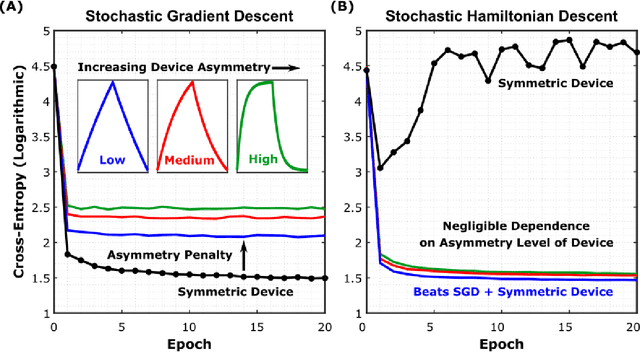
Analog crossbar arrays comprising programmable nonvolatile resistors are under intense investigation for acceleration of deep neural network training. However, the ubiquitous asymmetric conductance modulation of practical resistive devices critically degrades the classification performance of networks trained with conventional algorithms. Here, we describe and experimentally demonstrate an alternative fully-parallel training algorithm: Stochastic Hamiltonian Descent. Instead of conventionally tuning weights in the direction of the error function gradient, this method programs the network parameters to successfully minimize the total energy (Hamiltonian) of the system that incorporates the effects of device asymmetry. We provide critical intuition on why device asymmetry is fundamentally incompatible with conventional training algorithms and how the new approach exploits it as a useful feature instead. Our technique enables immediate realization of analog deep learning accelerators based on readily available device technologies.
Zero-shifting Technique for Deep Neural Network Training on Resistive Cross-point Arrays
Aug 02, 2019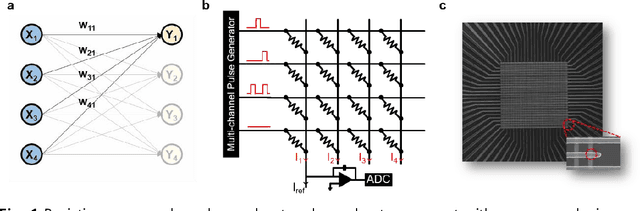
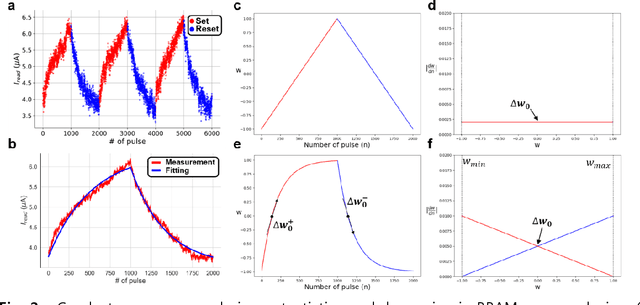
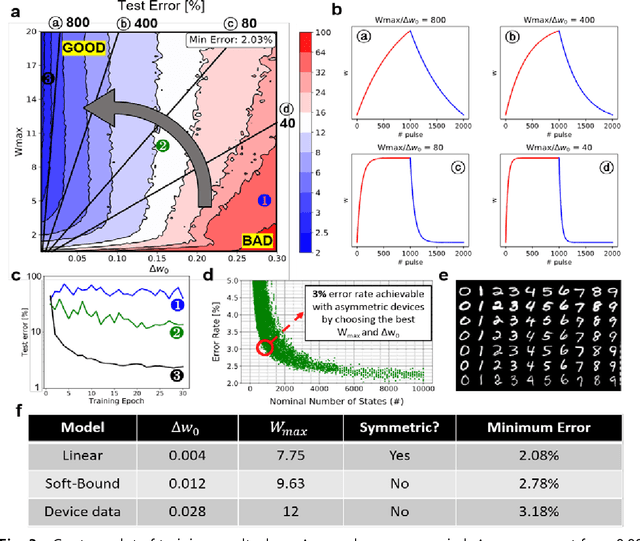
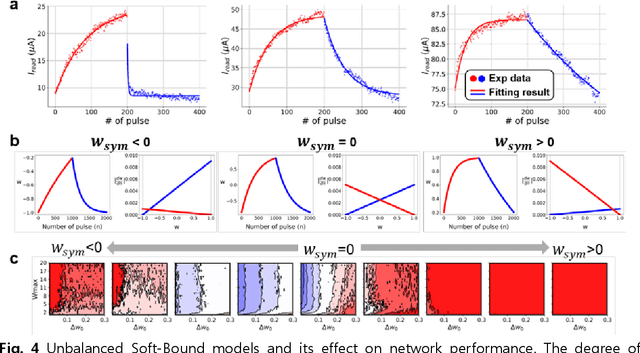
A resistive memory device-based computing architecture is one of the promising platforms for energy-efficient Deep Neural Network (DNN) training accelerators. The key technical challenge in realizing such accelerators is to accumulate the gradient information without a bias. Unlike the digital numbers in software which can be assigned and accessed with desired accuracy, numbers stored in resistive memory devices can only be manipulated following the physics of the device, which can significantly limit the training performance. Therefore, additional techniques and algorithm-level remedies are required to achieve the best possible performance in resistive memory device-based accelerators. In this paper, we analyze asymmetric conductance modulation characteristics in RRAM by Soft-bound synapse model and present an in-depth analysis on the relationship between device characteristics and DNN model accuracy using a 3-layer DNN trained on the MNIST dataset. We show that the imbalance between up and down update leads to a poor network performance. We introduce a concept of symmetry point and propose a zero-shifting technique which can compensate imbalance by programming the reference device and changing the zero value point of the weight. By using this zero-shifting method, we show that network performance dramatically improves for imbalanced synapse devices.