 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Training with Asymmetric Crosspoint Elements
Jan 31, 2022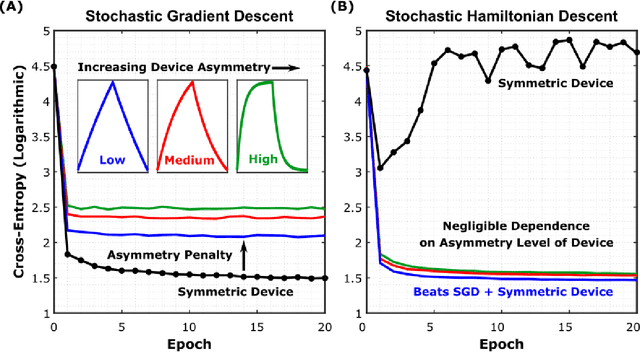
Analog crossbar arrays comprising programmable nonvolatile resistors are under intense investigation for acceleration of deep neural network training. However, the ubiquitous asymmetric conductance modulation of practical resistive devices critically degrades the classification performance of networks trained with conventional algorithms. Here, we describe and experimentally demonstrate an alternative fully-parallel training algorithm: Stochastic Hamiltonian Descent. Instead of conventionally tuning weights in the direction of the error function gradient, this method programs the network parameters to successfully minimize the total energy (Hamiltonian) of the system that incorporates the effects of device asymmetry. We provide critical intuition on why device asymmetry is fundamentally incompatible with conventional training algorithms and how the new approach exploits it as a useful feature instead. Our technique enables immediate realization of analog deep learning accelerators based on readily available device technologies.