 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based hierarchical record clustering for unsupervised entity resolution
Dec 12, 2021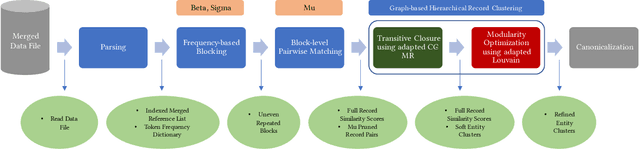

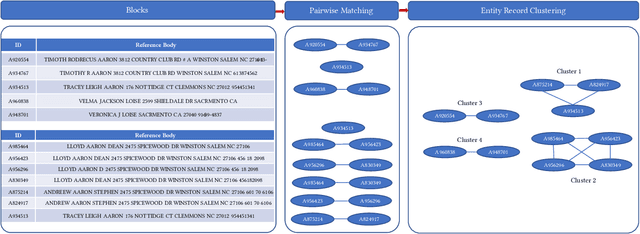
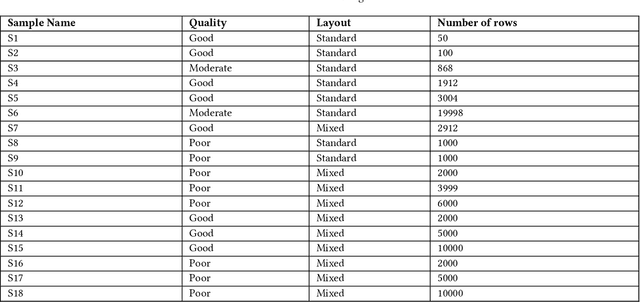
Here we study the problem of matched record clustering in unsupervised entity resolution. We build upon a state-of-the-art probabilistic framework named the Data Washing Machine (DWM). We introduce a graph-based hierarchical 2-step record clustering method (GDWM) that first identifies large, connected components or, as we call them, soft clusters in the matched record pairs using a graph-based transitive closure algorithm utilized in the DWM. That is followed by breaking down the discovered soft clusters into more precise entity clusters in a hierarchical manner using an adapted graph-based modularity optimization method. Our approach provides several advantages over the original implementation of the DWM, mainly a significant speed-up, increased precision, and overall increased F1 scores. We demonstrate the efficacy of our approach using experiments on multiple synthetic datasets. Our results also provide evidence of the utility of graph theory-based algorithms despite their sparsity in the literature on unsupervised entity resolution.
Theme-weighted Ranking of Keywords from Text Documents using Phrase Embeddings
Jul 16, 2018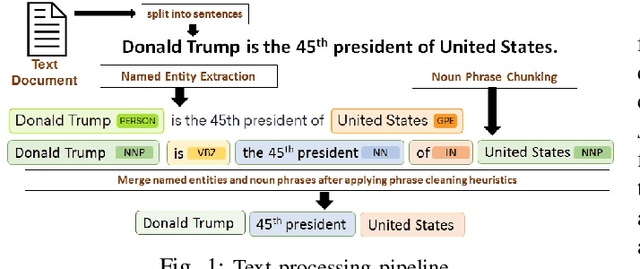
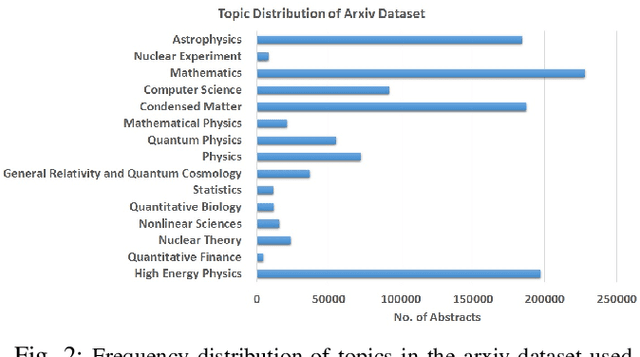


Keyword extraction is a fundamental task in natural language processing that facilitates mapping of documents to a concise set of representative single and multi-word phrases. Keywords from text documents are primarily extracted using supervised and unsupervised approaches. In this paper, we present an unsupervised technique that uses a combination of theme-weighted personalized PageRank algorithm and neural phrase embeddings for extracting and ranking keywords. We also introduce an efficient way of processing text documents and training phrase embeddings using existing techniques. We share an evaluation dataset derived from an existing dataset that is used for choosing the underlying embedding model. The evaluations for ranked keyword extraction are performed on two benchmark datasets comprising of short abstracts (Inspec), and long scientific papers (SemEval 2010), and is shown to produce results better than the state-of-the-art systems.