 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheme-weighted Ranking of Keywords from Text Documents using Phrase Embeddings
Paper and Code
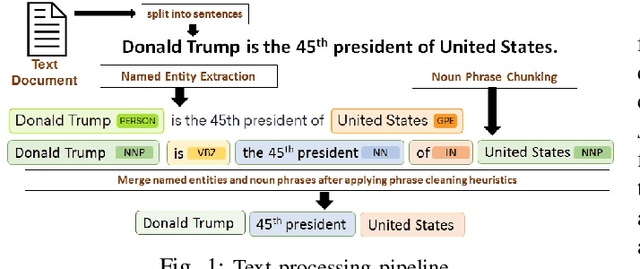


Keyword extraction is a fundamental task in natural language processing that facilitates mapping of documents to a concise set of representative single and multi-word phrases. Keywords from text documents are primarily extracted using supervised and unsupervised approaches. In this paper, we present an unsupervised technique that uses a combination of theme-weighted personalized PageRank algorithm and neural phrase embeddings for extracting and ranking keywords. We also introduce an efficient way of processing text documents and training phrase embeddings using existing techniques. We share an evaluation dataset derived from an existing dataset that is used for choosing the underlying embedding model. The evaluations for ranked keyword extraction are performed on two benchmark datasets comprising of short abstracts (Inspec), and long scientific papers (SemEval 2010), and is shown to produce results better than the state-of-the-art systems.