 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Fourier Neural Operators: Efficient Token Mixers for Transformers
Nov 24, 2021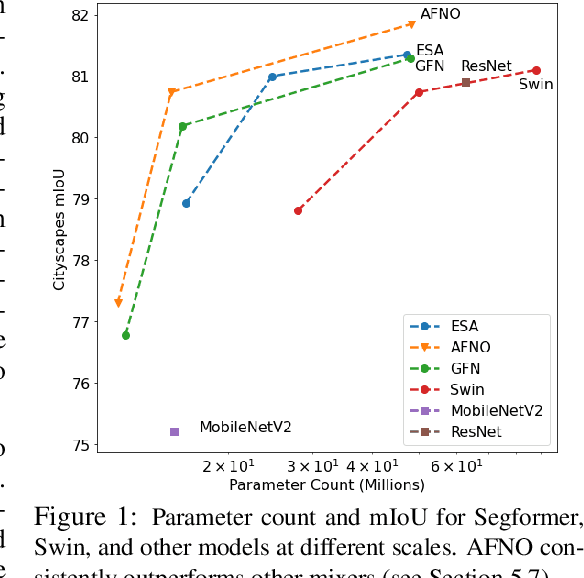

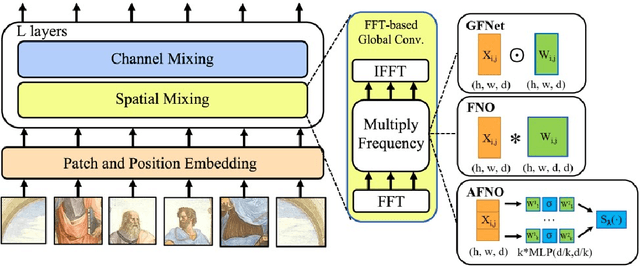

Vision transformers have delivered tremendous success in representation learning. This is primarily due to effective token mixing through self attention. However, this scales quadratically with the number of pixels, which becomes infeasible for high-resolution inputs. To cope with this challenge, we propose Adaptive Fourier Neural Operator (AFNO) as an efficient token mixer that learns to mix in the Fourier domain. AFNO is based on a principled foundation of operator learning which allows us to frame token mixing as a continuous global convolution without any dependence on the input resolution. This principle was previously used to design FNO, which solves global convolution efficiently in the Fourier domain and has shown promise in learning challenging PDEs. To handle challenges in visual representation learning such as discontinuities in images and high resolution inputs, we propose principled architectural modifications to FNO which results in memory and computational efficiency. This includes imposing a block-diagonal structure on the channel mixing weights, adaptively sharing weights across tokens, and sparsifying the frequency modes via soft-thresholding and shrinkage. The resulting model is highly parallel with a quasi-linear complexity and has linear memory in the sequence size. AFNO outperforms self-attention mechanisms for few-shot segmentation in terms of both efficiency and accuracy. For Cityscapes segmentation with the Segformer-B3 backbone, AFNO can handle a sequence size of 65k and outperforms other efficient self-attention mechanisms.
Proof: Accelerating Approximate Aggregation Queries with Expensive Predicates
Jul 28, 2021
Given a dataset $\mathcal{D}$, we are interested in computing the mean of a subset of $\mathcal{D}$ which matches a predicate. ABae leverages stratified sampling and proxy models to efficiently compute this statistic given a sampling budget $N$. In this document, we theoretically analyze ABae and show that the MSE of the estimate decays at rate $O(N_1^{-1} + N_2^{-1} + N_1^{1/2}N_2^{-3/2})$, where $N=K \cdot N_1+N_2$ for some integer constant $K$ and $K \cdot N_1$ and $N_2$ represent the number of samples used in Stage 1 and Stage 2 of ABae respectively. Hence, if a constant fraction of the total sample budget $N$ is allocated to each stage, we will achieve a mean squared error of $O(N^{-1})$ which matches the rate of mean squared error of the optimal stratified sampling algorithm given a priori knowledge of the predicate positive rate and standard deviation per stratum.