 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignScene: Visual Sign Grounding for Mapless Navigation
Feb 13, 2026Navigational signs enable humans to navigate unfamiliar environments without maps. This work studies how robots can similarly exploit signs for mapless navigation in the open world. A central challenge lies in interpreting signs: real-world signs are diverse and complex, and their abstract semantic contents need to be grounded in the local 3D scene. We formalize this as sign grounding, the problem of mapping semantic instructions on signs to corresponding scene elements and navigational actions. Recent Vision-Language Models (VLMs) offer the semantic common-sense and reasoning capabilities required for this task, but are sensitive to how spatial information is represented. We propose SignScene, a sign-centric spatial-semantic representation that captures navigation-relevant scene elements and sign information, and presents them to VLMs in a form conducive to effective reasoning. We evaluate our grounding approach on a dataset of 114 queries collected across nine diverse environment types, achieving 88% grounding accuracy and significantly outperforming baselines. Finally, we demonstrate that it enables real-world mapless navigation on a Spot robot using only signs.
IntentionNet: Map-Lite Visual Navigation at the Kilometre Scale
Jul 03, 2024
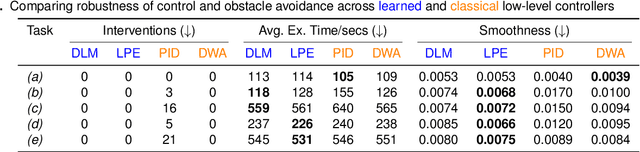
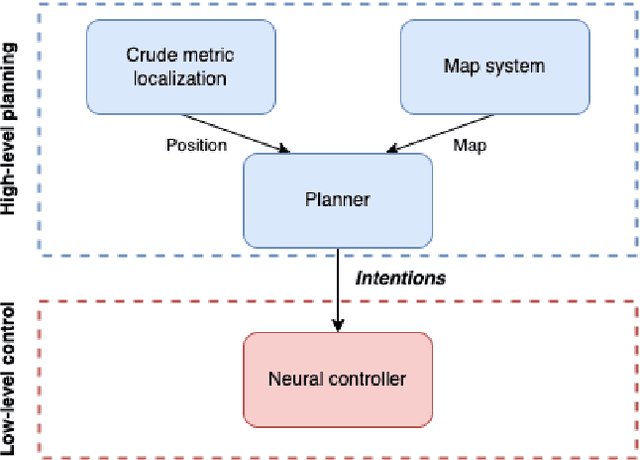

This work explores the challenges of creating a scalable and robust robot navigation system that can traverse both indoor and outdoor environments to reach distant goals. We propose a navigation system architecture called IntentionNet that employs a monolithic neural network as the low-level planner/controller, and uses a general interface that we call intentions to steer the controller. The paper proposes two types of intentions, Local Path and Environment (LPE) and Discretised Local Move (DLM), and shows that DLM is robust to significant metric positioning and mapping errors. The paper also presents Kilo-IntentionNet, an instance of the IntentionNet system using the DLM intention that is deployed on a Boston Dynamics Spot robot, and which successfully navigates through complex indoor and outdoor environments over distances of up to a kilometre with only noisy odometry.
Open Scene Graphs for Open World Object-Goal Navigation
Jul 02, 2024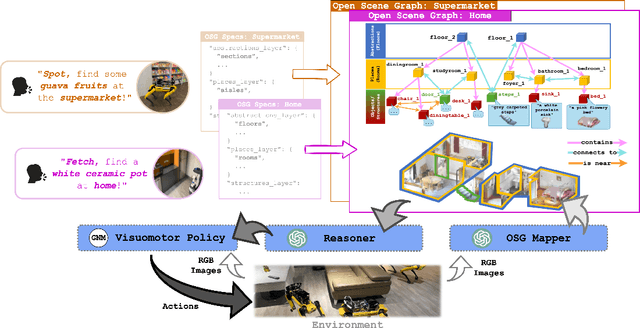
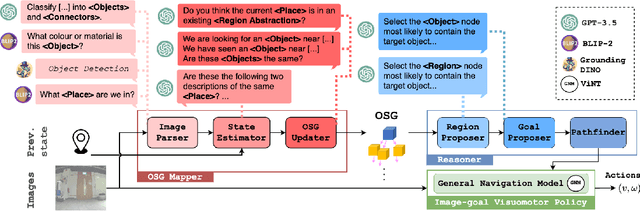
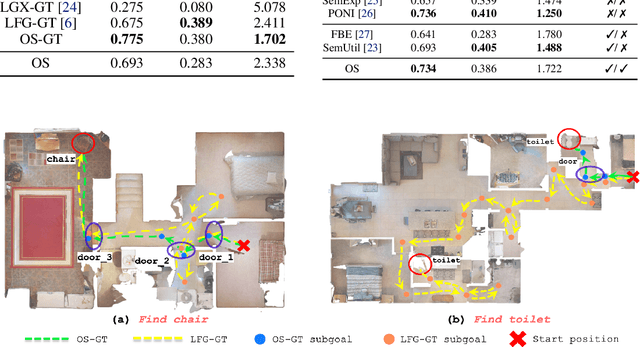

How can we build robots for open-world semantic navigation tasks, like searching for target objects in novel scenes? While foundation models have the rich knowledge and generalisation needed for these tasks, a suitable scene representation is needed to connect them into a complete robot system. We address this with Open Scene Graphs (OSGs), a topo-semantic representation that retains and organises open-set scene information for these models, and has a structure that can be configured for different environment types. We integrate foundation models and OSGs into the OpenSearch system for Open World Object-Goal Navigation, which is capable of searching for open-set objects specified in natural language, while generalising zero-shot across diverse environments and embodiments. Our OSGs enhance reasoning with Large Language Models (LLM), enabling robust object-goal navigation outperforming existing LLM approaches. Through simulation and real-world experiments, we validate OpenSearch's generalisation across varied environments, robots and novel instructions.
Scene Action Maps: Behavioural Maps for Navigation without Metric Information
May 13, 2024Humans are remarkable in their ability to navigate without metric information. We can read abstract 2D maps, such as floor-plans or hand-drawn sketches, and use them to navigate in unseen rich 3D environments, without requiring prior traversals to map out these scenes in detail. We posit that this is enabled by the ability to represent the environment abstractly as interconnected navigational behaviours, e.g., "follow the corridor" or "turn right", while avoiding detailed, accurate spatial information at the metric level. We introduce the Scene Action Map (SAM), a behavioural topological graph, and propose a learnable map-reading method, which parses a variety of 2D maps into SAMs. Map-reading extracts salient information about navigational behaviours from the overlooked wealth of pre-existing, abstract and inaccurate maps, ranging from floor-plans to sketches. We evaluate the performance of SAMs for navigation, by building and deploying a behavioural navigation stack on a quadrupedal robot. Videos and more information is available at: https://scene-action-maps.github.io.