 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNER: A Unified Prediction Head for Named Entity Recognition in Visually-rich Documents
Aug 02, 2024
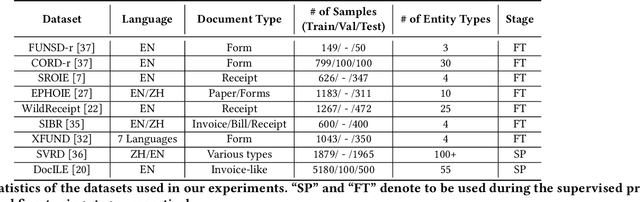

The recognition of named entities in visually-rich documents (VrD-NER) plays a critical role in various real-world scenarios and applications. However, the research in VrD-NER faces three major challenges: complex document layouts, incorrect reading orders, and unsuitable task formulations. To address these challenges, we propose a query-aware entity extraction head, namely UNER, to collaborate with existing multi-modal document transformers to develop more robust VrD-NER models. The UNER head considers the VrD-NER task as a combination of sequence labeling and reading order prediction, effectively addressing the issues of discontinuous entities in documents. Experimental evaluations on diverse datasets demonstrate the effectiveness of UNER in improving entity extraction performance. Moreover, the UNER head enables a supervised pre-training stage on various VrD-NER datasets to enhance the document transformer backbones and exhibits substantial knowledge transfer from the pre-training stage to the fine-tuning stage. By incorporating universal layout understanding, a pre-trained UNER-based model demonstrates significant advantages in few-shot and cross-linguistic scenarios and exhibits zero-shot entity extraction abilities.
Reading Order Matters: Information Extraction from Visually-rich Documents by Token Path Prediction
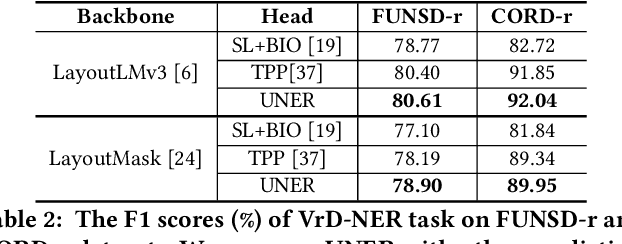
Oct 17, 2023Recent advances in multimodal pre-trained models have significantly improved information extraction from visually-rich documents (VrDs), in which named entity recognition (NER) is treated as a sequence-labeling task of predicting the BIO entity tags for tokens, following the typical setting of NLP. However, BIO-tagging scheme relies on the correct order of model inputs, which is not guaranteed in real-world NER on scanned VrDs where text are recognized and arranged by OCR systems. Such reading order issue hinders the accurate marking of entities by BIO-tagging scheme, making it impossible for sequence-labeling methods to predict correct named entities. To address the reading order issue, we introduce Token Path Prediction (TPP), a simple prediction head to predict entity mentions as token sequences within documents. Alternative to token classification, TPP models the document layout as a complete directed graph of tokens, and predicts token paths within the graph as entities. For better evaluation of VrD-NER systems, we also propose two revised benchmark datasets of NER on scanned documents which can reflect real-world scenarios. Experiment results demonstrate the effectiveness of our method, and suggest its potential to be a universal solution to various information extraction tasks on documents.
LayoutMask: Enhance Text-Layout Interaction in Multi-modal Pre-training for Document Understanding
Jun 09, 2023



Visually-rich Document Understanding (VrDU) has attracted much research attention over the past years. Pre-trained models on a large number of document images with transformer-based backbones have led to significant performance gains in this field. The major challenge is how to fusion the different modalities (text, layout, and image) of the documents in a unified model with different pre-training tasks. This paper focuses on improving text-layout interactions and proposes a novel multi-modal pre-training model, LayoutMask. LayoutMask uses local 1D position, instead of global 1D position, as layout input and has two pre-training objectives: (1) Masked Language Modeling: predicting masked tokens with two novel masking strategies; (2) Masked Position Modeling: predicting masked 2D positions to improve layout representation learning. LayoutMask can enhance the interactions between text and layout modalities in a unified model and produce adaptive and robust multi-modal representations for downstream tasks. Experimental results show that our proposed method can achieve state-of-the-art results on a wide variety of VrDU problems, including form understanding, receipt understanding, and document image classification.