 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNER: A Unified Prediction Head for Named Entity Recognition in Visually-rich Documents
Paper and Code
Aug 02, 2024
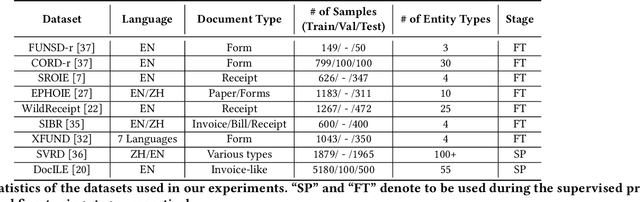

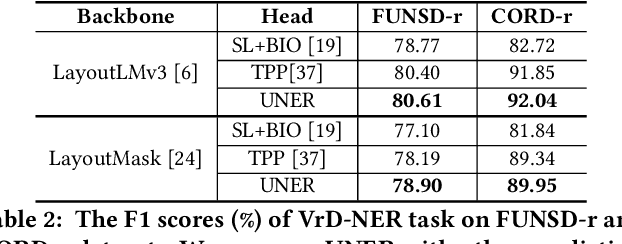
The recognition of named entities in visually-rich documents (VrD-NER) plays a critical role in various real-world scenarios and applications. However, the research in VrD-NER faces three major challenges: complex document layouts, incorrect reading orders, and unsuitable task formulations. To address these challenges, we propose a query-aware entity extraction head, namely UNER, to collaborate with existing multi-modal document transformers to develop more robust VrD-NER models. The UNER head considers the VrD-NER task as a combination of sequence labeling and reading order prediction, effectively addressing the issues of discontinuous entities in documents. Experimental evaluations on diverse datasets demonstrate the effectiveness of UNER in improving entity extraction performance. Moreover, the UNER head enables a supervised pre-training stage on various VrD-NER datasets to enhance the document transformer backbones and exhibits substantial knowledge transfer from the pre-training stage to the fine-tuning stage. By incorporating universal layout understanding, a pre-trained UNER-based model demonstrates significant advantages in few-shot and cross-linguistic scenarios and exhibits zero-shot entity extraction abilities.