 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neyman-Pearson Classification for Prioritizing Severe Disease Categories in COVID-19 Patient Data
Oct 01, 2022

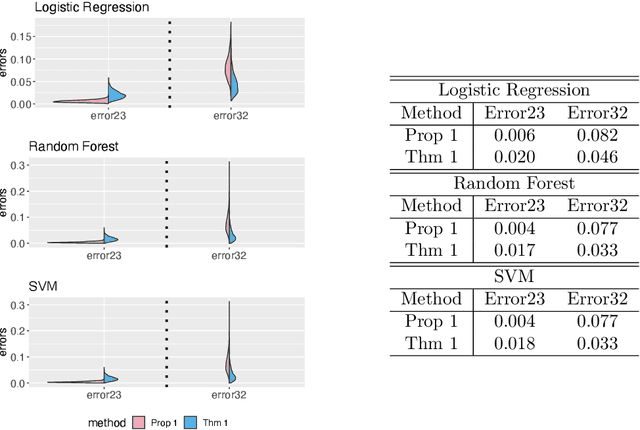
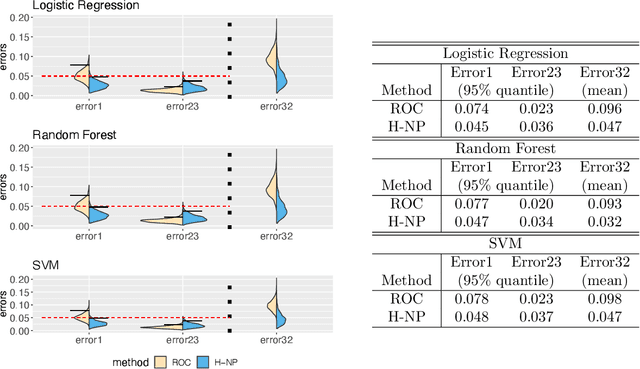
COVID-19 has a spectrum of disease severity, ranging from asymptomatic to requiring hospitalization. Providing appropriate medical care to severe patients is crucial to reduce mortality risks. Hence, in classifying patients into severity categories, the more important classification errors are "under-diagnosis", in which patients are misclassified into less severe categories and thus receive insufficient medical care. The Neyman-Pearson (NP) classification paradigm has been developed to prioritize the designated type of error. However, current NP procedures are either for binary classification or do not provide high probability controls on the prioritized errors in multi-class classification. Here, we propose a hierarchical NP (H-NP) framework and an umbrella algorithm that generally adapts to popular classification methods and controls the under-diagnosis errors with high probability. On an integrated collection of single-cell RNA-seq (scRNA-seq) datasets for 740 patients, we explore ways of featurization and demonstrate the efficacy of the H-NP algorithm in controlling the under-diagnosis errors regardless of featurization. Beyond COVID-19 severity classification, the H-NP algorithm generally applies to multi-class classification problems, where classes have a priority order.
Information-theoretic Classification Accuracy: A Criterion that Guides Data-driven Combination of Ambiguous Outcome Labels in Multi-class Classification
Sep 17, 2021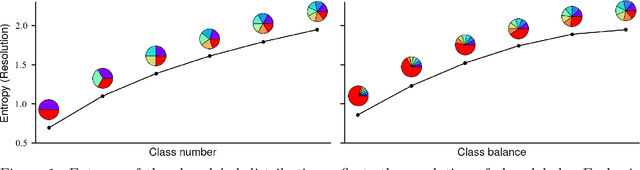
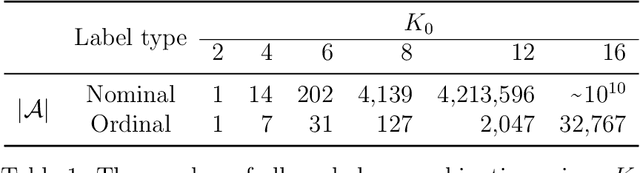
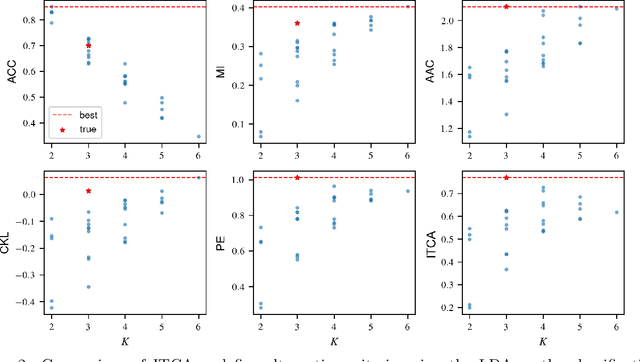
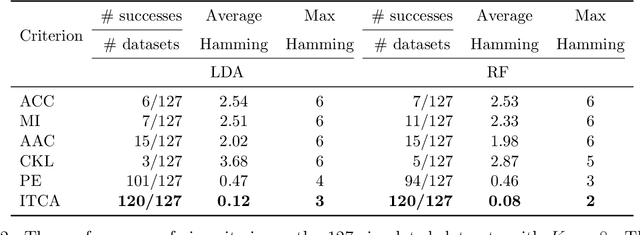
Outcome labeling ambiguity and subjectivity are ubiquitous in real-world datasets. While practitioners commonly combine ambiguous outcome labels in an ad hoc way to improve the accuracy of multi-class classification, there lacks a principled approach to guide label combination by any optimality criterion. To address this problem, we propose the information-theoretic classification accuracy (ITCA), a criterion of outcome "information" conditional on outcome prediction, to guide practitioners on how to combine ambiguous outcome labels. ITCA indicates a balance in the trade-off between prediction accuracy (how well do predicted labels agree with actual labels) and prediction resolution (how many labels are predictable). To find the optimal label combination indicated by ITCA, we develop two search strategies: greedy search and breadth-first search. Notably, ITCA and the two search strategies are adaptive to all machine-learning classification algorithms. Coupled with a classification algorithm and a search strategy, ITCA has two uses: to improve prediction accuracy and to identify ambiguous labels. We first verify that ITCA achieves high accuracy with both search strategies in finding the correct label combinations on synthetic and real data. Then we demonstrate the effectiveness of ITCA in diverse applications including medical prognosis, cancer survival prediction, user demographics prediction, and cell type classification.
Bridging Cost-sensitive and Neyman-Pearson Paradigms for Asymmetric Binary Classification
Dec 29, 2020
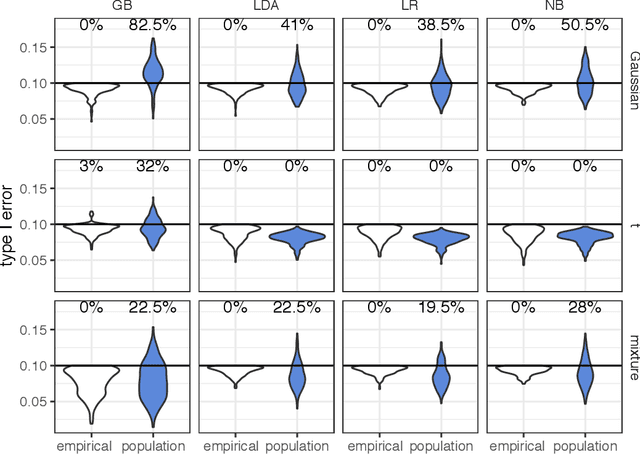
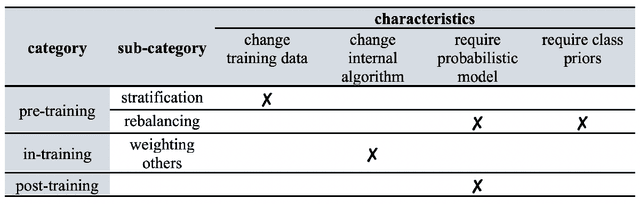
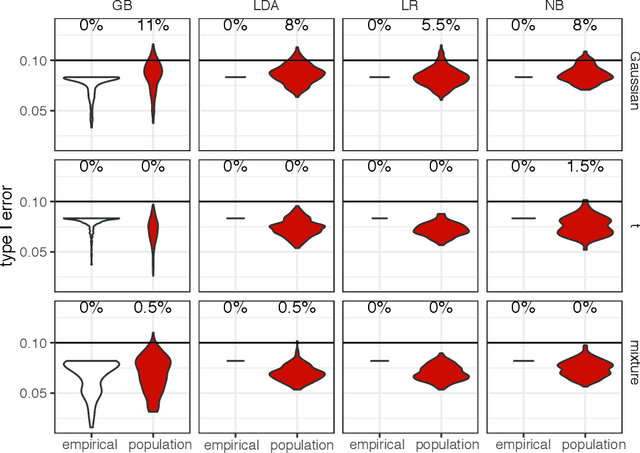
Asymmetric binary classification problems, in which the type I and II errors have unequal severity, are ubiquitous in real-world applications. To handle such asymmetry, researchers have developed the cost-sensitive and Neyman-Pearson paradigms for training classifiers to control the more severe type of classification error, say the type I error. The cost-sensitive paradigm is widely used and has straightforward implementations that do not require sample splitting; however, it demands an explicit specification of the costs of the type I and II errors, and an open question is what specification can guarantee a high-probability control on the population type I error. In contrast, the Neyman-Pearson paradigm can train classifiers to achieve a high-probability control of the population type I error, but it relies on sample splitting that reduces the effective training sample size. Since the two paradigms have complementary strengths, it is reasonable to combine their strengths for classifier construction. In this work, we for the first time study the methodological connections between the two paradigms, and we develop the TUBE-CS algorithm to bridge the two paradigms from the perspective of controlling the population type I error.
Matched bipartite block model with covariates
Mar 15, 2017



Community detection or clustering is a fundamental task in the analysis of network data. Many real networks have a bipartite structure which makes community detection challenging. In this paper, we consider a model which allows for matched communities in the bipartite setting, in addition to node covariates with information about the matching. We derive a simple fast algorithm for fitting the model based on variational inference ideas and show its effectiveness on both simulated and real data. A variation of the model to allow for degree-correction is also considered, in addition to a novel approach to fitting such degree-corrected models.