 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcentration of kernel matrices with application to kernel spectral clustering
Sep 07, 2019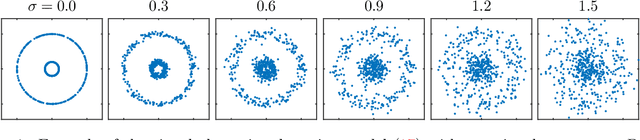
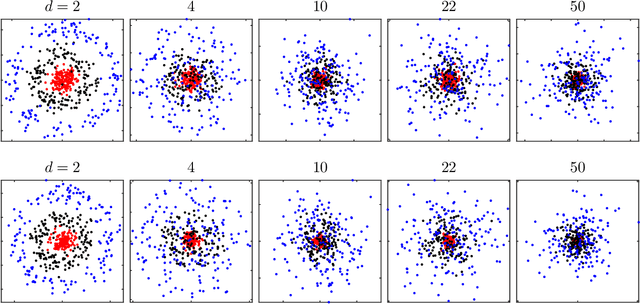
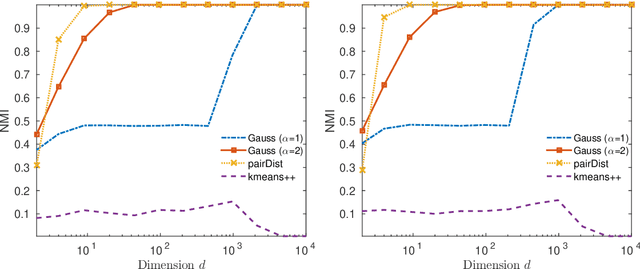
We study the concentration of random kernel matrices around their mean. We derive nonasymptotic exponential concentration inequalities for Lipschitz kernels assuming that the data points are independent draws from a class of multivariate distributions on $\mathbb{R}^d$, including the strongly log-concave distributions under affine transformations. A feature of our result is that the data points need not have identical distributions or have zero mean, which is key in certain applications such as clustering. For comparison, we also derive the companion result for the Euclidean (inner product) kernel under a slightly modified set of distributional assumptions, more precisely, a class of sub-Gaussian vectors. A notable difference between the two cases is that, in contrast to the Euclidean kernel, in the Lipschitz case, the concentration inequality does not depend on the mean of the underlying vectors. As an application of these inequalities, we derive a bound on the misclassification rate of a kernel spectral clustering (KSC) algorithm, under a perturbed nonparametric mixture model. We show an example where this bound establishes the high-dimensional consistency (as $d \to \infty$) of the KSC, when applied with a Gaussian kernel, to a signal consisting of nested nonlinear manifolds (e.g., spheres) plus noise.
Exact slice sampler for Hierarchical Dirichlet Processes
Mar 21, 2019


We propose an exact slice sampler for Hierarchical Dirichlet process (HDP) and its associated mixture models (Teh et al., 2006). Although there are existing MCMC algorithms for sampling from the HDP, a slice sampler has been missing from the literature. Slice sampling is well-known for its desirable properties including its fast mixing and its natural potential for parallelization. On the other hand, the hierarchical nature of HDPs poses challenges to adopting a full-fledged slice sampler that automatically truncates all the infinite measures involved without ad-hoc modifications. In this work, we adopt the powerful idea of Bayesian variable augmentation to address this challenge. By introducing new latent variables, we obtain a full factorization of the joint distribution that is suitable for slice sampling. Our algorithm has several appealing features such as (1) fast mixing; (2) remaining exact while allowing natural truncation of the underlying infinite-dimensional measures, as in (Kalli et al., 2011), resulting in updates of only a finite number of necessary atoms and weights in each iteration; and (3) being naturally suited to parallel implementations. The underlying principle for joint factorization of the full likelihood is simple and can be applied to many other settings, such as designing sampling algorithms for general dependent Dirichlet process (DDP) models.
Matched bipartite block model with covariates
Mar 15, 2017



Community detection or clustering is a fundamental task in the analysis of network data. Many real networks have a bipartite structure which makes community detection challenging. In this paper, we consider a model which allows for matched communities in the bipartite setting, in addition to node covariates with information about the matching. We derive a simple fast algorithm for fitting the model based on variational inference ideas and show its effectiveness on both simulated and real data. A variation of the model to allow for degree-correction is also considered, in addition to a novel approach to fitting such degree-corrected models.
A Fuzzy Clustering Model for Fuzzy Data with Outliers
Nov 18, 2010
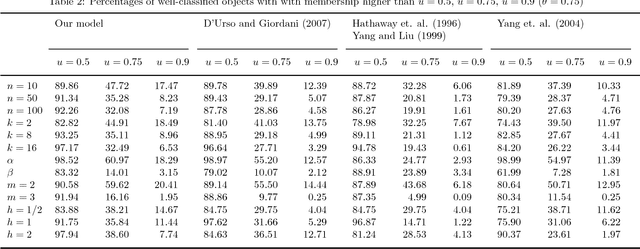


In this paper a fuzzy clustering model for fuzzy data with outliers is proposed. The model is based on Wasserstein distance between interval valued data which is generalized to fuzzy data. In addition, Keller's approach is used to identify outliers and reduce their influences. We have also defined a transformation to change our distance to the Euclidean distance. With the help of this approach, the problem of fuzzy clustering of fuzzy data is reduced to fuzzy clustering of crisp data. In order to show the performance of the proposed clustering algorithm, two simulation experiments are discussed.