 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced 3D Gravity Inversion Using ResU-Net with Density Logging Constraints: A Dual-Phase Training Approach
Jan 06, 2026Gravity exploration has become an important geophysical method due to its low cost and high efficiency. With the rise of artificial intelligence, data-driven gravity inversion methods based on deep learning (DL) possess physical property recovery capabilities that conventional regularization methods lack. However, existing DL methods suffer from insufficient prior information constraints, which leads to inversion models with large data fitting errors and unreliable results. Moreover, the inversion results lack constraints and matching from other exploration methods, leading to results that may contradict known geological conditions. In this study, we propose a novel approach that integrates prior density well logging information to address the above issues. First, we introduce a depth weighting function to the neural network (NN) and train it in the weighted density parameter domain. The NN, under the constraint of the weighted forward operator, demonstrates improved inversion performance, with the resulting inversion model exhibiting smaller data fitting errors. Next, we divide the entire network training into two phases: first training a large pre-trained network Net-I, and then using the density logging information as the constraint to get the optimized fine-tuning network Net-II. Through testing and comparison in synthetic models and Bishop Model, the inversion quality of our method has significantly improved compared to the unconstrained data-driven DL inversion method. Additionally, we also conduct a comparison and discussion between our method and both the conventional focusing inversion (FI) method and its well logging constrained variant. Finally, we apply this method to the measured data from the San Nicolas mining area in Mexico, comparing and analyzing it with two recent gravity inversion methods based on DL.
Seismic Acoustic Impedance Inversion Framework Based on Conditional Latent Generative Diffusion Model
Jun 16, 2025Seismic acoustic impedance plays a crucial role in lithological identification and subsurface structure interpretation. However, due to the inherently ill-posed nature of the inversion problem, directly estimating impedance from post-stack seismic data remains highly challenging. Recently, diffusion models have shown great potential in addressing such inverse problems due to their strong prior learning and generative capabilities. Nevertheless, most existing methods operate in the pixel domain and require multiple iterations, limiting their applicability to field data. To alleviate these limitations, we propose a novel seismic acoustic impedance inversion framework based on a conditional latent generative diffusion model, where the inversion process is made in latent space. To avoid introducing additional training overhead when embedding conditional inputs, we design a lightweight wavelet-based module into the framework to project seismic data and reuse an encoder trained on impedance to embed low-frequency impedance into the latent space. Furthermore, we propose a model-driven sampling strategy during the inversion process of this framework to enhance accuracy and reduce the number of required diffusion steps. Numerical experiments on a synthetic model demonstrate that the proposed method achieves high inversion accuracy and strong generalization capability within only a few diffusion steps. Moreover, application to field data reveals enhanced geological detail and higher consistency with well-log measurements, validating the effectiveness and practicality of the proposed approach.
High-resolution chirplet transform: from parameters analysis to parameters combination
Aug 02, 2021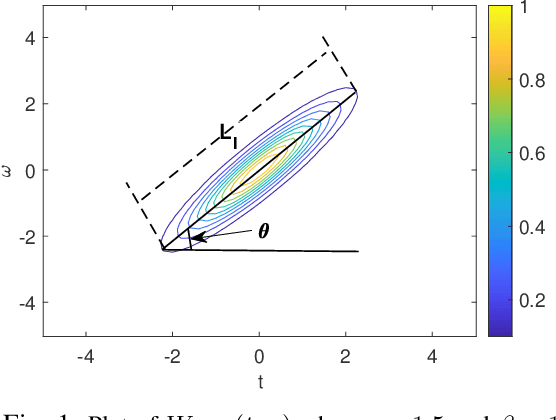
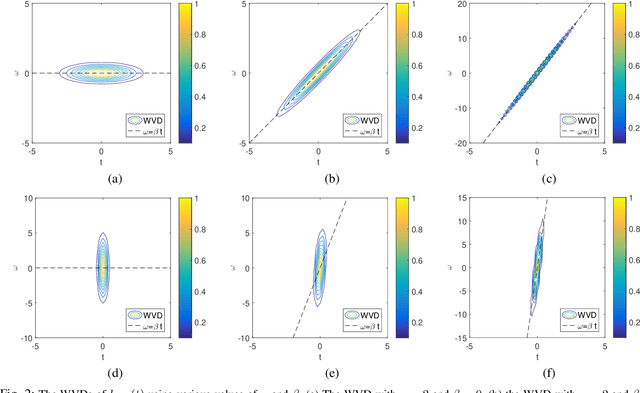
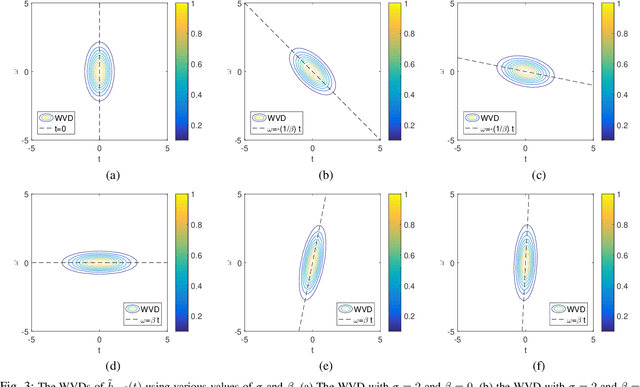
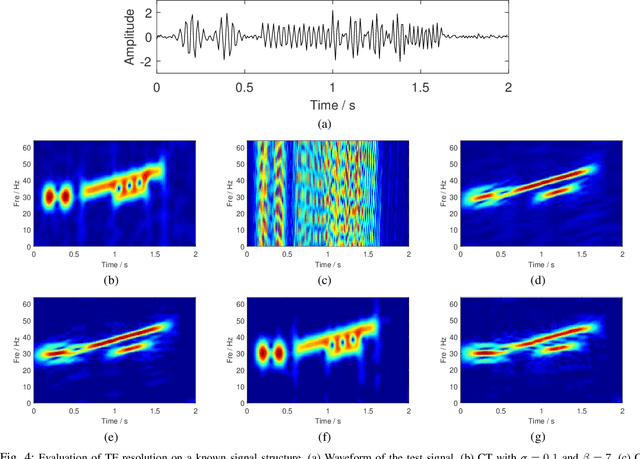
The standard chirplet transform (CT) with a chirp-modulated Gaussian window provides a valuable tool for analyzing linear chirp signals. The parameters present in the window determine the performance of CT and play a very important role in high-resolution time-frequency (TF) analysis. In this paper, we first give the window shape analysis of CT and compare it with the extension that employs a rotating Gaussian window by fractional Fourier transform. The given parameters analysis provides certain theoretical guidance for developing high-resolution CT. We then propose a multi-resolution chirplet transform (MrCT) by combining multiple CTs with different parameter combinations. These are combined geometrically to obtain an improved TF resolution by overcoming the limitations of any single representation of the CT. By deriving the combined instantaneous frequency equation, we further develop a high-concentration TF post-processing approach to improve the readability of the MrCT. Numerical experiments on simulated and real signals verify its effectiveness.