 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fixed Grid: Learning Geometric Image Representation with a Deformable Grid
Aug 21, 2020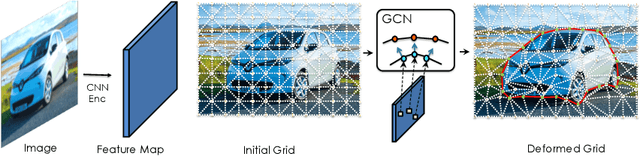



In modern computer vision, images are typically represented as a fixed uniform grid with some stride and processed via a deep convolutional neural network. We argue that deforming the grid to better align with the high-frequency image content is a more effective strategy. We introduce \emph{Deformable Grid} DefGrid, a learnable neural network module that predicts location offsets of vertices of a 2-dimensional triangular grid, such that the edges of the deformed grid align with image boundaries. We showcase our DefGrid in a variety of use cases, i.e., by inserting it as a module at various levels of processing. We utilize DefGrid as an end-to-end \emph{learnable geometric downsampling} layer that replaces standard pooling methods for reducing feature resolution when feeding images into a deep CNN. We show significantly improved results at the same grid resolution compared to using CNNs on uniform grids for the task of semantic segmentation. We also utilize DefGrid at the output layers for the task of object mask annotation, and show that reasoning about object boundaries on our predicted polygonal grid leads to more accurate results over existing pixel-wise and curve-based approaches. We finally showcase DefGrid as a standalone module for unsupervised image partitioning, showing superior performance over existing approaches. Project website: http://www.cs.toronto.edu/~jungao/def-grid
On the Anomalous Generalization of GANs
Oct 06, 2019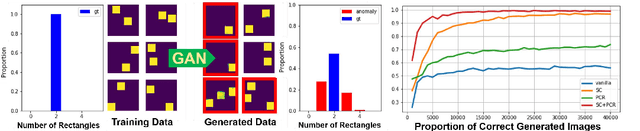
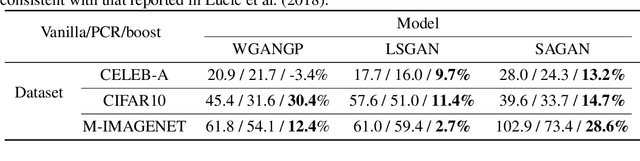
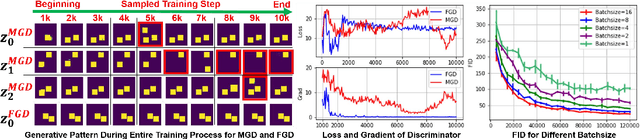
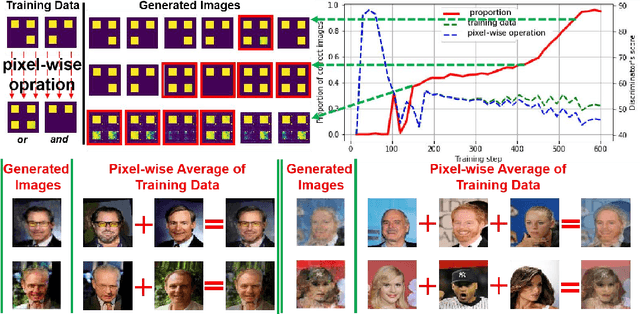
Generative models, especially Generative Adversarial Networks (GANs), have received significant attention recently. However, it has been observed that in terms of some attributes, e.g. the number of simple geometric primitives in an image, GANs are not able to learn the target distribution in practice. Motivated by this observation, we discover two specific problems of GANs leading to anomalous generalization behaviour, which we refer to as the sample insufficiency and the pixel-wise combination. For the first problem of sample insufficiency, we show theoretically and empirically that the batchsize of the training samples in practice may be insufficient for the discriminator to learn an accurate discrimination function. It could result in unstable training dynamics for the generator, leading to anomalous generalization. For the second problem of pixel-wise combination, we find that besides recognizing the positive training samples as real, under certain circumstances, the discriminator could be fooled to recognize the pixel-wise combinations (e.g. pixel-wise average) of the positive training samples as real. However, those combinations could be visually different from the real samples in the target distribution. With the fooled discriminator as reference, the generator would obtain biased supervision further, leading to the anomalous generalization behaviour. Additionally, in this paper, we propose methods to mitigate the anomalous generalization of GANs. Extensive experiments on benchmark show our proposed methods improve the FID score up to 30\% on natural image dataset.