 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive LoRA Experts Allocation and Selection for Federated Fine-Tuning
Sep 18, 2025Large Language Models (LLMs) have demonstrated impressive capabilities across various tasks, but fine-tuning them for domain-specific applications often requires substantial domain-specific data that may be distributed across multiple organizations. Federated Learning (FL) offers a privacy-preserving solution, but faces challenges with computational constraints when applied to LLMs. Low-Rank Adaptation (LoRA) has emerged as a parameter-efficient fine-tuning approach, though a single LoRA module often struggles with heterogeneous data across diverse domains. This paper addresses two critical challenges in federated LoRA fine-tuning: 1. determining the optimal number and allocation of LoRA experts across heterogeneous clients, and 2. enabling clients to selectively utilize these experts based on their specific data characteristics. We propose FedLEASE (Federated adaptive LoRA Expert Allocation and SElection), a novel framework that adaptively clusters clients based on representation similarity to allocate and train domain-specific LoRA experts. It also introduces an adaptive top-$M$ Mixture-of-Experts mechanism that allows each client to select the optimal number of utilized experts. Our extensive experiments on diverse benchmark datasets demonstrate that FedLEASE significantly outperforms existing federated fine-tuning approaches in heterogeneous client settings while maintaining communication efficiency.
Multimodal Federated Learning: A Survey through the Lens of Different FL Paradigms
May 27, 2025Multimodal Federated Learning (MFL) lies at the intersection of two pivotal research areas: leveraging complementary information from multiple modalities to improve downstream inference performance and enabling distributed training to enhance efficiency and preserve privacy. Despite the growing interest in MFL, there is currently no comprehensive taxonomy that organizes MFL through the lens of different Federated Learning (FL) paradigms. This perspective is important because multimodal data introduces distinct challenges across various FL settings. These challenges, including modality heterogeneity, privacy heterogeneity, and communication inefficiency, are fundamentally different from those encountered in traditional unimodal or non-FL scenarios. In this paper, we systematically examine MFL within the context of three major FL paradigms: horizontal FL (HFL), vertical FL (VFL), and hybrid FL. For each paradigm, we present the problem formulation, review representative training algorithms, and highlight the most prominent challenge introduced by multimodal data in distributed settings. We also discuss open challenges and provide insights for future research. By establishing this taxonomy, we aim to uncover the novel challenges posed by multimodal data from the perspective of different FL paradigms and to offer a new lens through which to understand and advance the development of MFL.
A Survey on Parameter-Efficient Fine-Tuning for Foundation Models in Federated Learning
Apr 29, 2025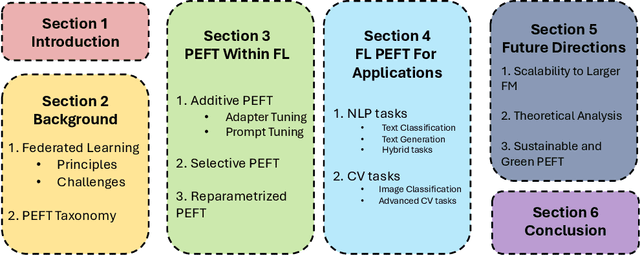
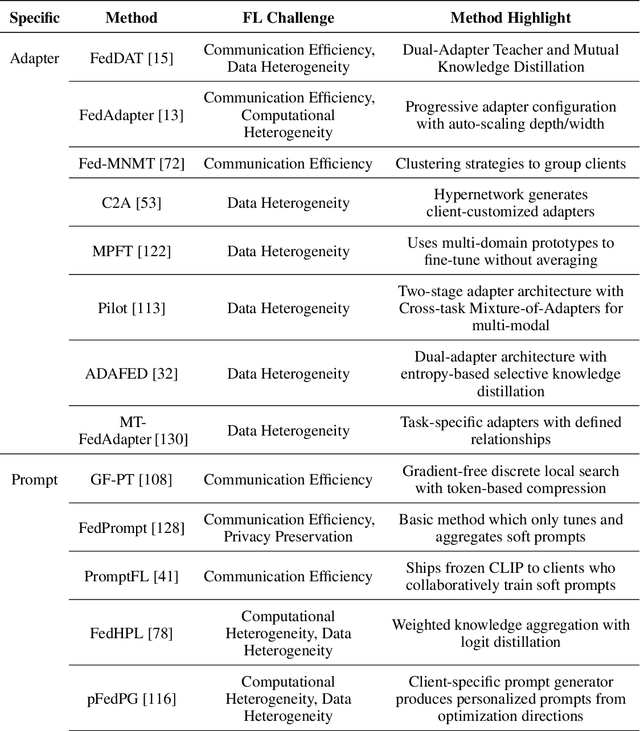
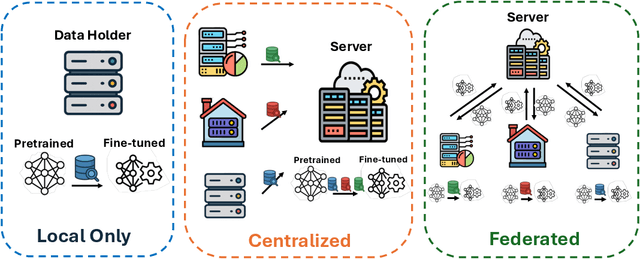
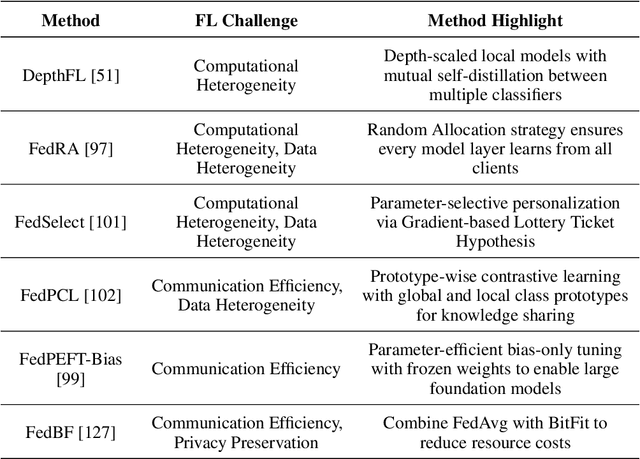
Foundation models have revolutionized artificial intelligence by providing robust, versatile architectures pre-trained on large-scale datasets. However, adapting these massive models to specific downstream tasks requires fine-tuning, which can be prohibitively expensive in computational resources. Parameter-Efficient Fine-Tuning (PEFT) methods address this challenge by selectively updating only a small subset of parameters. Meanwhile, Federated Learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it ideal for privacy-sensitive applications. This survey provides a comprehensive review of the integration of PEFT techniques within federated learning environments. We systematically categorize existing approaches into three main groups: Additive PEFT (which introduces new trainable parameters), Selective PEFT (which fine-tunes only subsets of existing parameters), and Reparameterized PEFT (which transforms model architectures to enable efficient updates). For each category, we analyze how these methods address the unique challenges of federated settings, including data heterogeneity, communication efficiency, computational constraints, and privacy concerns. We further organize the literature based on application domains, covering both natural language processing and computer vision tasks. Finally, we discuss promising research directions, including scaling to larger foundation models, theoretical analysis of federated PEFT methods, and sustainable approaches for resource-constrained environments.
FedALT: Federated Fine-Tuning through Adaptive Local Training with Rest-of-the-World LoRA
Mar 14, 2025Fine-tuning large language models (LLMs) in federated settings enables privacy-preserving adaptation but suffers from cross-client interference due to model aggregation. Existing federated LoRA fine-tuning methods, primarily based on FedAvg, struggle with data heterogeneity, leading to harmful cross-client interference and suboptimal personalization. In this work, we propose \textbf{FedALT}, a novel personalized federated LoRA fine-tuning algorithm that fundamentally departs from FedAvg. Instead of using an aggregated model to initialize local training, each client continues training its individual LoRA while incorporating shared knowledge through a separate Rest-of-the-World (RoTW) LoRA component. To effectively balance local adaptation and global information, FedALT introduces an adaptive mixer that dynamically learns input-specific weightings between the individual and RoTW LoRA components using the Mixture-of-Experts (MoE) principle. Through extensive experiments on NLP benchmarks, we demonstrate that FedALT significantly outperforms state-of-the-art personalized federated LoRA fine-tuning methods, achieving superior local adaptation without sacrificing computational efficiency.
LoRA-FAIR: Federated LoRA Fine-Tuning with Aggregation and Initialization Refinement
Nov 22, 2024



Foundation models (FMs) achieve strong performance across diverse tasks with task-specific fine-tuning, yet full parameter fine-tuning is often computationally prohibitive for large models. Parameter-efficient fine-tuning (PEFT) methods like Low-Rank Adaptation (LoRA) reduce this cost by introducing low-rank matrices for tuning fewer parameters. While LoRA allows for efficient fine-tuning, it requires significant data for adaptation, making Federated Learning (FL) an appealing solution due to its privacy-preserving collaborative framework. However, combining LoRA with FL introduces two key challenges: the \textbf{Server-Side LoRA Aggregation Bias}, where server-side averaging of LoRA matrices diverges from the ideal global update, and the \textbf{Client-Side LoRA Initialization Drift}, emphasizing the need for consistent initialization across rounds. Existing approaches address these challenges individually, limiting their effectiveness. We propose LoRA-FAIR, a novel method that tackles both issues by introducing a correction term on the server while keeping the original LoRA modules, enhancing aggregation efficiency and accuracy. LoRA-FAIR maintains computational and communication efficiency, yielding superior performance over state-of-the-art methods. Experimental results on ViT and MLP-Mixer models across large-scale datasets demonstrate that LoRA-FAIR consistently achieves performance improvements in FL settings.
Prioritizing Modalities: Flexible Importance Scheduling in Federated Multimodal Learning
Aug 13, 2024Federated Learning (FL) is a distributed machine learning approach that enables devices to collaboratively train models without sharing their local data, ensuring user privacy and scalability. However, applying FL to real-world data presents challenges, particularly as most existing FL research focuses on unimodal data. Multimodal Federated Learning (MFL) has emerged to address these challenges, leveraging modality-specific encoder models to process diverse datasets. Current MFL methods often uniformly allocate computational frequencies across all modalities, which is inefficient for IoT devices with limited resources. In this paper, we propose FlexMod, a novel approach to enhance computational efficiency in MFL by adaptively allocating training resources for each modality encoder based on their importance and training requirements. We employ prototype learning to assess the quality of modality encoders, use Shapley values to quantify the importance of each modality, and adopt the Deep Deterministic Policy Gradient (DDPG) method from deep reinforcement learning to optimize the allocation of training resources. Our method prioritizes critical modalities, optimizing model performance and resource utilization. Experimental results on three real-world datasets demonstrate that our proposed method significantly improves the performance of MFL models.
Computation and Communication Efficient Lightweighting Vertical Federated Learning
Mar 30, 2024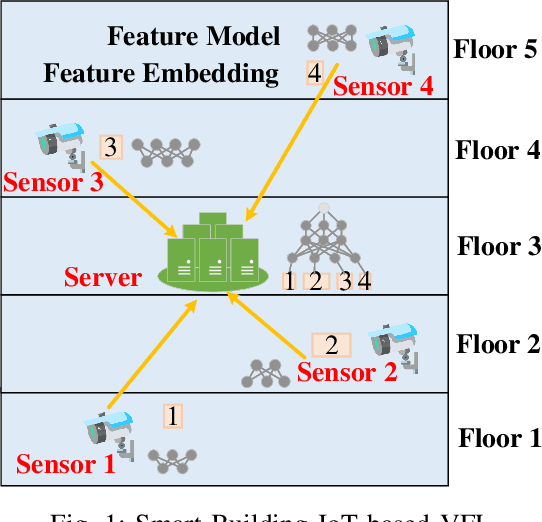
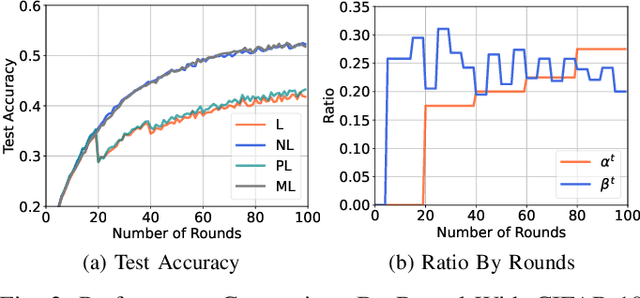
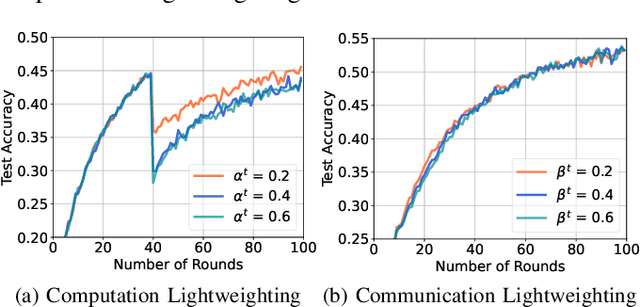
The exploration of computational and communication efficiency within Federated Learning (FL) has emerged as a prominent and crucial field of study. While most existing efforts to enhance these efficiencies have focused on Horizontal FL, the distinct processes and model structures of Vertical FL preclude the direct application of Horizontal FL-based techniques. In response, we introduce the concept of Lightweight Vertical Federated Learning (LVFL), targeting both computational and communication efficiencies. This approach involves separate lightweighting strategies for the feature model, to improve computational efficiency, and for feature embedding, to enhance communication efficiency. Moreover, we establish a convergence bound for our LVFL algorithm, which accounts for both communication and computational lightweighting ratios. Our evaluation of the algorithm on a image classification dataset reveals that LVFL significantly alleviates computational and communication demands while preserving robust learning performance. This work effectively addresses the gaps in communication and computational efficiency within Vertical FL.
Taming Cross-Domain Representation Variance in Federated Prototype Learning with Heterogeneous Data Domains
Mar 14, 2024



Federated learning (FL) allows collaborative machine learning training without sharing private data. While most FL methods assume identical data domains across clients, real-world scenarios often involve heterogeneous data domains. Federated Prototype Learning (FedPL) addresses this issue, using mean feature vectors as prototypes to enhance model generalization. However, existing FedPL methods create the same number of prototypes for each client, leading to cross-domain performance gaps and disparities for clients with varied data distributions. To mitigate cross-domain feature representation variance, we introduce FedPLVM, which establishes variance-aware dual-level prototypes clustering and employs a novel $\alpha$-sparsity prototype loss. The dual-level prototypes clustering strategy creates local clustered prototypes based on private data features, then performs global prototypes clustering to reduce communication complexity and preserve local data privacy. The $\alpha$-sparsity prototype loss aligns samples from underrepresented domains, enhancing intra-class similarity and reducing inter-class similarity. Evaluations on Digit-5, Office-10, and DomainNet datasets demonstrate our method's superiority over existing approaches.
FedMM: Federated Multi-Modal Learning with Modality Heterogeneity in Computational Pathology
Feb 24, 2024The fusion of complementary multimodal information is crucial in computational pathology for accurate diagnostics. However, existing multimodal learning approaches necessitate access to users' raw data, posing substantial privacy risks. While Federated Learning (FL) serves as a privacy-preserving alternative, it falls short in addressing the challenges posed by heterogeneous (yet possibly overlapped) modalities data across various hospitals. To bridge this gap, we propose a Federated Multi-Modal (FedMM) learning framework that federatedly trains multiple single-modal feature extractors to enhance subsequent classification performance instead of existing FL that aims to train a unified multimodal fusion model. Any participating hospital, even with small-scale datasets or limited devices, can leverage these federated trained extractors to perform local downstream tasks (e.g., classification) while ensuring data privacy. Through comprehensive evaluations of two publicly available datasets, we demonstrate that FedMM notably outperforms two baselines in accuracy and AUC metrics.
Federated Learning with Instance-Dependent Noisy Labels
Dec 30, 2023Federated learning (FL) with noisy labels poses a significant challenge. Existing methods designed for handling noisy labels in centralized learning tend to lose their effectiveness in the FL setting, mainly due to the small dataset size and the heterogeneity of client data. While some attempts have been made to tackle FL with noisy labels, they primarily focused on scenarios involving class-conditional noise. In this paper, we study the more challenging and practical issue of instance-dependent noise (IDN) in FL. We introduce a novel algorithm called FedBeat (Federated Learning with Bayesian Ensemble-Assisted Transition Matrix Estimation). FedBeat aims to build a global statistically consistent classifier using the IDN transition matrix (IDNTM), which encompasses three synergistic steps: (1) A federated data extraction step that constructs a weak global model and extracts high-confidence data using a Bayesian model ensemble method. (2) A federated transition matrix estimation step in which clients collaboratively train an IDNTM estimation network based on the extracted data. (3) A federated classifier correction step that enhances the global model's performance by training it using a loss function tailored for noisy labels, leveraging the IDNTM. Experiments conducted on CIFAR-10 and SVHN verify that the proposed method significantly outperforms state-of-the-art methods.