 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Heterogeneous Graph Attention Networks
Dec 31, 2025Real-world graphs or networks are usually heterogeneous, involving multiple types of nodes and relationships. Heterogeneous graph neural networks (HGNNs) can effectively handle these diverse nodes and edges, capturing heterogeneous information within the graph, thus exhibiting outstanding performance. However, most methods of HGNNs usually involve complex structural designs, leading to problems such as high memory usage, long inference time, and extensive consumption of computing resources. These limitations pose certain challenges for the practical application of HGNNs, especially for resource-constrained devices. To mitigate this issue, we propose the Spiking Heterogeneous Graph Attention Networks (SpikingHAN), which incorporates the brain-inspired and energy-saving properties of Spiking Neural Networks (SNNs) into heterogeneous graph learning to reduce the computing cost without compromising the performance. Specifically, SpikingHAN aggregates metapath-based neighbor information using a single-layer graph convolution with shared parameters. It then employs a semantic-level attention mechanism to capture the importance of different meta-paths and performs semantic aggregation. Finally, it encodes the heterogeneous information into a spike sequence through SNNs, simulating bioinformatic processing to derive a binarized 1-bit representation of the heterogeneous graph. Comprehensive experimental results from three real-world heterogeneous graph datasets show that SpikingHAN delivers competitive node classification performance. It achieves this with fewer parameters, quicker inference, reduced memory usage, and lower energy consumption. Code is available at https://github.com/QianPeng369/SpikingHAN.
Nonconvex ${L_ {1/2}} $-Regularized Nonlocal Self-similarity Denoiser for Compressive Sensing based CT Reconstruction
May 15, 2022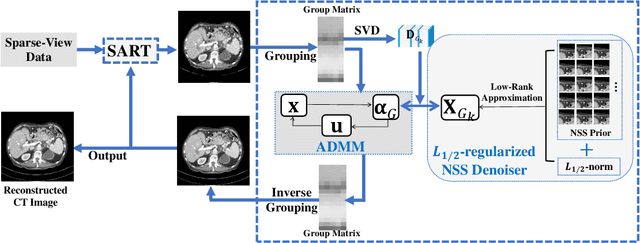
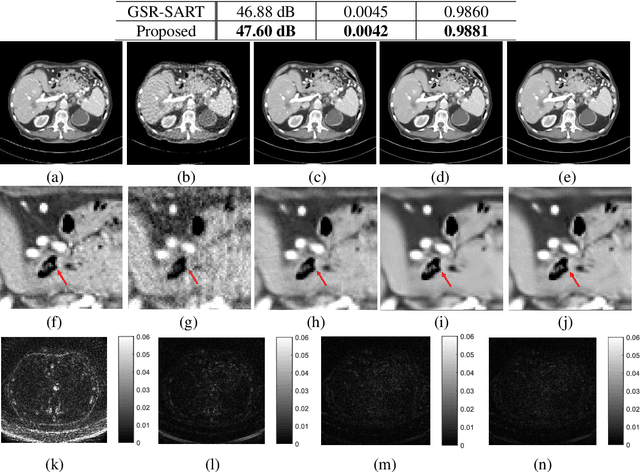
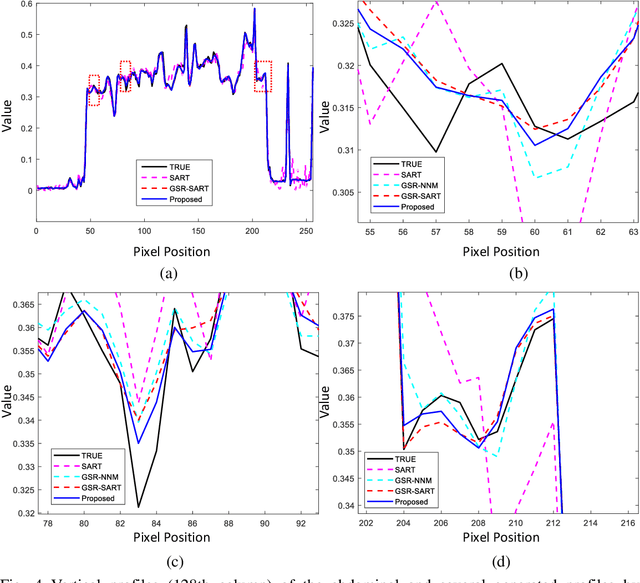
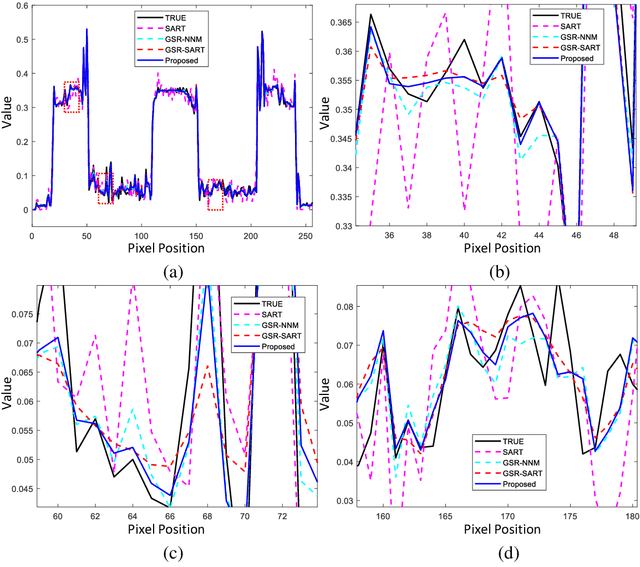
Compressive sensing (CS) based computed tomography (CT) image reconstruction aims at reducing the radiation risk through sparse-view projection data. It is usually challenging to achieve satisfying image quality from incomplete projections. Recently, the nonconvex ${{L_ {{1/2}}}} $-norm has achieved promising performance in sparse recovery, while the applications on imaging are unsatisfactory due to its nonconvexity. In this paper, we develop a ${{L_ {{1/2}}}} $-regularized nonlocal self-similarity (NSS) denoiser for CT reconstruction problem, which integrates low-rank approximation with group sparse coding (GSC) framework. Concretely, we first split the CT reconstruction problem into two subproblems, and then improve the CT image quality furtherly using our ${{L_ {{1/2}}}} $-regularized NSS denoiser. Instead of optimizing the nonconvex problem under the perspective of GSC, we particularly reconstruct CT image via low-rank minimization based on two simple yet essential schemes, which build the equivalent relationship between GSC based denoiser and low-rank minimization. Furtherly, the weighted singular value thresholding (WSVT) operator is utilized to optimize the resulting nonconvex ${{L_ {{1/2}}}} $ minimization problem. Following this, our proposed denoiser is integrated with the CT reconstruction problem by alternating direction method of multipliers (ADMM) framework. Extensive experimental results on typical clinical CT images have demonstrated that our approach can further achieve better performance than popular approaches.
Evolutionary Architecture Search for Graph Neural Networks
Sep 21, 2020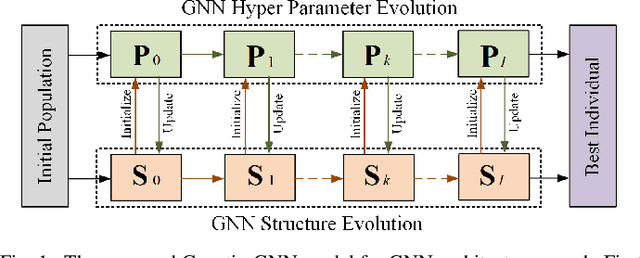
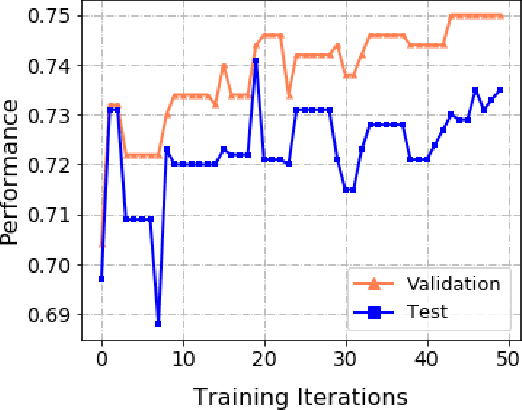
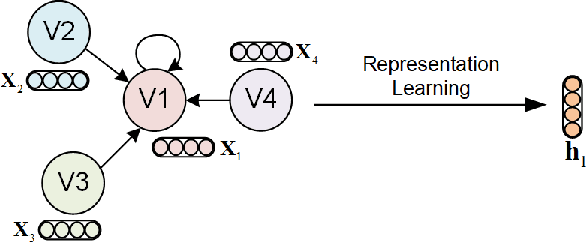
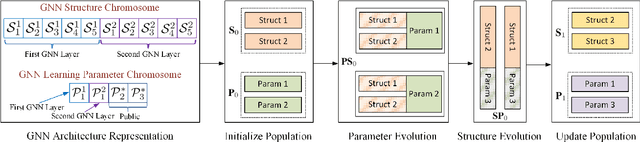
Automated machine learning (AutoML) has seen a resurgence in interest with the boom of deep learning over the past decade. In particular, Neural Architecture Search (NAS) has seen significant attention throughout the AutoML research community, and has pushed forward the state-of-the-art in a number of neural models to address grid-like data such as texts and images. However, very litter work has been done about Graph Neural Networks (GNN) learning on unstructured network data. Given the huge number of choices and combinations of components such as aggregator and activation function, determining the suitable GNN structure for a specific problem normally necessitates tremendous expert knowledge and laborious trails. In addition, the slight variation of hyper parameters such as learning rate and dropout rate could dramatically hurt the learning capacity of GNN. In this paper, we propose a novel AutoML framework through the evolution of individual models in a large GNN architecture space involving both neural structures and learning parameters. Instead of optimizing only the model structures with fixed parameter settings as existing work, an alternating evolution process is performed between GNN structures and learning parameters to dynamically find the best fit of each other. To the best of our knowledge, this is the first work to introduce and evaluate evolutionary architecture search for GNN models. Experiments and validations demonstrate that evolutionary NAS is capable of matching existing state-of-the-art reinforcement learning approaches for both the semi-supervised transductive and inductive node representation learning and classification.
Multi-Label Graph Convolutional Network Representation Learning
Dec 26, 2019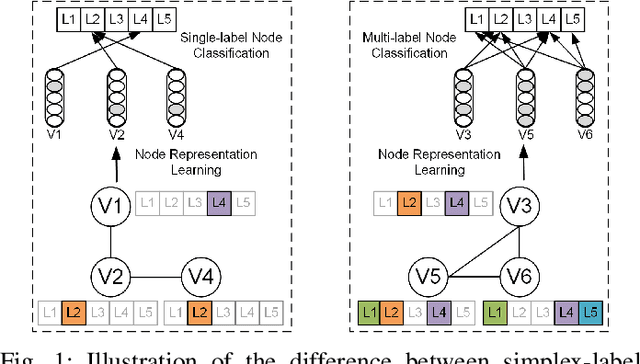
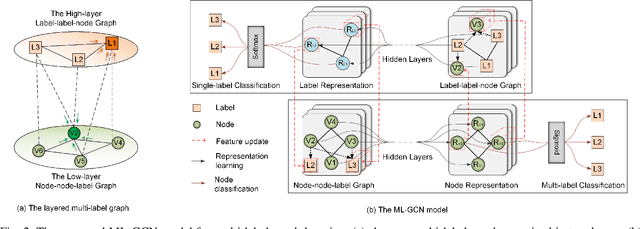
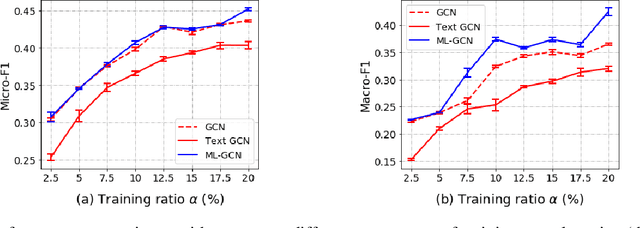
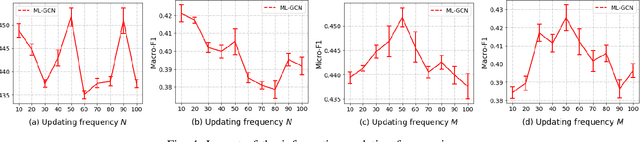
Knowledge representation of graph-based systems is fundamental across many disciplines. To date, most existing methods for representation learning primarily focus on networks with simplex labels, yet real-world objects (nodes) are inherently complex in nature and often contain rich semantics or labels, e.g., a user may belong to diverse interest groups of a social network, resulting in multi-label networks for many applications. The multi-label network nodes not only have multiple labels for each node, such labels are often highly correlated making existing methods ineffective or fail to handle such correlation for node representation learning. In this paper, we propose a novel multi-label graph convolutional network (ML-GCN) for learning node representation for multi-label networks. To fully explore label-label correlation and network topology structures, we propose to model a multi-label network as two Siamese GCNs: a node-node-label graph and a label-label-node graph. The two GCNs each handle one aspect of representation learning for nodes and labels, respectively, and they are seamlessly integrated under one objective function. The learned label representations can effectively preserve the inner-label interaction and node label properties, and are then aggregated to enhance the node representation learning under a unified training framework. Experiments and comparisons on multi-label node classification validate the effectiveness of our proposed approach.
Feature-Attention Graph Convolutional Networks for Noise Resilient Learning
Dec 26, 2019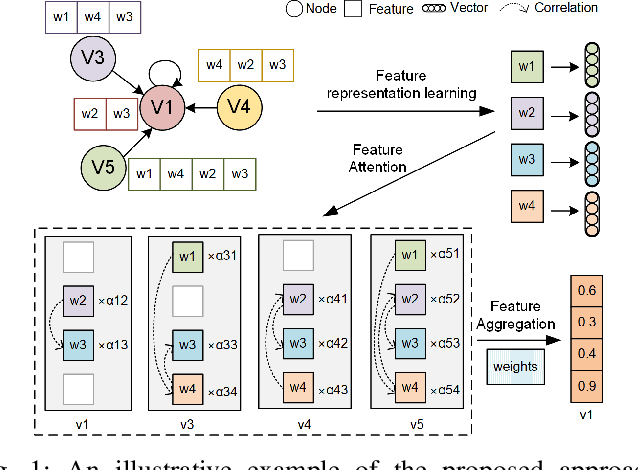
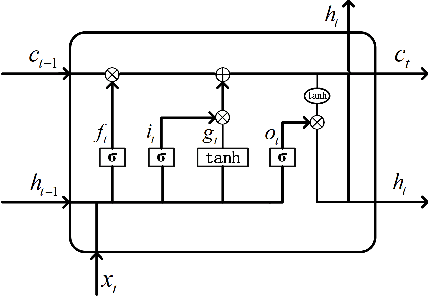
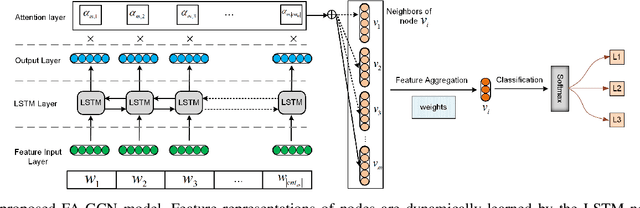
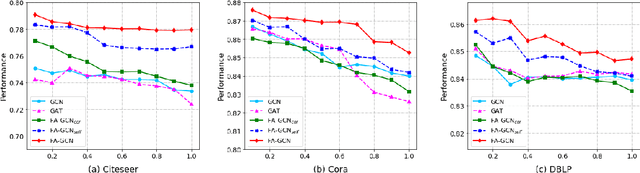
Noise and inconsistency commonly exist in real-world information networks, due to inherent error-prone nature of human or user privacy concerns. To date, tremendous efforts have been made to advance feature learning from networks, including the most recent Graph Convolutional Networks (GCN) or attention GCN, by integrating node content and topology structures. However, all existing methods consider networks as error-free sources and treat feature content in each node as independent and equally important to model node relations. The erroneous node content, combined with sparse features, provide essential challenges for existing methods to be used on real-world noisy networks. In this paper, we propose FA-GCN, a feature-attention graph convolution learning framework, to handle networks with noisy and sparse node content. To tackle noise and sparse content in each node, FA-GCN first employs a long short-term memory (LSTM) network to learn dense representation for each feature. To model interactions between neighboring nodes, a feature-attention mechanism is introduced to allow neighboring nodes learn and vary feature importance, with respect to their connections. By using spectral-based graph convolution aggregation process, each node is allowed to concentrate more on the most determining neighborhood features aligned with the corresponding learning task. Experiments and validations, w.r.t. different noise levels, demonstrate that FA-GCN achieves better performance than state-of-the-art methods on both noise-free and noisy networks.
ClassyTune: A Performance Auto-Tuner for Systems in the Cloud
Oct 12, 2019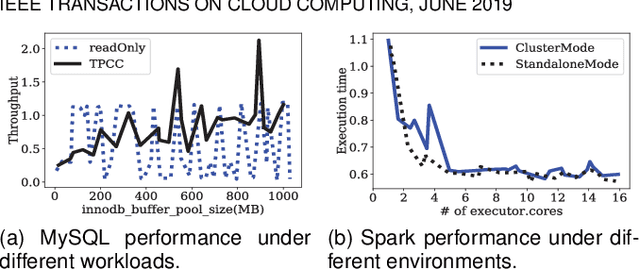
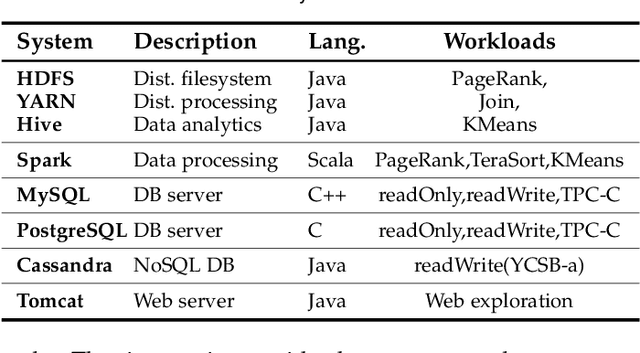
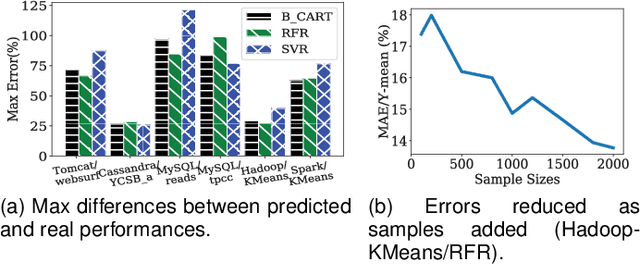
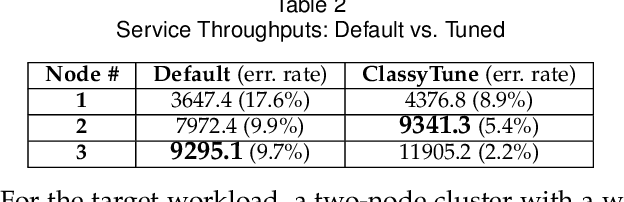
Performance tuning can improve the system performance and thus enable the reduction of cloud computing resources needed to support an application. Due to the ever increasing number of parameters and complexity of systems, there is a necessity to automate performance tuning for the complicated systems in the cloud. The state-of-the-art tuning methods are adopting either the experience-driven tuning approach or the data-driven one. Data-driven tuning is attracting increasing attentions, as it has wider applicability. But existing data-driven methods cannot fully address the challenges of sample scarcity and high dimensionality simultaneously. We present ClassyTune, a data-driven automatic configuration tuning tool for cloud systems. ClassyTune exploits the machine learning model of classification for auto-tuning. This exploitation enables the induction of more training samples without increasing the input dimension. Experiments on seven popular systems in the cloud show that ClassyTune can effectively tune system performance to seven times higher for high-dimensional configuration space, outperforming expert tuning and the state-of-the-art auto-tuning solutions. We also describe a use case in which performance tuning enables the reduction of 33% computing resources needed to run an online stateless service.
* 12 pages, Journal paper