 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNet-2022: Exploring Dynamics in Non-isomorphic Architecture
Oct 27, 2022Recent medical image segmentation models are mostly hybrid, which integrate self-attention and convolution layers into the non-isomorphic architecture. However, one potential drawback of these approaches is that they failed to provide an intuitive explanation of why this hybrid combination manner is beneficial, making it difficult for subsequent work to make improvements on top of them. To address this issue, we first analyze the differences between the weight allocation mechanisms of the self-attention and convolution. Based on this analysis, we propose to construct a parallel non-isomorphic block that takes the advantages of self-attention and convolution with simple parallelization. We name the resulting U-shape segmentation model as UNet-2022. In experiments, UNet-2022 obviously outperforms its counterparts in a range segmentation tasks, including abdominal multi-organ segmentation, automatic cardiac diagnosis, neural structures segmentation, and skin lesion segmentation, sometimes surpassing the best performing baseline by 4%. Specifically, UNet-2022 surpasses nnUNet, the most recognized segmentation model at present, by large margins. These phenomena indicate the potential of UNet-2022 to become the model of choice for medical image segmentation.
nnFormer: Interleaved Transformer for Volumetric Segmentation
Oct 01, 2021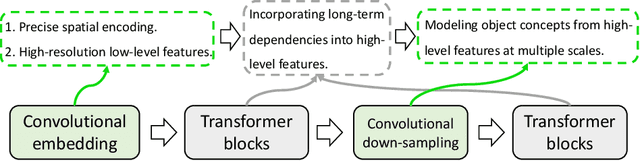
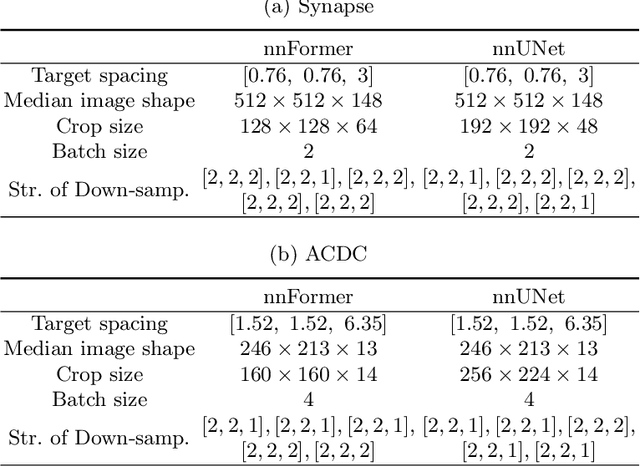
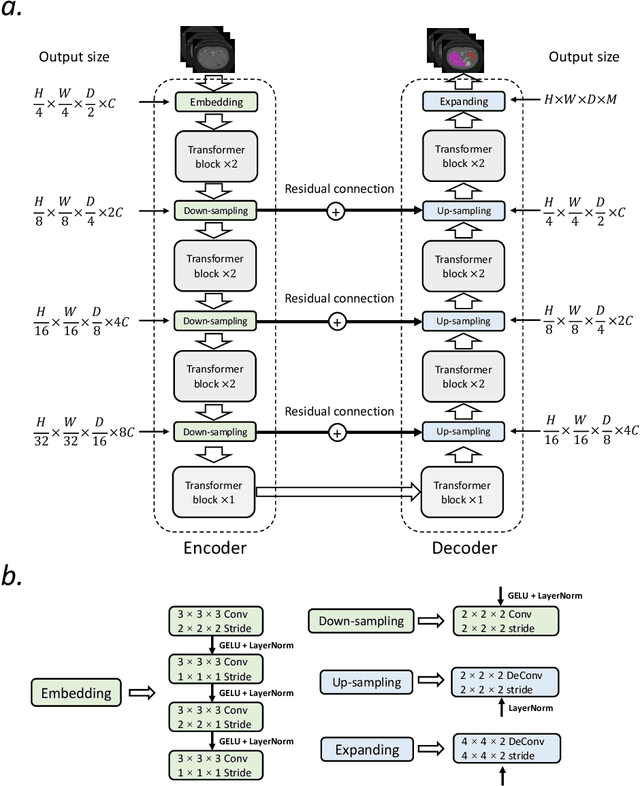
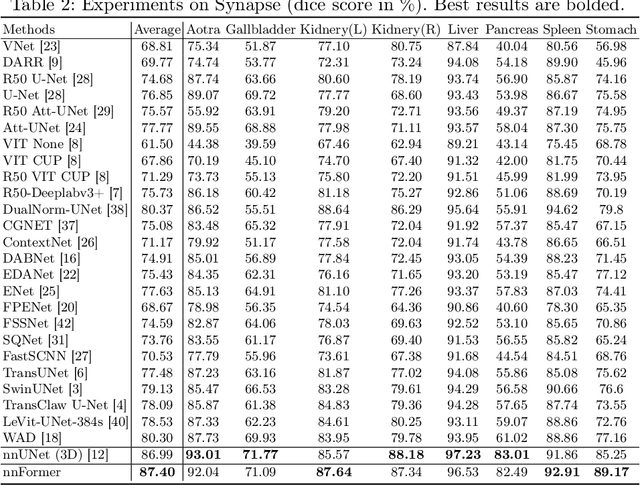
Transformers, the default model of choices in natural language processing, have drawn scant attention from the medical imaging community. Given the ability to exploit long-term dependencies, transformers are promising to help atypical convolutional neural networks (convnets) to overcome its inherent shortcomings of spatial inductive bias. However, most of recently proposed transformer-based segmentation approaches simply treated transformers as assisted modules to help encode global context into convolutional representations without investigating how to optimally combine self-attention (i.e., the core of transformers) with convolution. To address this issue, in this paper, we introduce nnFormer (i.e., Not-aNother transFormer), a powerful segmentation model with an interleaved architecture based on empirical combination of self-attention and convolution. In practice, nnFormer learns volumetric representations from 3D local volumes. Compared to the naive voxel-level self-attention implementation, such volume-based operations help to reduce the computational complexity by approximate 98% and 99.5% on Synapse and ACDC datasets, respectively. In comparison to prior-art network configurations, nnFormer achieves tremendous improvements over previous transformer-based methods on two commonly used datasets Synapse and ACDC. For instance, nnFormer outperforms Swin-UNet by over 7 percents on Synapse. Even when compared to nnUNet, currently the best performing fully-convolutional medical segmentation network, nnFormer still provides slightly better performance on Synapse and ACDC.