 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D AGSE-VNet: An Automatic Brain Tumor MRI Data Segmentation Framework
Jul 26, 2021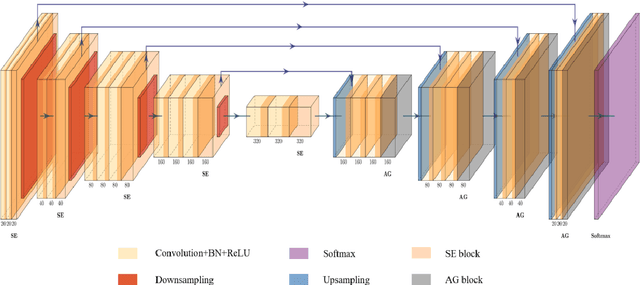
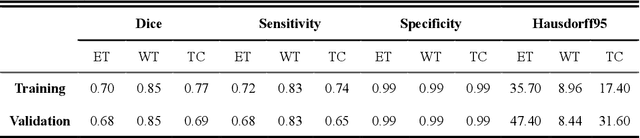
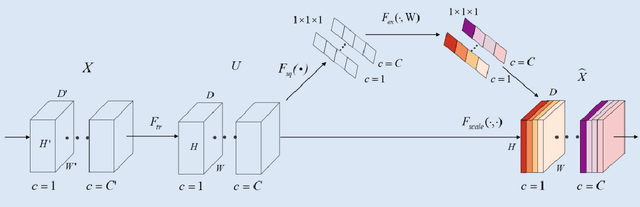
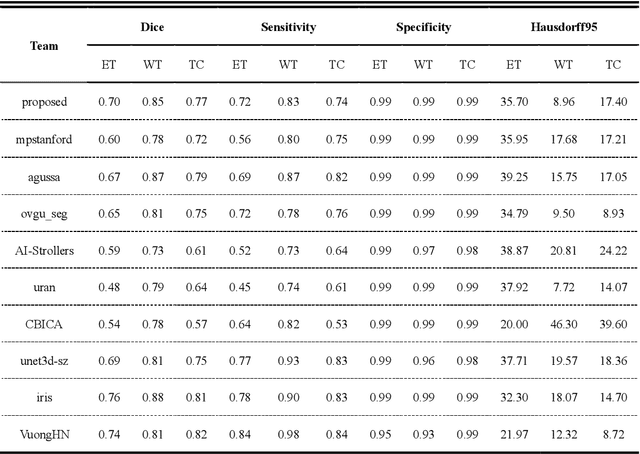
Background: Glioma is the most common brain malignant tumor, with a high morbidity rate and a mortality rate of more than three percent, which seriously endangers human health. The main method of acquiring brain tumors in the clinic is MRI. Segmentation of brain tumor regions from multi-modal MRI scan images is helpful for treatment inspection, post-diagnosis monitoring, and effect evaluation of patients. However, the common operation in clinical brain tumor segmentation is still manual segmentation, lead to its time-consuming and large performance difference between different operators, a consistent and accurate automatic segmentation method is urgently needed. Methods: To meet the above challenges, we propose an automatic brain tumor MRI data segmentation framework which is called AGSE-VNet. In our study, the Squeeze and Excite (SE) module is added to each encoder, the Attention Guide Filter (AG) module is added to each decoder, using the channel relationship to automatically enhance the useful information in the channel to suppress the useless information, and use the attention mechanism to guide the edge information and remove the influence of irrelevant information such as noise. Results: We used the BraTS2020 challenge online verification tool to evaluate our approach. The focus of verification is that the Dice scores of the whole tumor (WT), tumor core (TC) and enhanced tumor (ET) are 0.68, 0.85 and 0.70, respectively. Conclusion: Although MRI images have different intensities, AGSE-VNet is not affected by the size of the tumor, and can more accurately extract the features of the three regions, it has achieved impressive results and made outstanding contributions to the clinical diagnosis and treatment of brain tumor patients.
Distillation Guided Residual Learning for Binary Convolutional Neural Networks
Jul 10, 2020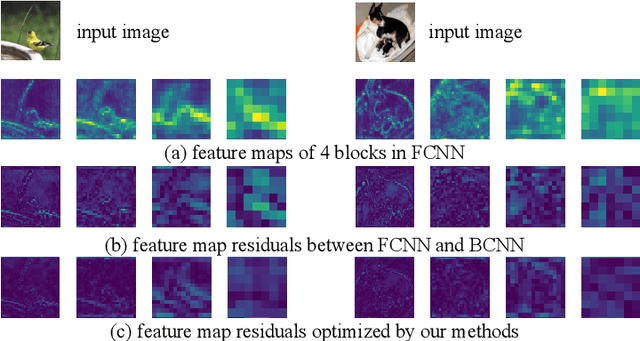

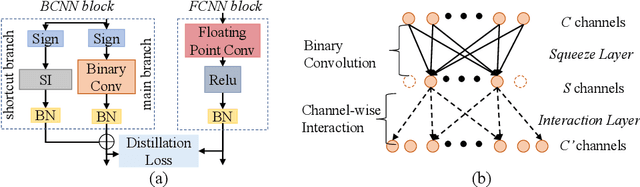
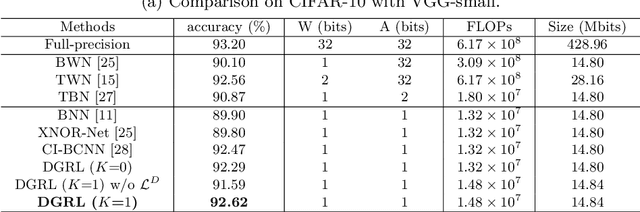
It is challenging to bridge the performance gap between Binary CNN (BCNN) and Floating point CNN (FCNN). We observe that, this performance gap leads to substantial residuals between intermediate feature maps of BCNN and FCNN. To minimize the performance gap, we enforce BCNN to produce similar intermediate feature maps with the ones of FCNN. This training strategy, i.e., optimizing each binary convolutional block with block-wise distillation loss derived from FCNN, leads to a more effective optimization to BCNN. It also motivates us to update the binary convolutional block architecture to facilitate the optimization of block-wise distillation loss. Specifically, a lightweight shortcut branch is inserted into each binary convolutional block to complement residuals at each block. Benefited from its Squeeze-and-Interaction (SI) structure, this shortcut branch introduces a fraction of parameters, e.g., 10\% overheads, but effectively complements the residuals. Extensive experiments on ImageNet demonstrate the superior performance of our method in both classification efficiency and accuracy, e.g., BCNN trained with our methods achieves the accuracy of 60.45\% on ImageNet.