 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation Guided Residual Learning for Binary Convolutional Neural Networks
Paper and Code
Jul 10, 2020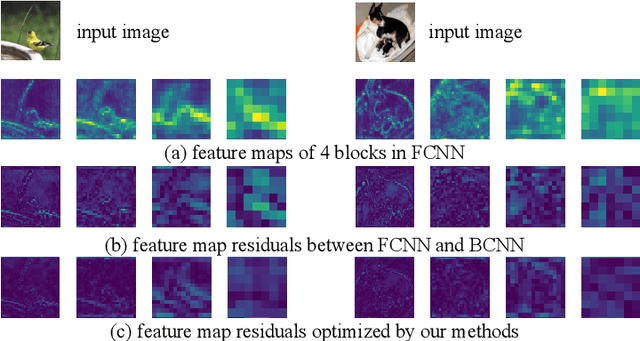

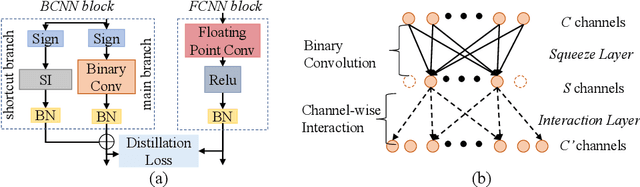
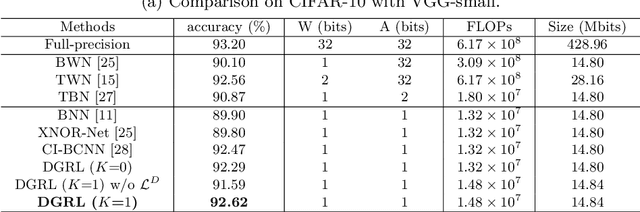
It is challenging to bridge the performance gap between Binary CNN (BCNN) and Floating point CNN (FCNN). We observe that, this performance gap leads to substantial residuals between intermediate feature maps of BCNN and FCNN. To minimize the performance gap, we enforce BCNN to produce similar intermediate feature maps with the ones of FCNN. This training strategy, i.e., optimizing each binary convolutional block with block-wise distillation loss derived from FCNN, leads to a more effective optimization to BCNN. It also motivates us to update the binary convolutional block architecture to facilitate the optimization of block-wise distillation loss. Specifically, a lightweight shortcut branch is inserted into each binary convolutional block to complement residuals at each block. Benefited from its Squeeze-and-Interaction (SI) structure, this shortcut branch introduces a fraction of parameters, e.g., 10\% overheads, but effectively complements the residuals. Extensive experiments on ImageNet demonstrate the superior performance of our method in both classification efficiency and accuracy, e.g., BCNN trained with our methods achieves the accuracy of 60.45\% on ImageNet.