 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractive Sentence Summarization with Guidance of Selective Multimodal Reference
Aug 11, 2021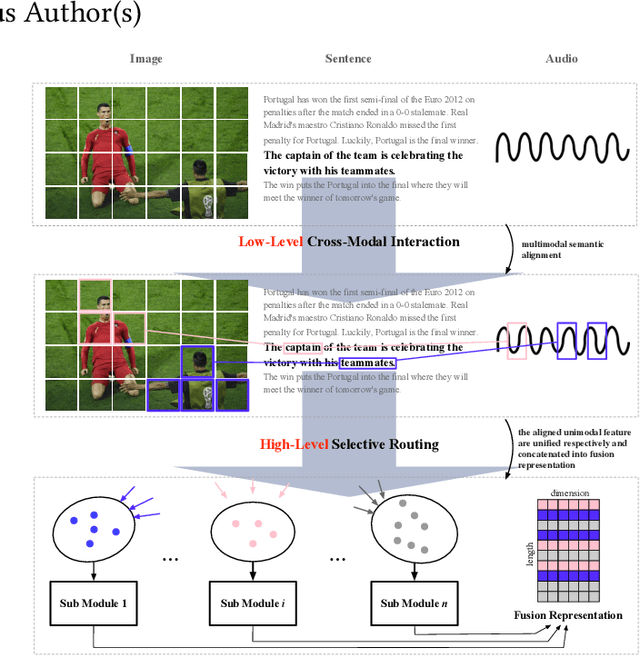

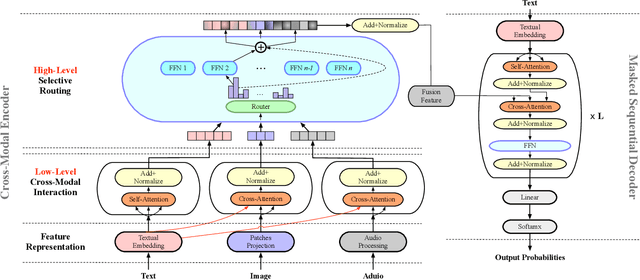
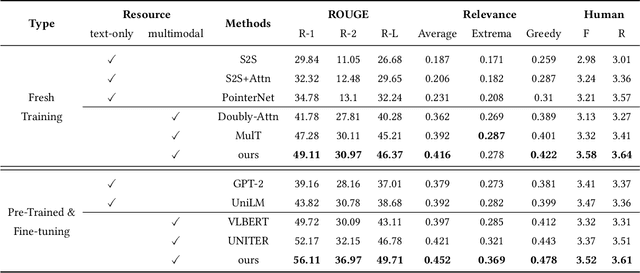
Multimodal abstractive summarization with sentence output is to generate a textual summary given a multimodal triad -- sentence, image and audio, which has been proven to improve users satisfaction and convenient our life. Existing approaches mainly focus on the enhancement of multimodal fusion, while ignoring the unalignment among multiple inputs and the emphasis of different segments in feature, which has resulted in the superfluity of multimodal interaction. To alleviate these problems, we propose a Multimodal Hierarchical Selective Transformer (mhsf) model that considers reciprocal relationships among modalities (by low-level cross-modal interaction module) and respective characteristics within single fusion feature (by high-level selective routing module). In details, it firstly aligns the inputs from different sources and then adopts a divide and conquer strategy to highlight or de-emphasize multimodal fusion representation, which can be seen as a sparsely feed-forward model - different groups of parameters will be activated facing different segments in feature. We evaluate the generalism of proposed mhsf model with the pre-trained+fine-tuning and fresh training strategies. And Further experimental results on MSMO demonstrate that our model outperforms SOTA baselines in terms of ROUGE, relevance scores and human evaluation.
PGCD: a position-guied contributive distribution unit for aspect based sentiment analysis
Aug 11, 2021
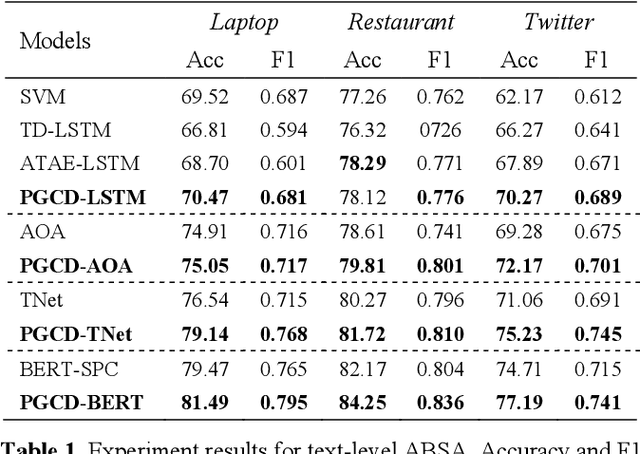
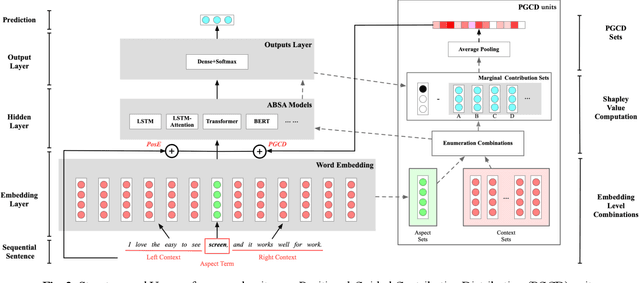
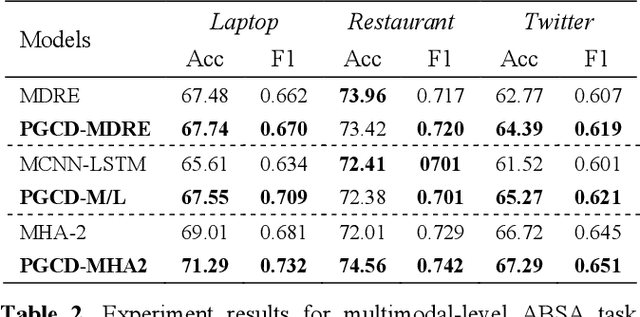
Aspect based sentiment analysis (ABSA), exploring sentim- ent polarity of aspect-given sentence, has drawn widespread applications in social media and public opinion. Previously researches typically derive aspect-independent representation by sentence feature generation only depending on text data. In this paper, we propose a Position-Guided Contributive Distribution (PGCD) unit. It achieves a position-dependent contributive pattern and generates aspect-related statement feature for ABSA task. Quoted from Shapley Value, PGCD can gain position-guided contextual contribution and enhance the aspect-based representation. Furthermore, the unit can be used for improving effects on multimodal ABSA task, whose datasets restructured by ourselves. Extensive experiments on both text and text-audio level using dataset (SemEval) show that by applying the proposed unit, the mainstream models advance performance in accuracy and F1 score.