 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinical Benchmark of Public Self-Supervised Pathology Foundation Models
Jul 11, 2024



The use of self-supervised learning (SSL) to train pathology foundation models has increased substantially in the past few years. Notably, several models trained on large quantities of clinical data have been made publicly available in recent months. This will significantly enhance scientific research in computational pathology and help bridge the gap between research and clinical deployment. With the increase in availability of public foundation models of different sizes, trained using different algorithms on different datasets, it becomes important to establish a benchmark to compare the performance of such models on a variety of clinically relevant tasks spanning multiple organs and diseases. In this work, we present a collection of pathology datasets comprising clinical slides associated with clinically relevant endpoints including cancer diagnoses and a variety of biomarkers generated during standard hospital operation from two medical centers. We leverage these datasets to systematically assess the performance of public pathology foundation models and provide insights into best practices for training new foundation models and selecting appropriate pretrained models.
Benchmarking Embedding Aggregation Methods in Computational Pathology: A Clinical Data Perspective
Jul 10, 2024


Recent advances in artificial intelligence (AI), in particular self-supervised learning of foundation models (FMs), are revolutionizing medical imaging and computational pathology (CPath). A constant challenge in the analysis of digital Whole Slide Images (WSIs) is the problem of aggregating tens of thousands of tile-level image embeddings to a slide-level representation. Due to the prevalent use of datasets created for genomic research, such as TCGA, for method development, the performance of these techniques on diagnostic slides from clinical practice has been inadequately explored. This study conducts a thorough benchmarking analysis of ten slide-level aggregation techniques across nine clinically relevant tasks, including diagnostic assessment, biomarker classification, and outcome prediction. The results yield following key insights: (1) Embeddings derived from domain-specific (histological images) FMs outperform those from generic ImageNet-based models across aggregation methods. (2) Spatial-aware aggregators enhance the performance significantly when using ImageNet pre-trained models but not when using FMs. (3) No single model excels in all tasks and spatially-aware models do not show general superiority as it would be expected. These findings underscore the need for more adaptable and universally applicable aggregation techniques, guiding future research towards tools that better meet the evolving needs of clinical-AI in pathology. The code used in this work is available at \url{https://github.com/fuchs-lab-public/CPath_SABenchmark}.
Beyond Multiple Instance Learning: Full Resolution All-In-Memory End-To-End Pathology Slide Modeling
Mar 07, 2024


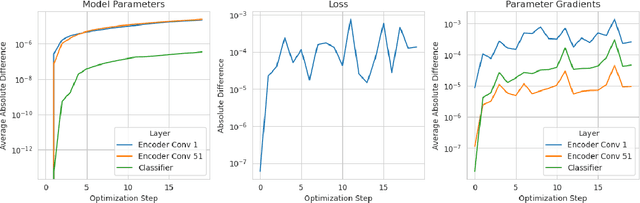
Artificial Intelligence (AI) has great potential to improve health outcomes by training systems on vast digitized clinical datasets. Computational Pathology, with its massive amounts of microscopy image data and impact on diagnostics and biomarkers, is at the forefront of this development. Gigapixel pathology slides pose a unique challenge due to their enormous size and are usually divided into tens of thousands of smaller tiles for analysis. This results in a discontinuity in the machine learning process by separating the training of tile-level encoders from slide-level aggregators and the need to adopt weakly supervised learning strategies. Training models from entire pathology slides end-to-end has been largely unexplored due to its computational challenges. To overcome this problem, we propose a novel approach to jointly train both a tile encoder and a slide-aggregator fully in memory and end-to-end at high-resolution, bridging the gap between input and slide-level supervision. While more computationally expensive, detailed quantitative validation shows promise for large-scale pre-training of pathology foundation models.
Computational Pathology at Health System Scale -- Self-Supervised Foundation Models from Three Billion Images
Oct 10, 2023Recent breakthroughs in self-supervised learning have enabled the use of large unlabeled datasets to train visual foundation models that can generalize to a variety of downstream tasks. While this training paradigm is well suited for the medical domain where annotations are scarce, large-scale pre-training in the medical domain, and in particular pathology, has not been extensively studied. Previous work in self-supervised learning in pathology has leveraged smaller datasets for both pre-training and evaluating downstream performance. The aim of this project is to train the largest academic foundation model and benchmark the most prominent self-supervised learning algorithms by pre-training and evaluating downstream performance on large clinical pathology datasets. We collected the largest pathology dataset to date, consisting of over 3 billion images from over 423 thousand microscopy slides. We compared pre-training of visual transformer models using the masked autoencoder (MAE) and DINO algorithms. We evaluated performance on six clinically relevant tasks from three anatomic sites and two institutions: breast cancer detection, inflammatory bowel disease detection, breast cancer estrogen receptor prediction, lung adenocarcinoma EGFR mutation prediction, and lung cancer immunotherapy response prediction. Our results demonstrate that pre-training on pathology data is beneficial for downstream performance compared to pre-training on natural images. Additionally, the DINO algorithm achieved better generalization performance across all tasks tested. The presented results signify a phase change in computational pathology research, paving the way into a new era of more performant models based on large-scale, parallel pre-training at the billion-image scale.