 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessibility Considerations in the Development of an AI Action Plan
Mar 14, 2025We argue that there is a need for Accessibility to be represented in several important domains: - Capitalize on the new capabilities AI provides - Support for open source development of AI, which can allow disabled and disability focused professionals to contribute, including - Development of Accessibility Apps which help realise the promise of AI in accessibility domains - Open Source Model Development and Validation to ensure that accessibility concerns are addressed in these algorithms - Data Augmentation to include accessibility in data sets used to train models - Accessible Interfaces that allow disabled people to use any AI app, and to validate its outputs - Dedicated Functionality and Libraries that can make it easy to integrate AI support into a variety of settings and apps. - Data security and privacy and privacy risks including data collected by AI based accessibility technologies; and the possibility of disability disclosure. - Disability-specific AI risks and biases including both direct bias (during AI use by the disabled person) and indirect bias (when AI is used by someone else on data relating to a disabled person).
Identifying and Improving Disability Bias in GAI-Based Resume Screening
Jan 28, 2024



As Generative AI rises in adoption, its use has expanded to include domains such as hiring and recruiting. However, without examining the potential of bias, this may negatively impact marginalized populations, including people with disabilities. To address this important concern, we present a resume audit study, in which we ask ChatGPT (specifically, GPT-4) to rank a resume against the same resume enhanced with an additional leadership award, scholarship, panel presentation, and membership that are disability related. We find that GPT-4 exhibits prejudice towards these enhanced CVs. Further, we show that this prejudice can be quantifiably reduced by training a custom GPTs on principles of DEI and disability justice. Our study also includes a unique qualitative analysis of the types of direct and indirect ableism GPT-4 uses to justify its biased decisions and suggest directions for additional bias mitigation work. Additionally, since these justifications are presumably drawn from training data containing real-world biased statements made by humans, our analysis suggests additional avenues for understanding and addressing human bias.
GLOBEM Dataset: Multi-Year Datasets for Longitudinal Human Behavior Modeling Generalization
Nov 04, 2022



Recent research has demonstrated the capability of behavior signals captured by smartphones and wearables for longitudinal behavior modeling. However, there is a lack of a comprehensive public dataset that serves as an open testbed for fair comparison among algorithms. Moreover, prior studies mainly evaluate algorithms using data from a single population within a short period, without measuring the cross-dataset generalizability of these algorithms. We present the first multi-year passive sensing datasets, containing over 700 user-years and 497 unique users' data collected from mobile and wearable sensors, together with a wide range of well-being metrics. Our datasets can support multiple cross-dataset evaluations of behavior modeling algorithms' generalizability across different users and years. As a starting point, we provide the benchmark results of 18 algorithms on the task of depression detection. Our results indicate that both prior depression detection algorithms and domain generalization techniques show potential but need further research to achieve adequate cross-dataset generalizability. We envision our multi-year datasets can support the ML community in developing generalizable longitudinal behavior modeling algorithms.
Dynamic Question Ordering in Online Surveys
Jul 14, 2016
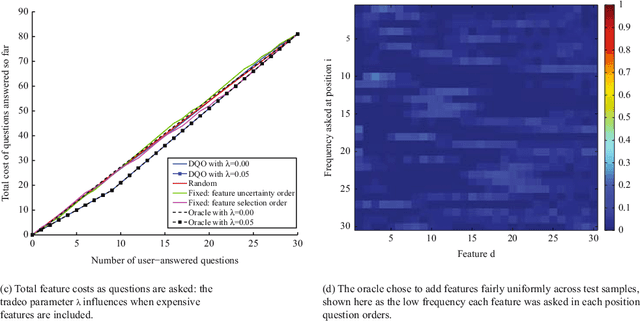

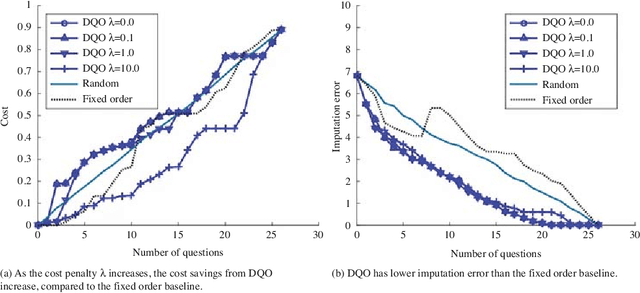
Online surveys have the potential to support adaptive questions, where later questions depend on earlier responses. Past work has taken a rule-based approach, uniformly across all respondents. We envision a richer interpretation of adaptive questions, which we call dynamic question ordering (DQO), where question order is personalized. Such an approach could increase engagement, and therefore response rate, as well as imputation quality. We present a DQO framework to improve survey completion and imputation. In the general survey-taking setting, we want to maximize survey completion, and so we focus on ordering questions to engage the respondent and collect hopefully all information, or at least the information that most characterizes the respondent, for accurate imputations. In another scenario, our goal is to provide a personalized prediction. Since it is possible to give reasonable predictions with only a subset of questions, we are not concerned with motivating users to answer all questions. Instead, we want to order questions to get information that reduces prediction uncertainty, while not being too burdensome. We illustrate this framework with an example of providing energy estimates to prospective tenants. We also discuss DQO for national surveys and consider connections between our statistics-based question-ordering approach and cognitive survey methodology.