 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Frank-Wolfe Algorithm for Convex and Non-convex Problems
Aug 28, 2018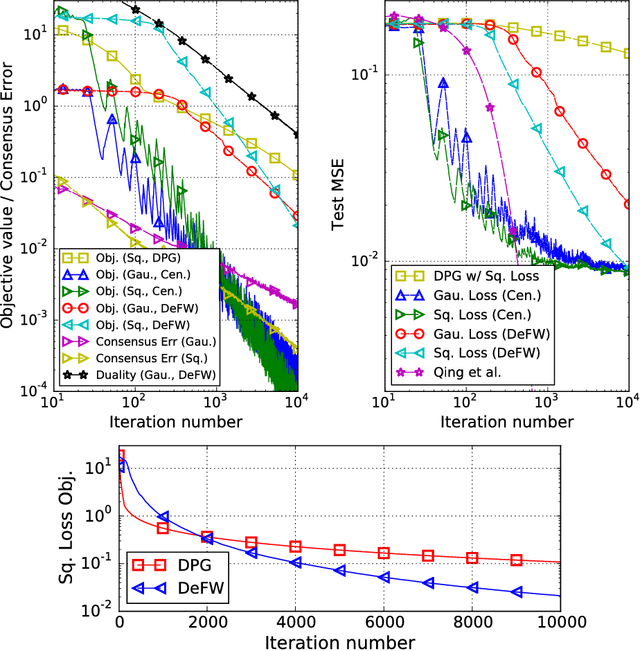


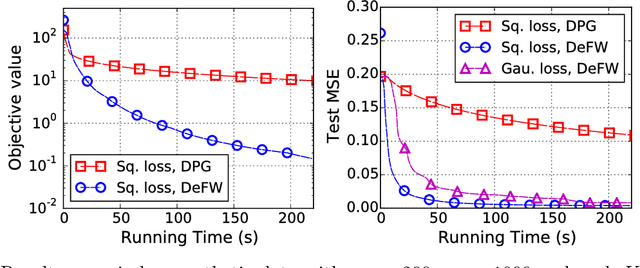
Decentralized optimization algorithms have received much attention due to the recent advances in network information processing. However, conventional decentralized algorithms based on projected gradient descent are incapable of handling high dimensional constrained problems, as the projection step becomes computationally prohibitive to compute. To address this problem, this paper adopts a projection-free optimization approach, a.k.a.~the Frank-Wolfe (FW) or conditional gradient algorithm. We first develop a decentralized FW (DeFW) algorithm from the classical FW algorithm. The convergence of the proposed algorithm is studied by viewing the decentralized algorithm as an inexact FW algorithm. Using a diminishing step size rule and letting $t$ be the iteration number, we show that the DeFW algorithm's convergence rate is ${\cal O}(1/t)$ for convex objectives; is ${\cal O}(1/t^2)$ for strongly convex objectives with the optimal solution in the interior of the constraint set; and is ${\cal O}(1/\sqrt{t})$ towards a stationary point for smooth but non-convex objectives. We then show that a consensus-based DeFW algorithm meets the above guarantees with two communication rounds per iteration. Furthermore, we demonstrate the advantages of the proposed DeFW algorithm on low-complexity robust matrix completion and communication efficient sparse learning. Numerical results on synthetic and real data are presented to support our findings.
Diagonal Rescaling For Neural Networks
May 25, 2017


We define a second-order neural network stochastic gradient training algorithm whose block-diagonal structure effectively amounts to normalizing the unit activations. Investigating why this algorithm lacks in robustness then reveals two interesting insights. The first insight suggests a new way to scale the stepsizes, clarifying popular algorithms such as RMSProp as well as old neural network tricks such as fanin stepsize scaling. The second insight stresses the practical importance of dealing with fast changes of the curvature of the cost.
On the Online Frank-Wolfe Algorithms for Convex and Non-convex Optimizations
Aug 15, 2016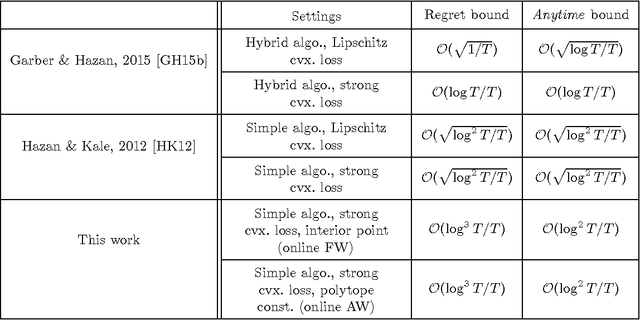



In this paper, the online variants of the classical Frank-Wolfe algorithm are considered. We consider minimizing the regret with a stochastic cost. The online algorithms only require simple iterative updates and a non-adaptive step size rule, in contrast to the hybrid schemes commonly considered in the literature. Several new results are derived for convex and non-convex losses. With a strongly convex stochastic cost and when the optimal solution lies in the interior of the constraint set or the constraint set is a polytope, the regret bound and anytime optimality are shown to be ${\cal O}( \log^3 T / T )$ and ${\cal O}( \log^2 T / T)$, respectively, where $T$ is the number of rounds played. These results are based on an improved analysis on the stochastic Frank-Wolfe algorithms. Moreover, the online algorithms are shown to converge even when the loss is non-convex, i.e., the algorithms find a stationary point to the time-varying/stochastic loss at a rate of ${\cal O}(\sqrt{1/T})$. Numerical experiments on realistic data sets are presented to support our theoretical claims.
Low Rank Matrix Completion with Exponential Family Noise
Apr 20, 2015
The matrix completion problem consists in reconstructing a matrix from a sample of entries, possibly observed with noise. A popular class of estimator, known as nuclear norm penalized estimators, are based on minimizing the sum of a data fitting term and a nuclear norm penalization. Here, we investigate the case where the noise distribution belongs to the exponential family and is sub-exponential. Our framework alllows for a general sampling scheme. We first consider an estimator defined as the minimizer of the sum of a log-likelihood term and a nuclear norm penalization and prove an upper bound on the Frobenius prediction risk. The rate obtained improves on previous works on matrix completion for exponential family. When the sampling distribution is known, we propose another estimator and prove an oracle inequality w.r.t. the Kullback-Leibler prediction risk, which translates immediatly into an upper bound on the Frobenius prediction risk. Finally, we show that all the rates obtained are minimax optimal up to a logarithmic factor.
Probabilistic low-rank matrix completion on finite alphabets
Dec 08, 2014



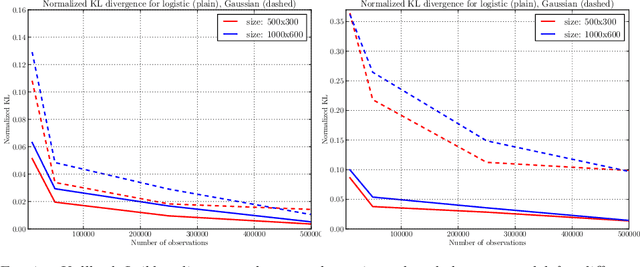
The task of reconstructing a matrix given a sample of observedentries is known as the matrix completion problem. It arises ina wide range of problems, including recommender systems, collaborativefiltering, dimensionality reduction, image processing, quantum physics or multi-class classificationto name a few. Most works have focused on recovering an unknown real-valued low-rankmatrix from randomly sub-sampling its entries.Here, we investigate the case where the observations take a finite number of values, corresponding for examples to ratings in recommender systems or labels in multi-class classification.We also consider a general sampling scheme (not necessarily uniform) over the matrix entries.The performance of a nuclear-norm penalized estimator is analyzed theoretically.More precisely, we derive bounds for the Kullback-Leibler divergence between the true and estimated distributions.In practice, we have also proposed an efficient algorithm based on lifted coordinate gradient descent in order to tacklepotentially high dimensional settings.
* arXiv admin note: text overlap with arXiv:1408.6218
Adaptive Multinomial Matrix Completion
Aug 26, 2014


The task of estimating a matrix given a sample of observed entries is known as the \emph{matrix completion problem}. Most works on matrix completion have focused on recovering an unknown real-valued low-rank matrix from a random sample of its entries. Here, we investigate the case of highly quantized observations when the measurements can take only a small number of values. These quantized outputs are generated according to a probability distribution parametrized by the unknown matrix of interest. This model corresponds, for example, to ratings in recommender systems or labels in multi-class classification. We consider a general, non-uniform, sampling scheme and give theoretical guarantees on the performance of a constrained, nuclear norm penalized maximum likelihood estimator. One important advantage of this estimator is that it does not require knowledge of the rank or an upper bound on the nuclear norm of the unknown matrix and, thus, it is adaptive. We provide lower bounds showing that our estimator is minimax optimal. An efficient algorithm based on lifted coordinate gradient descent is proposed to compute the estimator. A limited Monte-Carlo experiment, using both simulated and real data is provided to support our claims.