 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Online Frank-Wolfe Algorithms for Convex and Non-convex Optimizations
Paper and Code
Aug 15, 2016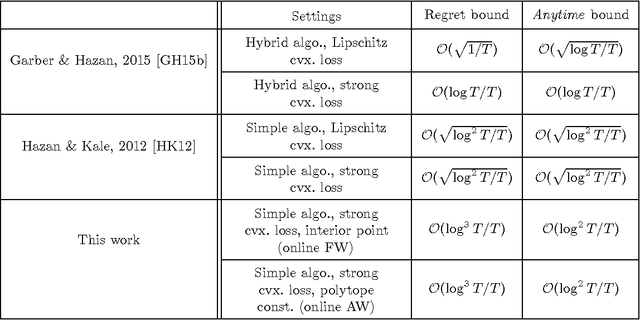



In this paper, the online variants of the classical Frank-Wolfe algorithm are considered. We consider minimizing the regret with a stochastic cost. The online algorithms only require simple iterative updates and a non-adaptive step size rule, in contrast to the hybrid schemes commonly considered in the literature. Several new results are derived for convex and non-convex losses. With a strongly convex stochastic cost and when the optimal solution lies in the interior of the constraint set or the constraint set is a polytope, the regret bound and anytime optimality are shown to be ${\cal O}( \log^3 T / T )$ and ${\cal O}( \log^2 T / T)$, respectively, where $T$ is the number of rounds played. These results are based on an improved analysis on the stochastic Frank-Wolfe algorithms. Moreover, the online algorithms are shown to converge even when the loss is non-convex, i.e., the algorithms find a stationary point to the time-varying/stochastic loss at a rate of ${\cal O}(\sqrt{1/T})$. Numerical experiments on realistic data sets are presented to support our theoretical claims.