 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNeRV: Spectra-preserving Neural Representation for Video
Jan 03, 2025Neural representation for video (NeRV), which employs a neural network to parameterize video signals, introduces a novel methodology in video representations. However, existing NeRV-based methods have difficulty in capturing fine spatial details and motion patterns due to spectral bias, in which a neural network learns high-frequency (HF) components at a slower rate than low-frequency (LF) components. In this paper, we propose spectra-preserving NeRV (SNeRV) as a novel approach to enhance implicit video representations by efficiently handling various frequency components. SNeRV uses 2D discrete wavelet transform (DWT) to decompose video into LF and HF features, preserving spatial structures and directly addressing the spectral bias issue. To balance the compactness, we encode only the LF components, while HF components that include fine textures are generated by a decoder. Specialized modules, including a multi-resolution fusion unit (MFU) and a high-frequency restorer (HFR), are integrated into a backbone to facilitate the representation. Furthermore, we extend SNeRV to effectively capture temporal correlations between adjacent video frames, by casting the extension as additional frequency decomposition to a temporal domain. This approach allows us to embed spatio-temporal LF features into the network, using temporally extended up-sampling blocks (TUBs). Experimental results demonstrate that SNeRV outperforms existing NeRV models in capturing fine details and achieves enhanced reconstruction, making it a promising approach in the field of implicit video representations. The codes are available at https://github.com/qwertja/SNeRV.
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022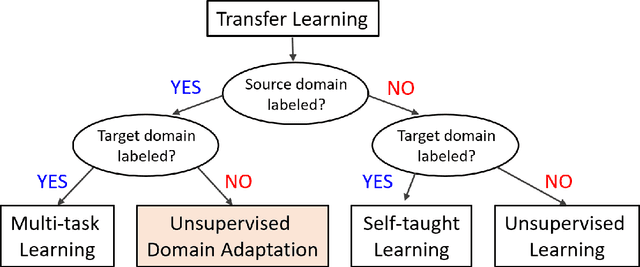

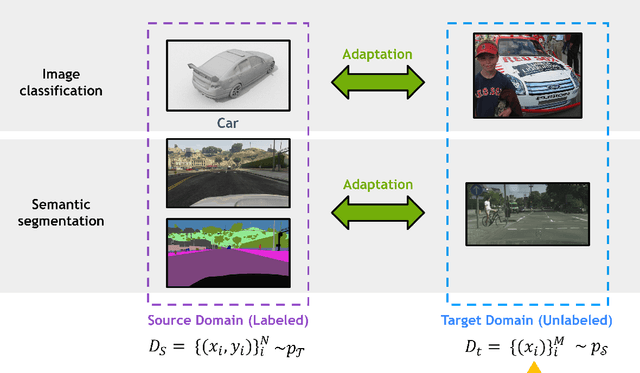

Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.