 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Segmentation with Black-box Source Model
Aug 16, 2022Unsupervised domain adaptation (UDA) has been widely used to transfer knowledge from a labeled source domain to an unlabeled target domain to counter the difficulty of labeling in a new domain. The training of conventional solutions usually relies on the existence of both source and target domain data. However, privacy of the large-scale and well-labeled data in the source domain and trained model parameters can become the major concern of cross center/domain collaborations. In this work, to address this, we propose a practical solution to UDA for segmentation with a black-box segmentation model trained in the source domain only, rather than original source data or a white-box source model. Specifically, we resort to a knowledge distillation scheme with exponential mixup decay (EMD) to gradually learn target-specific representations. In addition, unsupervised entropy minimization is further applied to regularization of the target domain confidence. We evaluated our framework on the BraTS 2018 database, achieving performance on par with white-box source model adaptation approaches.
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022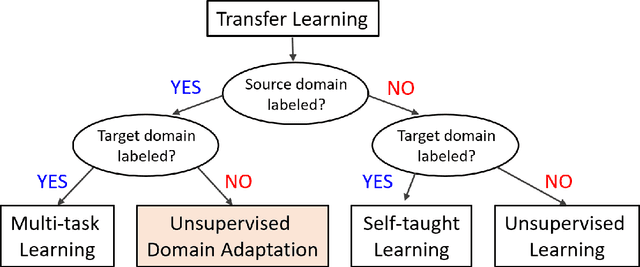

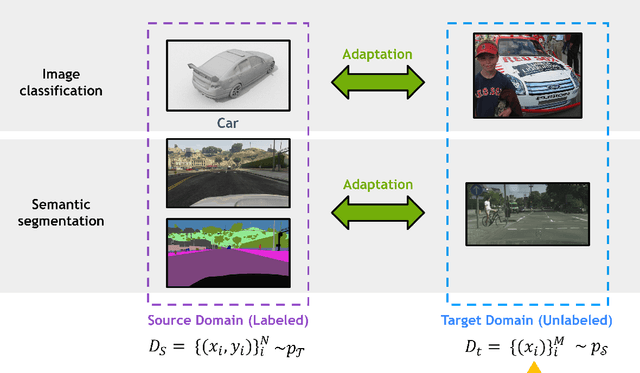

Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.