 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Quantum Architecture Search with Tensor-Train Encoding: Theory and Applications to Signal Processing
Jan 10, 2026We introduce CL-QAS, a continual quantum architecture search framework that mitigates the challenges of costly amplitude encoding and catastrophic forgetting in variational quantum circuits. The method uses Tensor-Train encoding to efficiently compress high-dimensional stochastic signals into low-rank quantum feature representations. A bi-loop learning strategy separates circuit parameter optimization from architecture exploration, while an Elastic Weight Consolidation regularization ensures stability across sequential tasks. We derive theoretical upper bounds on approximation, generalization, and robustness under quantum noise, demonstrating that CL-QAS achieves controllable expressivity, sample-efficient generalization, and smooth convergence without barren plateaus. Empirical evaluations on electrocardiogram (ECG)-based signal classification and financial time-series forecasting confirm substantial improvements in accuracy, balanced accuracy, F1 score, and reward. CL-QAS maintains strong forward and backward transfer and exhibits bounded degradation under depolarizing and readout noise, highlighting its potential for adaptive, noise-resilient quantum learning on near-term devices.
Optimizing Quantum Federated Learning Based on Federated Quantum Natural Gradient Descent
Feb 27, 2023Quantum federated learning (QFL) is a quantum extension of the classical federated learning model across multiple local quantum devices. An efficient optimization algorithm is always expected to minimize the communication overhead among different quantum participants. In this work, we propose an efficient optimization algorithm, namely federated quantum natural gradient descent (FQNGD), and further, apply it to a QFL framework that is composed of a variational quantum circuit (VQC)-based quantum neural networks (QNN). Compared with stochastic gradient descent methods like Adam and Adagrad, the FQNGD algorithm admits much fewer training iterations for the QFL to get converged. Moreover, it can significantly reduce the total communication overhead among local quantum devices. Our experiments on a handwritten digit classification dataset justify the effectiveness of the FQNGD for the QFL framework in terms of a faster convergence rate on the training set and higher accuracy on the test set.
Exploiting Low-Rank Tensor-Train Deep Neural Networks Based on Riemannian Gradient Descent With Illustrations of Speech Processing
Mar 11, 2022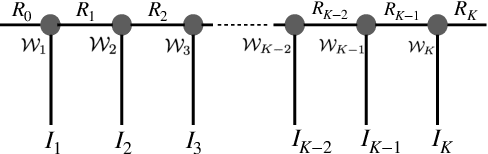
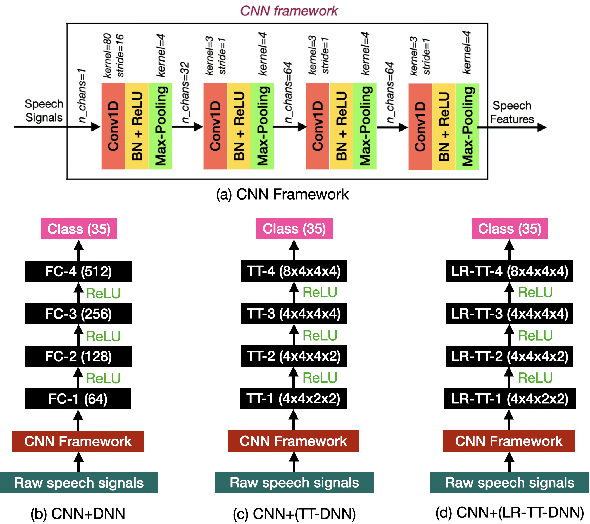
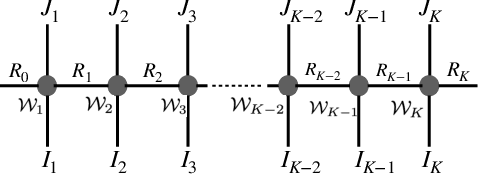
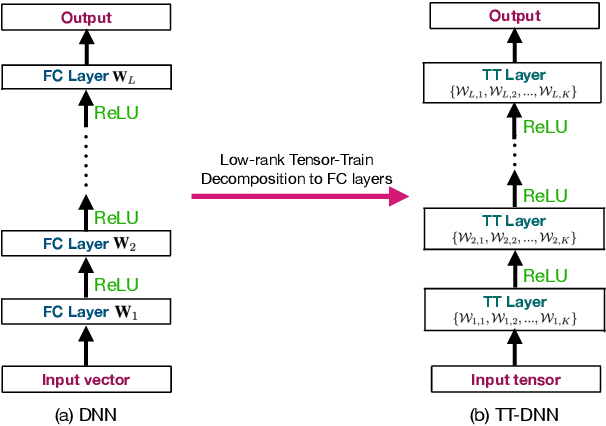
This work focuses on designing low complexity hybrid tensor networks by considering trade-offs between the model complexity and practical performance. Firstly, we exploit a low-rank tensor-train deep neural network (TT-DNN) to build an end-to-end deep learning pipeline, namely LR-TT-DNN. Secondly, a hybrid model combining LR-TT-DNN with a convolutional neural network (CNN), which is denoted as CNN+(LR-TT-DNN), is set up to boost the performance. Instead of randomly assigning large TT-ranks for TT-DNN, we leverage Riemannian gradient descent to determine a TT-DNN associated with small TT-ranks. Furthermore, CNN+(LR-TT-DNN) consists of convolutional layers at the bottom for feature extraction and several TT layers at the top to solve regression and classification problems. We separately assess the LR-TT-DNN and CNN+(LR-TT-DNN) models on speech enhancement and spoken command recognition tasks. Our empirical evidence demonstrates that the LR-TT-DNN and CNN+(LR-TT-DNN) models with fewer model parameters can outperform the TT-DNN and CNN+(TT-DNN) counterparts.
Exploiting Hybrid Models of Tensor-Train Networks for Spoken Command Recognition
Jan 11, 2022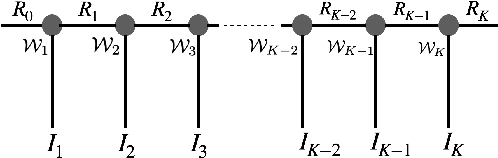
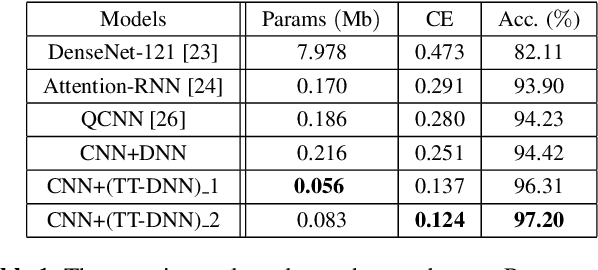
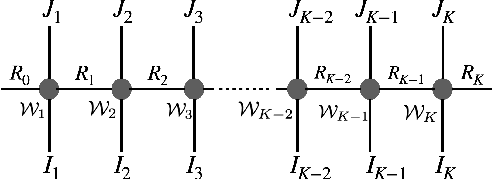
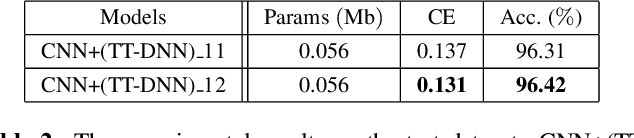
This work aims to design a low complexity spoken command recognition (SCR) system by considering different trade-offs between the number of model parameters and classification accuracy. More specifically, we exploit a deep hybrid architecture of a tensor-train (TT) network to build an end-to-end SRC pipeline. Our command recognition system, namely CNN+(TT-DNN), is composed of convolutional layers at the bottom for spectral feature extraction and TT layers at the top for command classification. Compared with a traditional end-to-end CNN baseline for SCR, our proposed CNN+(TT-DNN) model replaces fully connected (FC) layers with TT ones and it can substantially reduce the number of model parameters while maintaining the baseline performance of the CNN model. We initialize the CNN+(TT-DNN) model in a randomized manner or based on a well-trained CNN+DNN, and assess the CNN+(TT-DNN) models on the Google Speech Command Dataset. Our experimental results show that the proposed CNN+(TT-DNN) model attains a competitive accuracy of 96.31% with 4 times fewer model parameters than the CNN model. Furthermore, the CNN+(TT-DNN) model can obtain a 97.2% accuracy when the number of parameters is increased.
Classical-to-Quantum Transfer Learning for Spoken Command Recognition Based on Quantum Neural Networks
Oct 17, 2021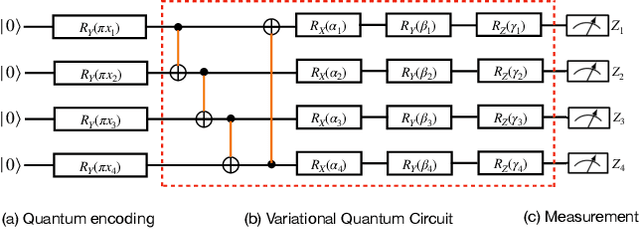

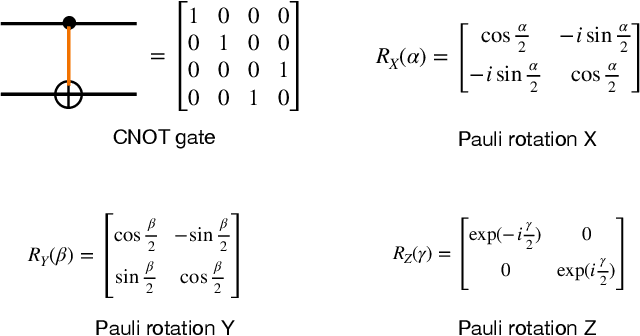
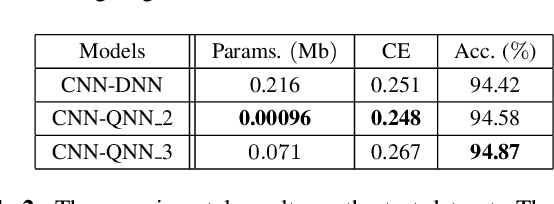
This work investigates an extension of transfer learning applied in machine learning algorithms to the emerging hybrid end-to-end quantum neural network (QNN) for spoken command recognition (SCR). Our QNN-based SCR system is composed of classical and quantum components: (1) the classical part mainly relies on a 1D convolutional neural network (CNN) to extract speech features; (2) the quantum part is built upon the variational quantum circuit with a few learnable parameters. Since it is inefficient to train the hybrid end-to-end QNN from scratch on a noisy intermediate-scale quantum (NISQ) device, we put forth a hybrid transfer learning algorithm that allows a pre-trained classical network to be transferred to the classical part of the hybrid QNN model. The pre-trained classical network is further modified and augmented through jointly fine-tuning with a variational quantum circuit (VQC). The hybrid transfer learning methodology is particularly attractive for the task of QNN-based SCR because low-dimensional classical features are expected to be encoded into quantum states. We assess the hybrid transfer learning algorithm applied to the hybrid classical-quantum QNN for SCR on the Google speech command dataset, and our classical simulation results suggest that the hybrid transfer learning can boost our baseline performance on the SCR task.
Variational Inference-Based Dropout in Recurrent Neural Networks for Slot Filling in Spoken Language Understanding
Aug 23, 2020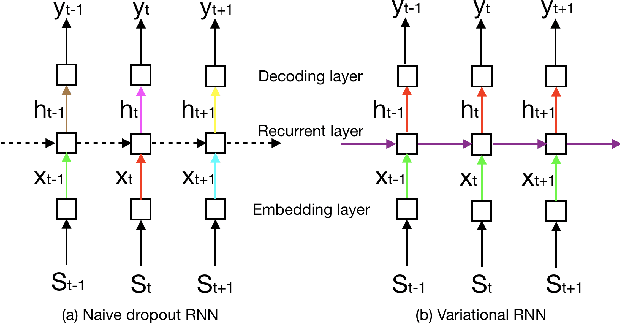
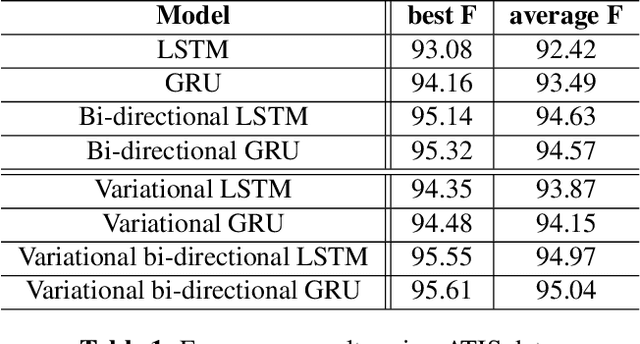
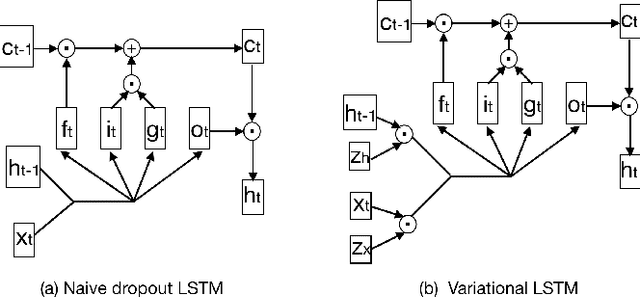

This paper proposes to generalize the variational recurrent neural network (RNN) with variational inference (VI)-based dropout regularization employed for the long short-term memory (LSTM) cells to more advanced RNN architectures like gated recurrent unit (GRU) and bi-directional LSTM/GRU. The new variational RNNs are employed for slot filling, which is an intriguing but challenging task in spoken language understanding. The experiments on the ATIS dataset suggest that the variational RNNs with the VI-based dropout regularization can significantly improve the naive dropout regularization RNNs-based baseline systems in terms of F-measure. Particularly, the variational RNN with bi-directional LSTM/GRU obtains the best F-measure score.
Submodular Rank Aggregation on Score-based Permutations for Distributed Automatic Speech Recognition
Jan 27, 2020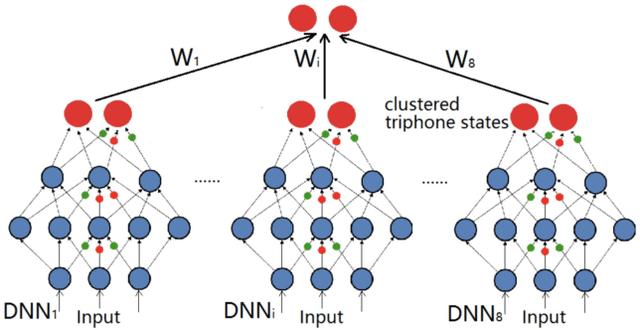
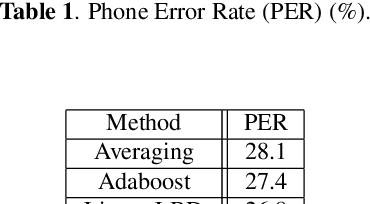
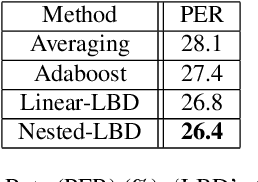
Distributed automatic speech recognition (ASR) requires to aggregate outputs of distributed deep neural network (DNN)-based models. This work studies the use of submodular functions to design a rank aggregation on score-based permutations, which can be used for distributed ASR systems in both supervised and unsupervised modes. Specifically, we compose an aggregation rank function based on the Lovasz Bregman divergence for setting up linear structured convex and nested structured concave functions. The algorithm is based on stochastic gradient descent (SGD) and can obtain well-trained aggregation models. Our experiments on the distributed ASR system show that the submodular rank aggregation can obtain higher speech recognition accuracy than traditional aggregation methods like Adaboost. Code is available online~\footnote{https://github.com/uwjunqi/Subrank}.
* Accepted to ICASSP 2020. Please download the pdf to view Figure 1. arXiv admin note: substantial text overlap with arXiv:1707.01166
Unsupervised Submodular Rank Aggregation on Score-based Permutations
Sep 06, 2017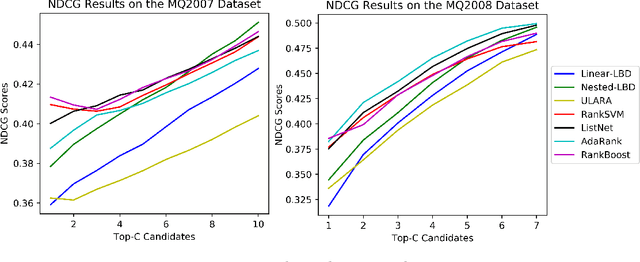
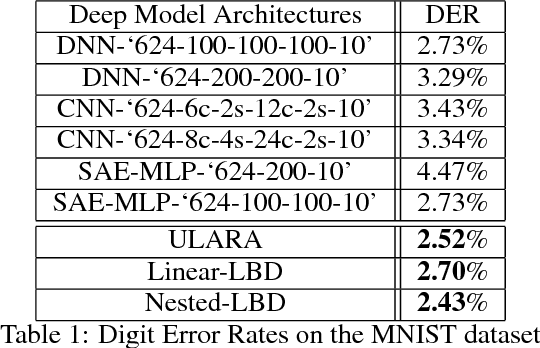
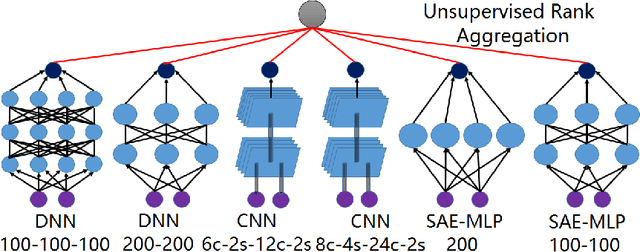
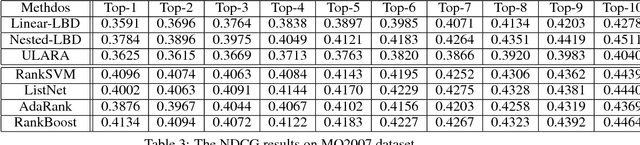
Unsupervised rank aggregation on score-based permutations, which is widely used in many applications, has not been deeply explored yet. This work studies the use of submodular optimization for rank aggregation on score-based permutations in an unsupervised way. Specifically, we propose an unsupervised approach based on the Lovasz Bregman divergence for setting up linear structured convex and nested structured concave objective functions. In addition, stochastic optimization methods are applied in the training process and efficient algorithms for inference can be guaranteed. The experimental results from Information Retrieval, Combining Distributed Neural Networks, Influencers in Social Networks, and Distributed Automatic Speech Recognition tasks demonstrate the effectiveness of the proposed methods.