 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Hybrid Models of Tensor-Train Networks for Spoken Command Recognition
Paper and Code
Jan 11, 2022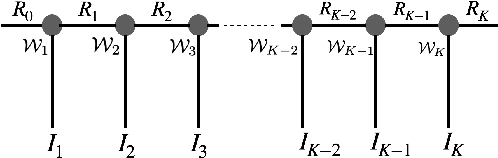
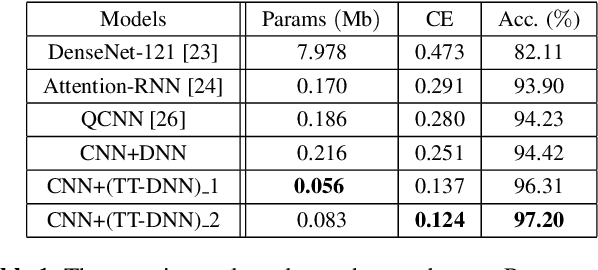
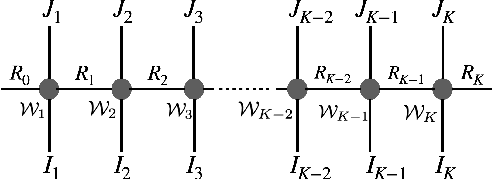
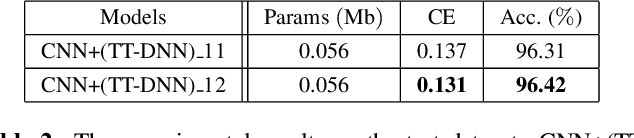
This work aims to design a low complexity spoken command recognition (SCR) system by considering different trade-offs between the number of model parameters and classification accuracy. More specifically, we exploit a deep hybrid architecture of a tensor-train (TT) network to build an end-to-end SRC pipeline. Our command recognition system, namely CNN+(TT-DNN), is composed of convolutional layers at the bottom for spectral feature extraction and TT layers at the top for command classification. Compared with a traditional end-to-end CNN baseline for SCR, our proposed CNN+(TT-DNN) model replaces fully connected (FC) layers with TT ones and it can substantially reduce the number of model parameters while maintaining the baseline performance of the CNN model. We initialize the CNN+(TT-DNN) model in a randomized manner or based on a well-trained CNN+DNN, and assess the CNN+(TT-DNN) models on the Google Speech Command Dataset. Our experimental results show that the proposed CNN+(TT-DNN) model attains a competitive accuracy of 96.31% with 4 times fewer model parameters than the CNN model. Furthermore, the CNN+(TT-DNN) model can obtain a 97.2% accuracy when the number of parameters is increased.