 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Activation Functions: Logit-space equivalents of Boolean Operators
Oct 22, 2021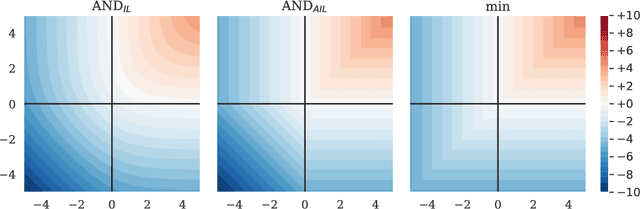
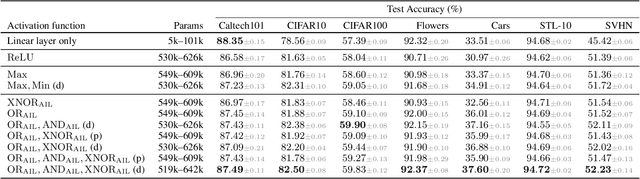
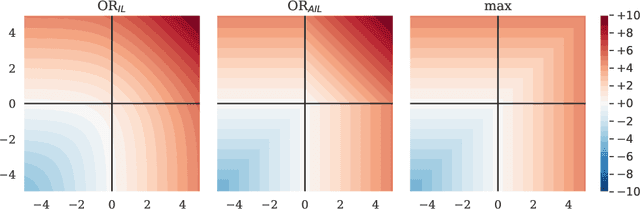
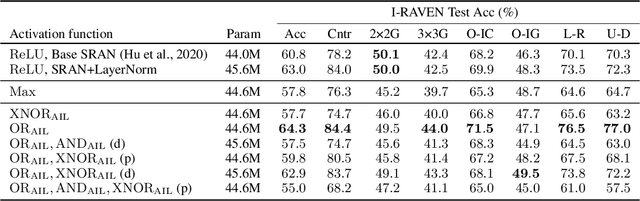
Neuronal representations within artificial neural networks are commonly understood as logits, representing the log-odds score of presence (versus absence) of features within the stimulus. Under this interpretation, we can derive the probability $P(x_0 \land x_1)$ that a pair of independent features are both present in the stimulus from their logits. By converting the resulting probability back into a logit, we obtain a logit-space equivalent of the AND operation. However, since this function involves taking multiple exponents and logarithms, it is not well suited to be directly used within neural networks. We thus constructed an efficient approximation named $\text{AND}_\text{AIL}$ (the AND operator Approximate for Independent Logits) utilizing only comparison and addition operations, which can be deployed as an activation function in neural networks. Like MaxOut, $\text{AND}_\text{AIL}$ is a generalization of ReLU to two-dimensions. Additionally, we constructed efficient approximations of the logit-space equivalents to the OR and XNOR operators. We deployed these new activation functions, both in isolation and in conjunction, and demonstrated their effectiveness on a variety of tasks including image classification, transfer learning, abstract reasoning, and compositional zero-shot learning.
Musical Speech: A Transformer-based Composition Tool
Aug 02, 2021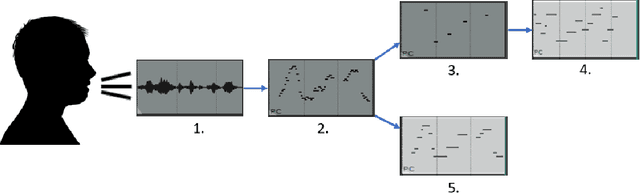
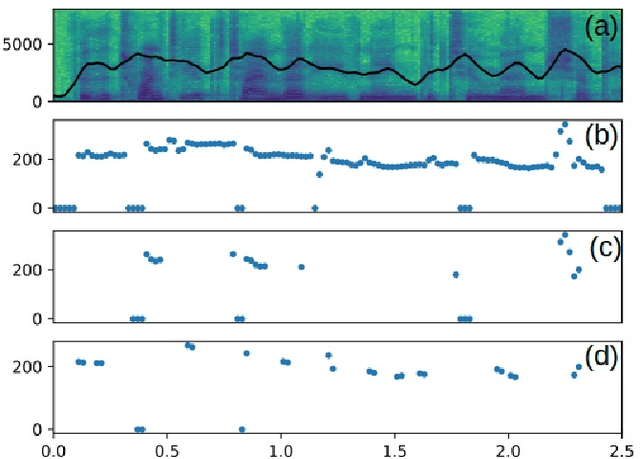
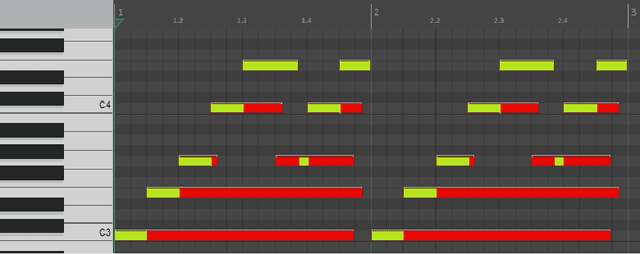
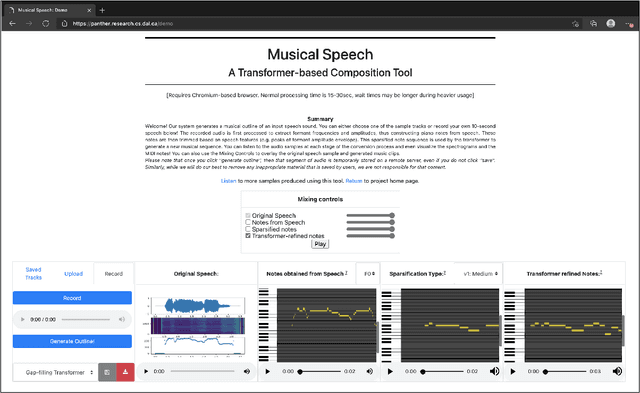
In this paper, we propose a new compositional tool that will generate a musical outline of speech recorded/provided by the user for use as a musical building block in their compositions. The tool allows any user to use their own speech to generate musical material, while still being able to hear the direct connection between their recorded speech and the resulting music. The tool is built on our proposed pipeline. This pipeline begins with speech-based signal processing, after which some simple musical heuristics are applied, and finally these pre-processed signals are passed through Transformer models trained on new musical tasks. We illustrate the effectiveness of our pipeline -- which does not require a paired dataset for training -- through examples of music created by musicians making use of our tool.
The Spotlight: A General Method for Discovering Systematic Errors in Deep Learning Models
Jul 01, 2021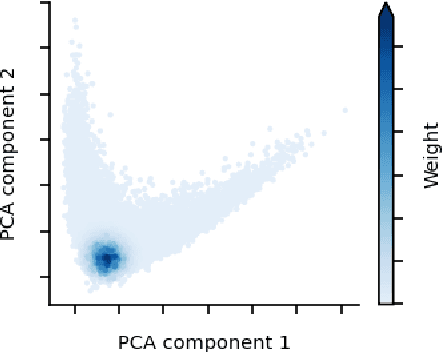


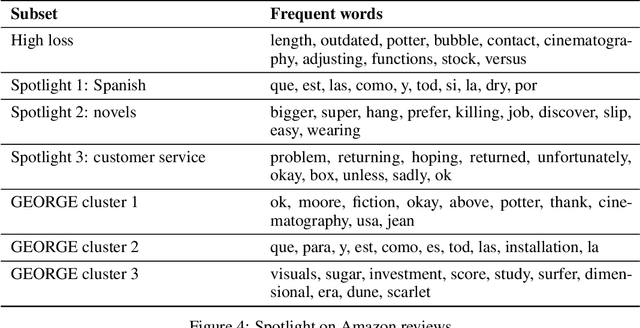
Supervised learning models often make systematic errors on rare subsets of the data. However, such systematic errors can be difficult to identify, as model performance can only be broken down across sensitive groups when these groups are known and explicitly labelled. This paper introduces a method for discovering systematic errors, which we call the spotlight. The key idea is that similar inputs tend to have similar representations in the final hidden layer of a neural network. We leverage this structure by "shining a spotlight" on this representation space to find contiguous regions where the model performs poorly. We show that the spotlight surfaces semantically meaningful areas of weakness in a wide variety of model architectures, including image classifiers, language models, and recommender systems.