 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bid Landscape Forecasting in Real-time Bidding
Jan 18, 2020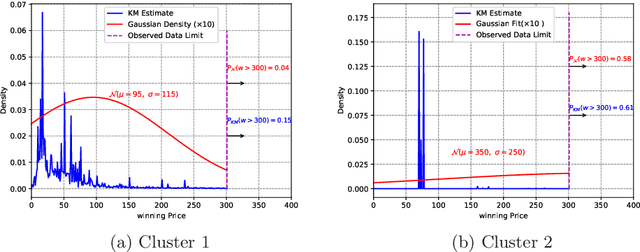
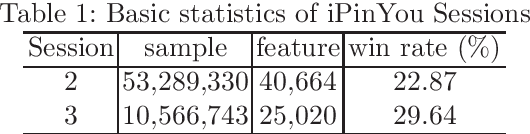
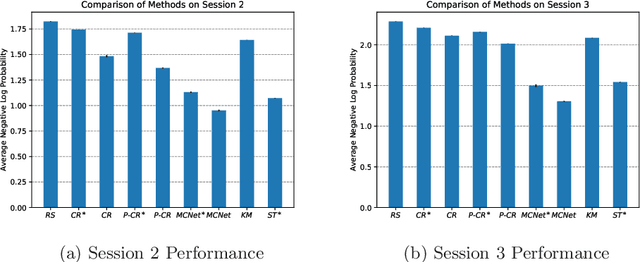
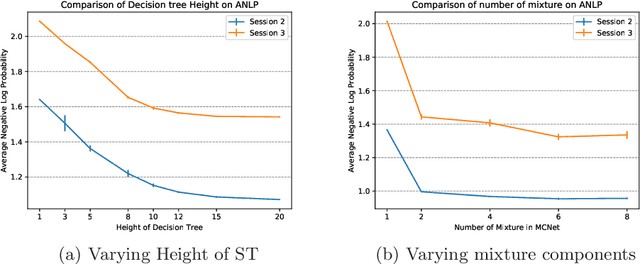
In programmatic advertising, ad slots are usually sold using second-price (SP) auctions in real-time. The highest bidding advertiser wins but pays only the second-highest bid (known as the winning price). In SP, for a single item, the dominant strategy of each bidder is to bid the true value from the bidder's perspective. However, in a practical setting, with budget constraints, bidding the true value is a sub-optimal strategy. Hence, to devise an optimal bidding strategy, it is of utmost importance to learn the winning price distribution accurately. Moreover, a demand-side platform (DSP), which bids on behalf of advertisers, observes the winning price if it wins the auction. For losing auctions, DSPs can only treat its bidding price as the lower bound for the unknown winning price. In literature, typically censored regression is used to model such partially observed data. A common assumption in censored regression is that the winning price is drawn from a fixed variance (homoscedastic) uni-modal distribution (most often Gaussian). However, in reality, these assumptions are often violated. We relax these assumptions and propose a heteroscedastic fully parametric censored regression approach, as well as a mixture density censored network. Our approach not only generalizes censored regression but also provides flexibility to model arbitrarily distributed real-world data. Experimental evaluation on the publicly available dataset for winning price estimation demonstrates the effectiveness of our method. Furthermore, we evaluate our algorithm on one of the largest demand-side platforms and significant improvement has been achieved in comparison with the baseline solutions.
Synthesizing Novel Pairs of Image and Text
Dec 18, 2017
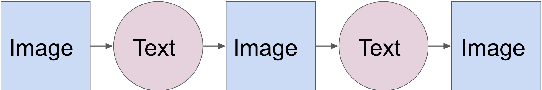

Generating novel pairs of image and text is a problem that combines computer vision and natural language processing. In this paper, we present strategies for generating novel image and caption pairs based on existing captioning datasets. The model takes advantage of recent advances in generative adversarial networks and sequence-to-sequence modeling. We make generalizations to generate paired samples from multiple domains. Furthermore, we study cycles -- generating from image to text then back to image and vise versa, as well as its connection with autoencoders.