Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Novel Pairs of Image and Text
Dec 18, 2017
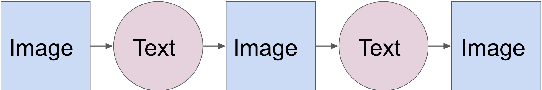

Generating novel pairs of image and text is a problem that combines computer vision and natural language processing. In this paper, we present strategies for generating novel image and caption pairs based on existing captioning datasets. The model takes advantage of recent advances in generative adversarial networks and sequence-to-sequence modeling. We make generalizations to generate paired samples from multiple domains. Furthermore, we study cycles -- generating from image to text then back to image and vise versa, as well as its connection with autoencoders.
Via