 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAverage shortest-path length in word-adjacency networks: Chinese versus English
Jan 10, 2026Complex networks provide powerful tools for analyzing and understanding the intricate structures present in various systems, including natural language. Here, we analyze topology of growing word-adjacency networks constructed from Chinese and English literary works written in different periods. Unconventionally, instead of considering dictionary words only, we also include punctuation marks as if they were ordinary words. Our approach is based on two arguments: (1) punctuation carries genuine information related to emotional state, allows for logical grouping of content, provides a pause in reading, and facilitates understanding by avoiding ambiguity, and (2) our previous works have shown that punctuation marks behave like words in a Zipfian analysis and, if considered together with regular words, can improve authorship attribution in stylometric studies. We focus on a functional dependence of the average shortest path length $L(N)$ on a network size $N$ for different epochs and individual novels in their original language as well as for translations of selected novels into the other language. We approximate the empirical results with a growing network model and obtain satisfactory agreement between the two. We also observe that $L(N)$ behaves asymptotically similar for both languages if punctuation marks are included but becomes sizably larger for Chinese if punctuation marks are neglected.
Quantifying patterns of punctuation in modern Chinese prose
Mar 06, 2025Recent research shows that punctuation patterns in texts exhibit universal features across languages. Analysis of Western classical literature reveals that the distribution of spaces between punctuation marks aligns with a discrete Weibull distribution, typically used in survival analysis. By extending this analysis to Chinese literature represented here by three notable contemporary works, it is shown that Zipf's law applies to Chinese texts similarly to Western texts, where punctuation patterns also improve adherence to the law. Additionally, the distance distribution between punctuation marks in Chinese texts follows the Weibull model, though larger spacing is less frequent than in English translations. Sentence-ending punctuation, representing sentence length, diverges more from this pattern, reflecting greater flexibility in sentence length. This variability supports the formation of complex, multifractal sentence structures, particularly evident in Gao Xingjian's "Soul Mountain". These findings demonstrate that both Chinese and Western texts share universal punctuation and word distribution patterns, underscoring their broad applicability across languages.
Statistics of punctuation in experimental literature -- the remarkable case of "Finnegans Wake" by James Joyce
Aug 31, 2024



As the recent studies indicate, the structure imposed onto written texts by the presence of punctuation develops patterns which reveal certain characteristics of universality. In particular, based on a large collection of classic literary works, it has been evidenced that the distances between consecutive punctuation marks, measured in terms of the number of words, obey the discrete Weibull distribution - a discrete variant of a distribution often used in survival analysis. The present work extends the analysis of punctuation usage patterns to more experimental pieces of world literature. It turns out that the compliance of the the distances between punctuation marks with the discrete Weibull distribution typically applies here as well. However, some of the works by James Joyce are distinct in this regard - in the sense that the tails of the relevant distributions are significantly thicker and, consequently, the corresponding hazard functions are decreasing functions not observed in typical literary texts in prose. "Finnegans Wake" - the same one to which science owes the word "quarks" for the most fundamental constituents of matter - is particularly striking in this context. At the same time, in all the studied texts, the sentence lengths - representing the distances between sentence-ending punctuation marks - reveal more freedom and are not constrained by the discrete Weibull distribution. This freedom in some cases translates into long-range nonlinear correlations, which manifest themselves in multifractality. Again, a text particularly spectacular in terms of multifractality is "Finnegans Wake".
Complex systems approach to natural language
Jan 05, 2024The review summarizes the main methodological concepts used in studying natural language from the perspective of complexity science and documents their applicability in identifying both universal and system-specific features of language in its written representation. Three main complexity-related research trends in quantitative linguistics are covered. The first part addresses the issue of word frequencies in texts and demonstrates that taking punctuation into consideration restores scaling whose violation in the Zipf's law is often observed for the most frequent words. The second part introduces methods inspired by time series analysis, used in studying various kinds of correlations in written texts. The related time series are generated on the basis of text partition into sentences or into phrases between consecutive punctuation marks. It turns out that these series develop features often found in signals generated by complex systems, like long-range correlations or (multi)fractal structures. Moreover, it appears that the distances between punctuation marks comply with the discrete variant of the Weibull distribution. In the third part, the application of the network formalism to natural language is reviewed, particularly in the context of the so-called word-adjacency networks. Parameters characterizing topology of such networks can be used for classification of texts, for example, from a stylometric perspective. Network approach can also be applied to represent the organization of word associations. Structure of word-association networks turns out to be significantly different from that observed in random networks, revealing genuine properties of language. Finally, punctuation seems to have a significant impact not only on the language's information-carrying ability but also on its key statistical properties, hence it is recommended to consider punctuation marks on a par with words.
* 113 pages, 49 figures
Quantifying origin and character of long-range correlations in narrative texts
Oct 14, 2015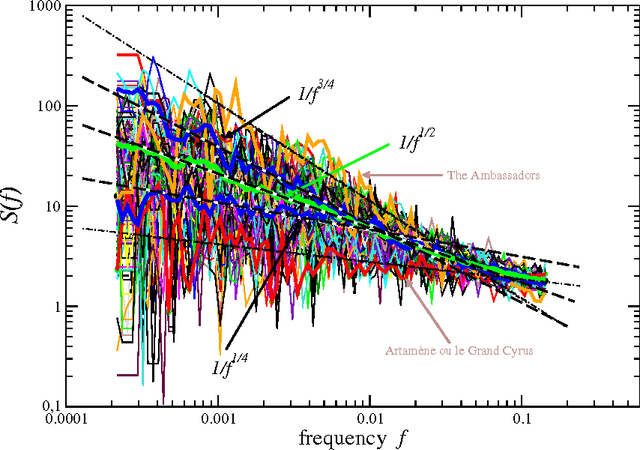
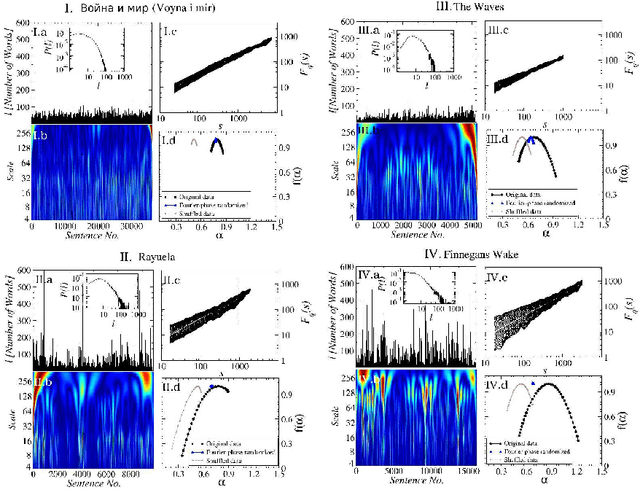
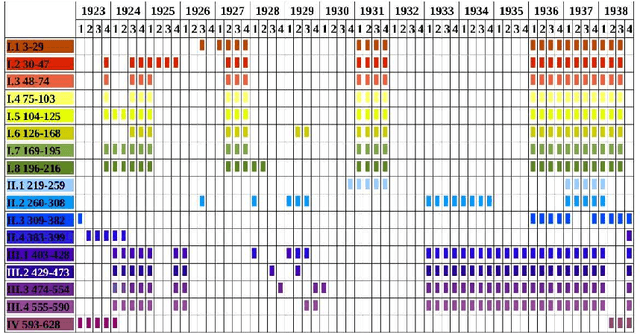
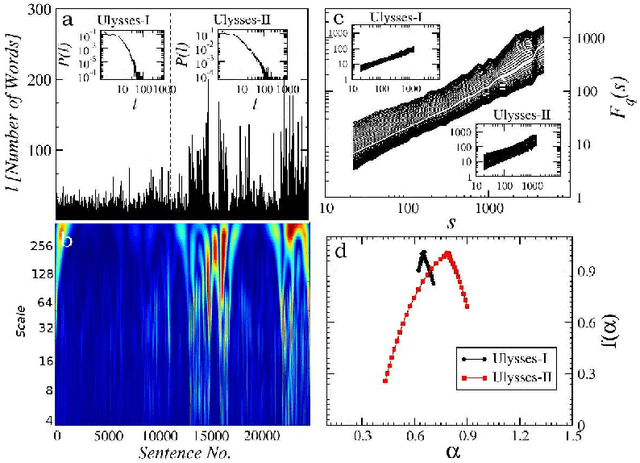
In natural language using short sentences is considered efficient for communication. However, a text composed exclusively of such sentences looks technical and reads boring. A text composed of long ones, on the other hand, demands significantly more effort for comprehension. Studying characteristics of the sentence length variability (SLV) in a large corpus of world-famous literary texts shows that an appealing and aesthetic optimum appears somewhere in between and involves selfsimilar, cascade-like alternation of various lengths sentences. A related quantitative observation is that the power spectra S(f) of thus characterized SLV universally develop a convincing `1/f^beta' scaling with the average exponent beta =~ 1/2, close to what has been identified before in musical compositions or in the brain waves. An overwhelming majority of the studied texts simply obeys such fractal attributes but especially spectacular in this respect are hypertext-like, "stream of consciousness" novels. In addition, they appear to develop structures characteristic of irreducibly interwoven sets of fractals called multifractals. Scaling of S(f) in the present context implies existence of the long-range correlations in texts and appearance of multifractality indicates that they carry even a nonlinear component. A distinct role of the full stops in inducing the long-range correlations in texts is evidenced by the fact that the above quantitative characteristics on the long-range correlations manifest themselves in variation of the full stops recurrence times along texts, thus in SLV, but to a much lesser degree in the recurrence times of the most frequent words. In this latter case the nonlinear correlations, thus multifractality, disappear even completely for all the texts considered. Treated as one extra word, the full stops at the same time appear to obey the Zipfian rank-frequency distribution, however.
* 28 pages, 8 figures, accepted for publication in Information Sciences
Multifractal analysis of sentence lengths in English literary texts
Dec 13, 2012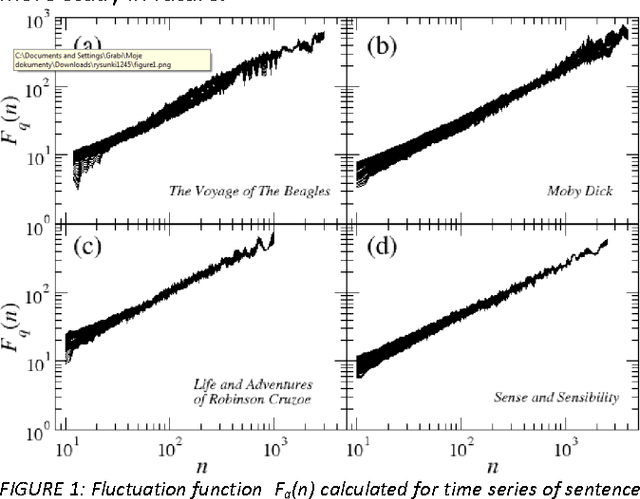
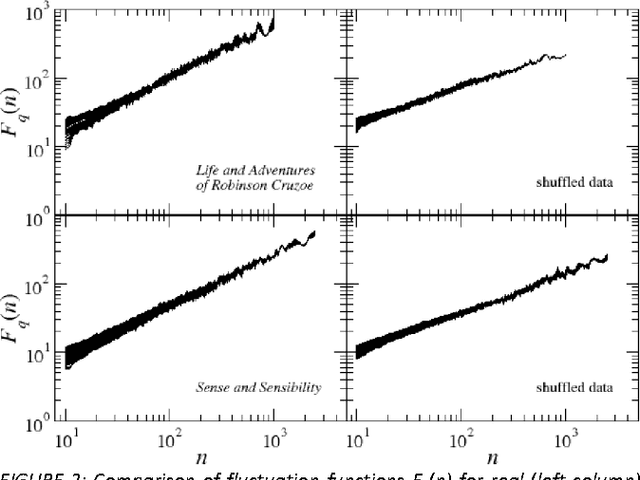
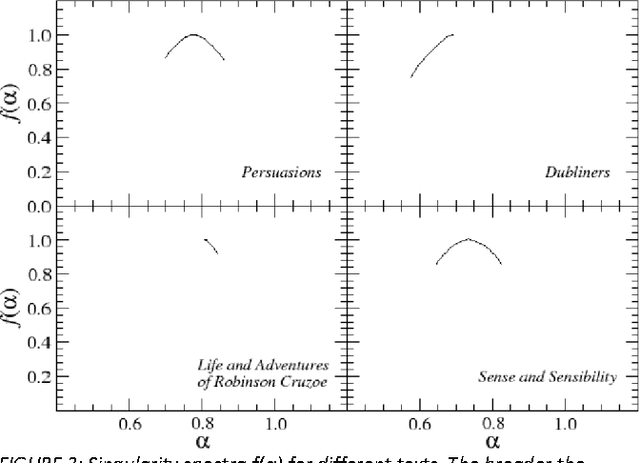
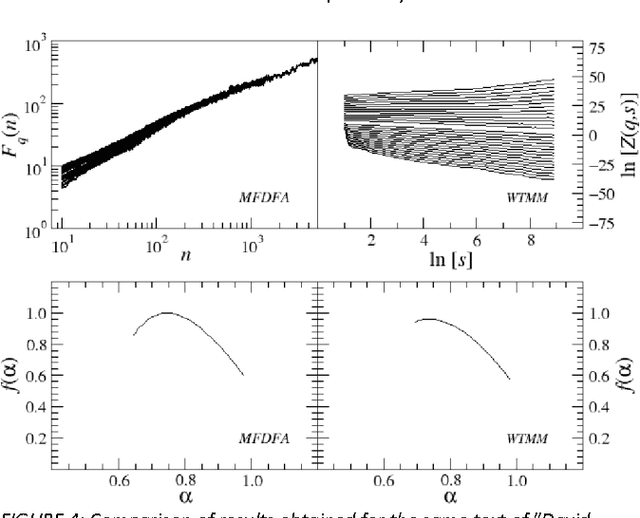
This paper presents analysis of 30 literary texts written in English by different authors. For each text, there were created time series representing length of sentences in words and analyzed its fractal properties using two methods of multifractal analysis: MFDFA and WTMM. Both methods showed that there are texts which can be considered multifractal in this representation but a majority of texts are not multifractal or even not fractal at all. Out of 30 books, only a few have so-correlated lengths of consecutive sentences that the analyzed signals can be interpreted as real multifractals. An interesting direction for future investigations would be identifying what are the specific features which cause certain texts to be multifractal and other to be monofractal or even not fractal at all.
* 5 pages, 5 figures, WCIT 2012 conference