 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylometry recognizes human and LLM-generated texts in short samples
Jul 01, 2025



The paper explores stylometry as a method to distinguish between texts created by Large Language Models (LLMs) and humans, addressing issues of model attribution, intellectual property, and ethical AI use. Stylometry has been used extensively to characterise the style and attribute authorship of texts. By applying it to LLM-generated texts, we identify their emergent writing patterns. The paper involves creating a benchmark dataset based on Wikipedia, with (a) human-written term summaries, (b) texts generated purely by LLMs (GPT-3.5/4, LLaMa 2/3, Orca, and Falcon), (c) processed through multiple text summarisation methods (T5, BART, Gensim, and Sumy), and (d) rephrasing methods (Dipper, T5). The 10-sentence long texts were classified by tree-based models (decision trees and LightGBM) using human-designed (StyloMetrix) and n-gram-based (our own pipeline) stylometric features that encode lexical, grammatical, syntactic, and punctuation patterns. The cross-validated results reached a performance of up to .87 Matthews correlation coefficient in the multiclass scenario with 7 classes, and accuracy between .79 and 1. in binary classification, with the particular example of Wikipedia and GPT-4 reaching up to .98 accuracy on a balanced dataset. Shapley Additive Explanations pinpointed features characteristic of the encyclopaedic text type, individual overused words, as well as a greater grammatical standardisation of LLMs with respect to human-written texts. These results show -- crucially, in the context of the increasingly sophisticated LLMs -- that it is possible to distinguish machine- from human-generated texts at least for a well-defined text type.
Quantifying origin and character of long-range correlations in narrative texts
Oct 14, 2015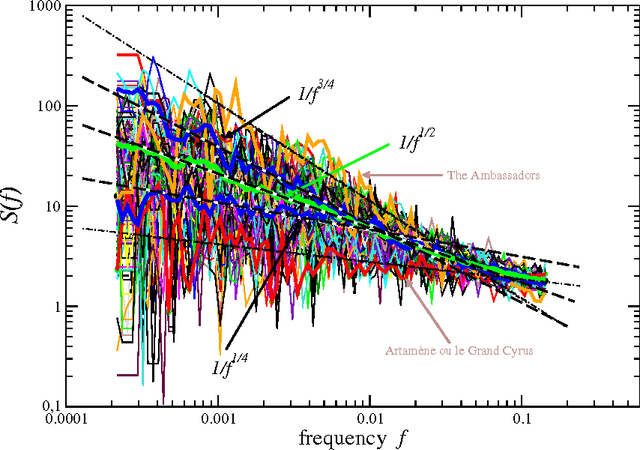
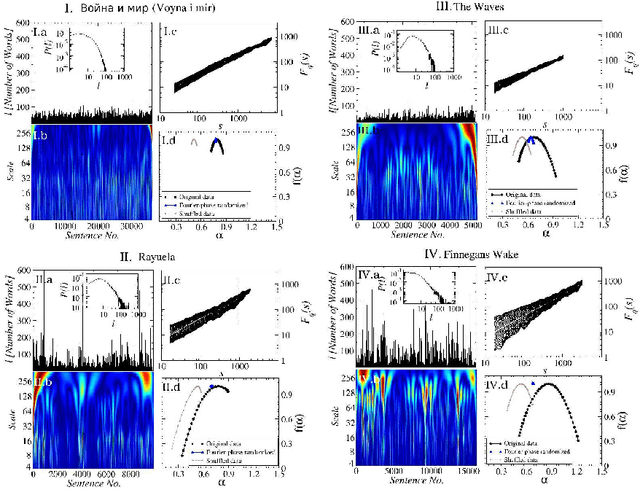
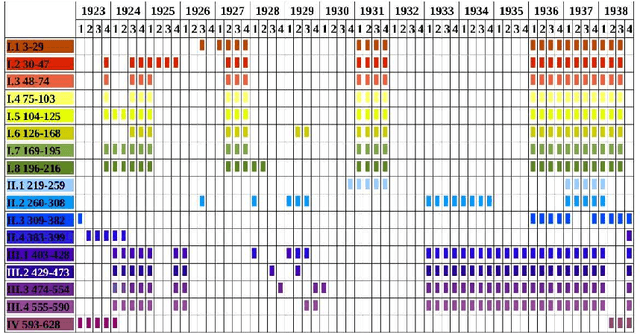
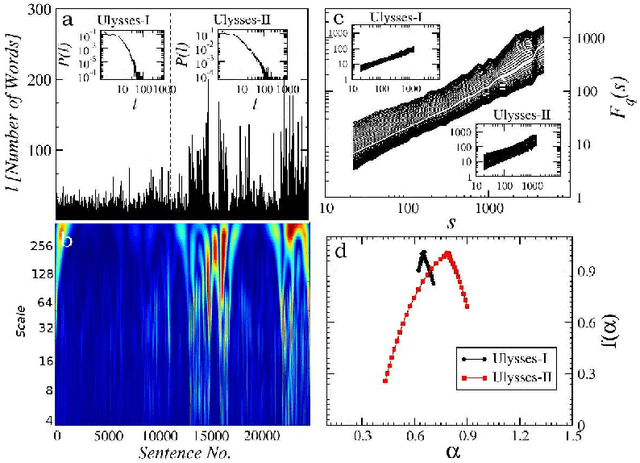
In natural language using short sentences is considered efficient for communication. However, a text composed exclusively of such sentences looks technical and reads boring. A text composed of long ones, on the other hand, demands significantly more effort for comprehension. Studying characteristics of the sentence length variability (SLV) in a large corpus of world-famous literary texts shows that an appealing and aesthetic optimum appears somewhere in between and involves selfsimilar, cascade-like alternation of various lengths sentences. A related quantitative observation is that the power spectra S(f) of thus characterized SLV universally develop a convincing `1/f^beta' scaling with the average exponent beta =~ 1/2, close to what has been identified before in musical compositions or in the brain waves. An overwhelming majority of the studied texts simply obeys such fractal attributes but especially spectacular in this respect are hypertext-like, "stream of consciousness" novels. In addition, they appear to develop structures characteristic of irreducibly interwoven sets of fractals called multifractals. Scaling of S(f) in the present context implies existence of the long-range correlations in texts and appearance of multifractality indicates that they carry even a nonlinear component. A distinct role of the full stops in inducing the long-range correlations in texts is evidenced by the fact that the above quantitative characteristics on the long-range correlations manifest themselves in variation of the full stops recurrence times along texts, thus in SLV, but to a much lesser degree in the recurrence times of the most frequent words. In this latter case the nonlinear correlations, thus multifractality, disappear even completely for all the texts considered. Treated as one extra word, the full stops at the same time appear to obey the Zipfian rank-frequency distribution, however.
* 28 pages, 8 figures, accepted for publication in Information Sciences
Multifractal analysis of sentence lengths in English literary texts
Dec 13, 2012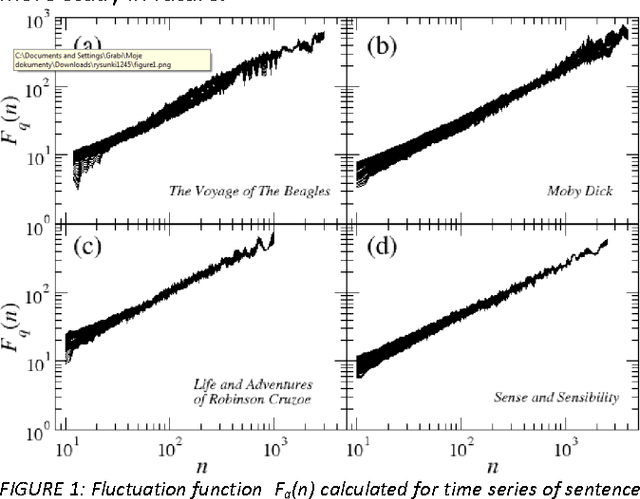
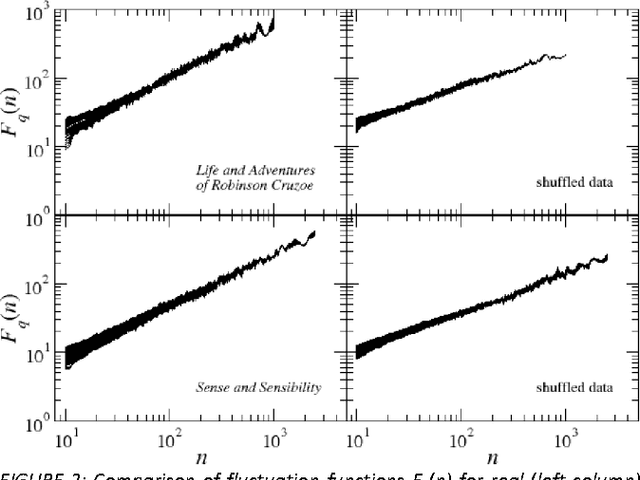
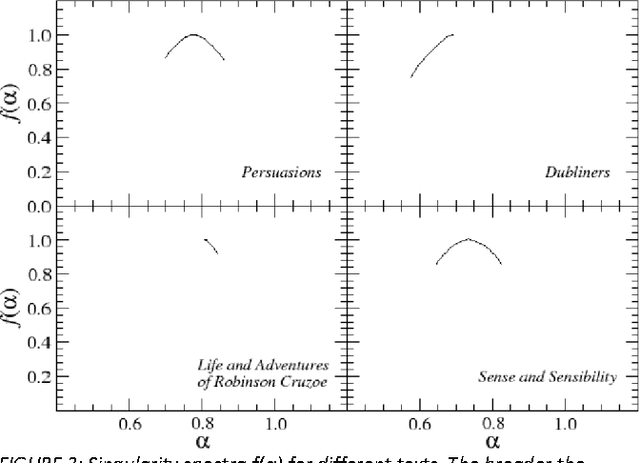
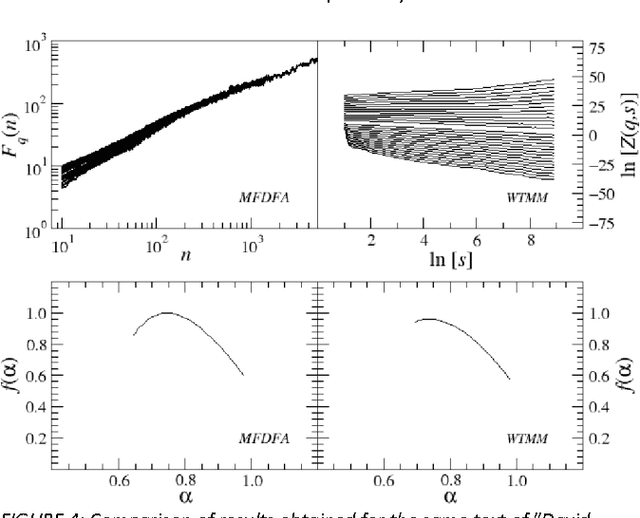
This paper presents analysis of 30 literary texts written in English by different authors. For each text, there were created time series representing length of sentences in words and analyzed its fractal properties using two methods of multifractal analysis: MFDFA and WTMM. Both methods showed that there are texts which can be considered multifractal in this representation but a majority of texts are not multifractal or even not fractal at all. Out of 30 books, only a few have so-correlated lengths of consecutive sentences that the analyzed signals can be interpreted as real multifractals. An interesting direction for future investigations would be identifying what are the specific features which cause certain texts to be multifractal and other to be monofractal or even not fractal at all.
* 5 pages, 5 figures, WCIT 2012 conference