 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultifractal analysis of sentence lengths in English literary texts
Paper and Code
Dec 13, 2012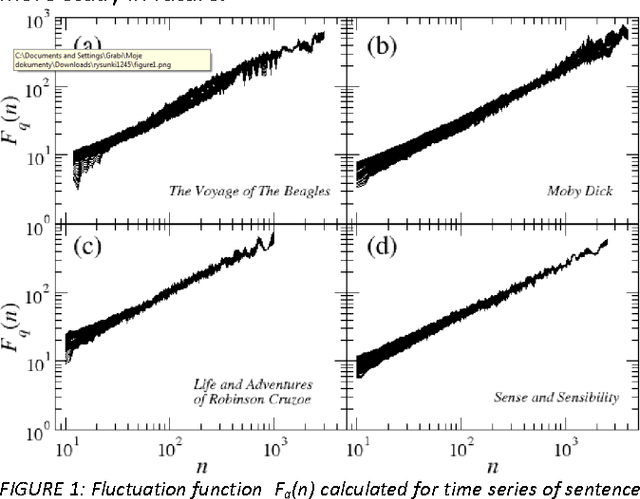
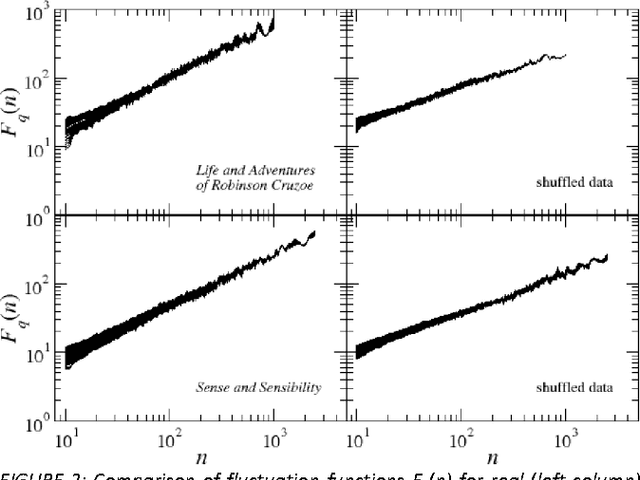
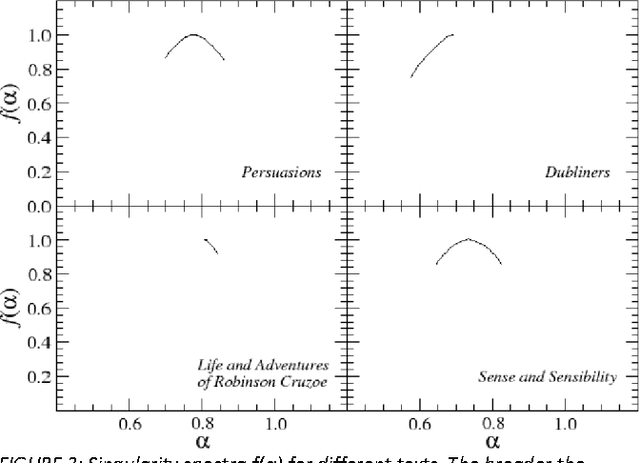
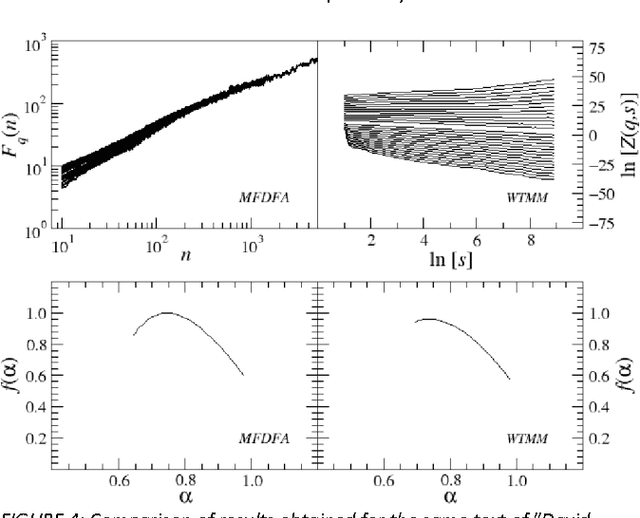
This paper presents analysis of 30 literary texts written in English by different authors. For each text, there were created time series representing length of sentences in words and analyzed its fractal properties using two methods of multifractal analysis: MFDFA and WTMM. Both methods showed that there are texts which can be considered multifractal in this representation but a majority of texts are not multifractal or even not fractal at all. Out of 30 books, only a few have so-correlated lengths of consecutive sentences that the analyzed signals can be interpreted as real multifractals. An interesting direction for future investigations would be identifying what are the specific features which cause certain texts to be multifractal and other to be monofractal or even not fractal at all.