 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRatio Covers of Convex Sets and Optimal Mixture Density Estimation
Feb 18, 2026We study density estimation in Kullback-Leibler divergence: given an i.i.d. sample from an unknown density $p$, the goal is to construct an estimator $\widehat p$ such that $\mathrm{KL}(p,\widehat p)$ is small with high probability. We consider two settings involving a finite dictionary of $M$ densities: (i) model aggregation, where $p$ belongs to the dictionary, and (ii) convex aggregation (mixture density estimation), where $p$ is a mixture of densities from the dictionary. Crucially, we make no assumption on the base densities: their ratios may be unbounded and their supports may differ. For both problems, we identify the best possible high-probability guarantees in terms of the dictionary size, sample size, and confidence level. These optimal rates are higher than those achievable when density ratios are bounded by absolute constants; for mixture density estimation, they match existing lower bounds in the special case of discrete distributions. Our analysis of the mixture case hinges on two new covering results. First, we provide a sharp, distribution-free upper bound on the local Hellinger entropy of the class of mixtures of $M$ distributions. Second, we prove an optimal ratio covering theorem for convex sets: for every convex compact set $K\subset \mathbb{R}_+^d$, there exists a subset $A\subset K$ with at most $2^{8d}$ elements such that each element of $K$ is coordinate-wise dominated by an element of $A$ up to a universal constant factor. This geometric result is of independent interest; notably, it yields new cardinality estimates for $\varepsilon$-approximate Pareto sets in multi-objective optimization when the attainable set of objective vectors is convex.
Estimation of discrete distributions in relative entropy, and the deviations of the missing mass
Apr 30, 2025We study the problem of estimating a distribution over a finite alphabet from an i.i.d. sample, with accuracy measured in relative entropy (Kullback-Leibler divergence). While optimal expected risk bounds are known, high-probability guarantees remain less well-understood. First, we analyze the classical Laplace (add-$1$) estimator, obtaining matching upper and lower bounds on its performance and showing its optimality among confidence-independent estimators. We then characterize the minimax-optimal high-probability risk achievable by any estimator, which is attained via a simple confidence-dependent smoothing technique. Interestingly, the optimal non-asymptotic risk contains an additional logarithmic factor over the ideal asymptotic risk. Next, motivated by scenarios where the alphabet exceeds the sample size, we investigate methods that adapt to the sparsity of the distribution at hand. We introduce an estimator using data-dependent smoothing, for which we establish a high-probability risk bound depending on two effective sparsity parameters. As part of the analysis, we also derive a sharp high-probability upper bound on the missing mass.
Finite-sample performance of the maximum likelihood estimator in logistic regression
Nov 04, 2024Logistic regression is a classical model for describing the probabilistic dependence of binary responses to multivariate covariates. We consider the predictive performance of the maximum likelihood estimator (MLE) for logistic regression, assessed in terms of logistic risk. We consider two questions: first, that of the existence of the MLE (which occurs when the dataset is not linearly separated), and second that of its accuracy when it exists. These properties depend on both the dimension of covariates and on the signal strength. In the case of Gaussian covariates and a well-specified logistic model, we obtain sharp non-asymptotic guarantees for the existence and excess logistic risk of the MLE. We then generalize these results in two ways: first, to non-Gaussian covariates satisfying a certain two-dimensional margin condition, and second to the general case of statistical learning with a possibly misspecified logistic model. Finally, we consider the case of a Bernoulli design, where the behavior of the MLE is highly sensitive to the parameter direction.
Local Risk Bounds for Statistical Aggregation
Jun 29, 2023In the problem of aggregation, the aim is to combine a given class of base predictors to achieve predictions nearly as accurate as the best one. In this flexible framework, no assumption is made on the structure of the class or the nature of the target. Aggregation has been studied in both sequential and statistical contexts. Despite some important differences between the two problems, the classical results in both cases feature the same global complexity measure. In this paper, we revisit and tighten classical results in the theory of aggregation in the statistical setting by replacing the global complexity with a smaller, local one. Some of our proofs build on the PAC-Bayes localization technique introduced by Catoni. Among other results, we prove localized versions of the classical bound for the exponential weights estimator due to Leung and Barron and deviation-optimal bounds for the Q-aggregation estimator. These bounds improve over the results of Dai, Rigollet and Zhang for fixed design regression and the results of Lecu\'e and Rigollet for random design regression.
Universal coding, intrinsic volumes, and metric complexity
Mar 13, 2023We study sequential probability assignment in the Gaussian setting, where the goal is to predict, or equivalently compress, a sequence of real-valued observations almost as well as the best Gaussian distribution with mean constrained to a given subset of $\mathbf{R}^n$. First, in the case of a convex constraint set $K$, we express the hardness of the prediction problem (the minimax regret) in terms of the intrinsic volumes of $K$; specifically, it equals the logarithm of the Wills functional from convex geometry. We then establish a comparison inequality for the Wills functional in the general nonconvex case, which underlines the metric nature of this quantity and generalizes the Slepian-Sudakov-Fernique comparison principle for the Gaussian width. Motivated by this inequality, we characterize the exact order of magnitude of the considered functional for a general nonconvex set, in terms of global covering numbers and local Gaussian widths. This implies metric isomorphic estimates for the log-Laplace transform of the intrinsic volume sequence of a convex body. As part of our analysis, we also characterize the minimax redundancy for a general constraint set. We finally relate and contrast our findings with classical asymptotic results in information theory.
An elementary analysis of ridge regression with random design
Mar 16, 2022In this short note, we present an elementary analysis of the prediction error of ridge regression with random design. The proof is short and self-contained. In particular, it avoids matrix concentration or control of empirical processes, by using a simple combination of exchangeability arguments, matrix identities and operator convexity.
Distribution-Free Robust Linear Regression
Feb 25, 2021We study random design linear regression with no assumptions on the distribution of the covariates and with a heavy-tailed response variable. When learning without assumptions on the covariates, we establish boundedness of the conditional second moment of the response variable as a necessary and sufficient condition for achieving deviation-optimal excess risk rate of convergence. In particular, combining the ideas of truncated least squares, median-of-means procedures and aggregation theory, we construct a non-linear estimator achieving excess risk of order $d/n$ with the optimal sub-exponential tail. While the existing approaches to learning linear classes under heavy-tailed distributions focus on proper estimators, we highlight that the improperness of our estimator is necessary for attaining non-trivial guarantees in the distribution-free setting considered in this work. Finally, as a byproduct of our analysis, we prove an optimal version of the classical bound for the truncated least squares estimator due to Gy\"{o}rfi, Kohler, Krzyzak, and Walk.
Regularized ERM on random subspaces
Jun 17, 2020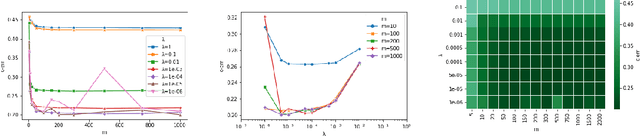
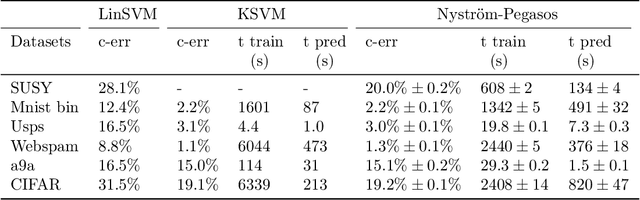
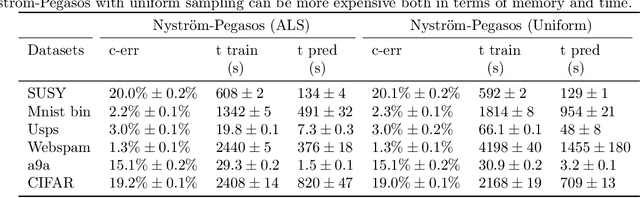
We study a natural extension of classical empirical risk minimization, where the hypothesis space is a random subspace of a given space. In particular, we consider possibly data dependent subspaces spanned by a random subset of the data. This approach naturally leads to computational savings, but the question is whether the corresponding learning accuracy is degraded. These statistical-computational tradeoffs have been recently explored for the least squares loss and self-concordant loss functions, such as the logistic loss. Here, we work to extend these results to convex Lipschitz loss functions, that might not be smooth, such as the hinge loss used in support vector machines. Our main results show the existence of different regimes, depending on how hard the learning problem is, for which computational efficiency can be improved with no loss in performance. Theoretical results are complemented with numerical experiments on large scale benchmark data sets.
Asymptotics of Ridge(less) Regression under General Source Condition
Jun 11, 2020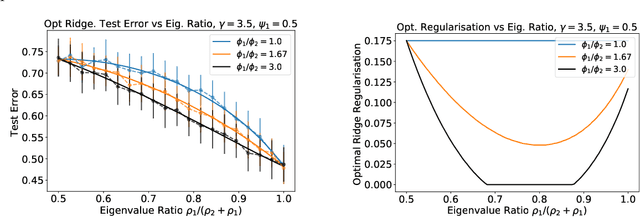
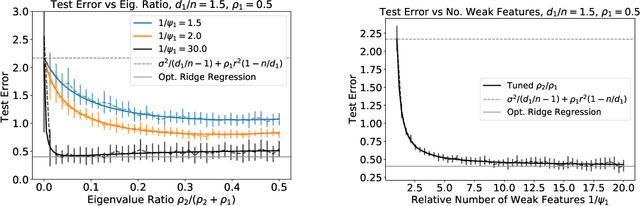
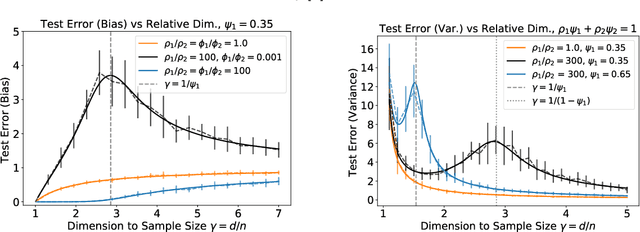
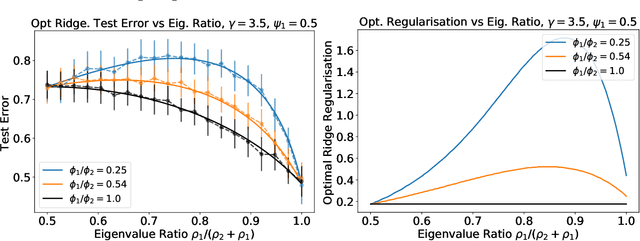
We analyze the prediction performance of ridge and ridgeless regression when both the number and the dimension of the data go to infinity. In particular, we consider a general setting introducing prior assumptions characterizing "easy" and "hard" learning problems. In this setting, we show that ridgeless (zero regularisation) regression is optimal for easy problems with a high signal to noise. Furthermore, we show that additional descents in the ridgeless bias and variance learning curve can occur beyond the interpolating threshold, verifying recent empirical observations. More generally, we show how a variety of learning curves are possible depending on the problem at hand. From a technical point of view, characterising the influence of prior assumptions requires extending previous applications of random matrix theory to study ridge regression.
An improper estimator with optimal excess risk in misspecified density estimation and logistic regression
Dec 23, 2019We introduce a procedure for predictive conditional density estimation under logarithmic loss, which we call SMP (Sample Minmax Predictor). This predictor minimizes a new general excess risk bound, which critically remains valid under model misspecification. On standard examples, this bound scales as $d/n$ where $d$ is the dimension of the model and $n$ the sample size, regardless of the true distribution. The SMP, which is an improper (out-of-model) procedure, improves over proper (within-model) estimators (such as the maximum likelihood estimator), whose excess risk can degrade arbitrarily in the misspecified case. For density estimation, our bounds improve over approaches based on online-to-batch conversion, by removing suboptimal $\log n$ factors, addressing an open problem from Gr{\"u}nwald and Kot{\l}owski (2011) for the considered models. For the Gaussian linear model, the SMP admits an explicit expression, and its expected excess risk in the general misspecified case is at most twice the minimax excess risk in the \emph{well-specified case}, but without any condition on the noise variance or approximation error of the linear model. For logistic regression, a penalized SMP can be computed efficiently by training two logistic regressions, and achieves a non-asymptotic excess risk of $O((d + B^2R^2)/n)$, where $R$ is a bound on the norm of the features and $B$ the norm of the comparison linear predictor. This improves the rates of proper (within-model) estimators, since such procedures can achieve no better rate than $\min(BR/\sqrt{n},de^{BR}/n)$ in general. This also provides a computationally more efficient alternative to approaches based on online-to-batch conversion of Bayesian mixture procedures, which require approximate posterior sampling, thereby partly answering a question by Foster et al. (2018).