 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Medical Image Segmentation With Soft Labels and Noise Robust Loss
Sep 16, 2022
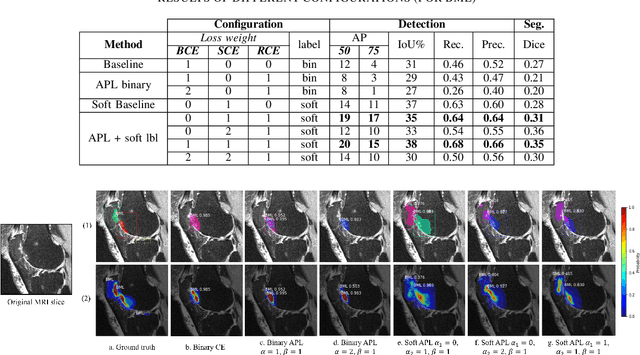
Recent advances in deep learning algorithms have led to significant benefits for solving many medical image analysis problems. Training deep learning models commonly requires large datasets with expert-labeled annotations. However, acquiring expert-labeled annotation is not only expensive but also is subjective, error-prone, and inter-/intra- observer variability introduces noise to labels. This is particularly a problem when using deep learning models for segmenting medical images due to the ambiguous anatomical boundaries. Image-based medical diagnosis tools using deep learning models trained with incorrect segmentation labels can lead to false diagnoses and treatment suggestions. Multi-rater annotations might be better suited to train deep learning models with small training sets compared to single-rater annotations. The aim of this paper was to develop and evaluate a method to generate probabilistic labels based on multi-rater annotations and anatomical knowledge of the lesion features in MRI and a method to train segmentation models using probabilistic labels using normalized active-passive loss as a "noise-tolerant loss" function. The model was evaluated by comparing it to binary ground truth for 17 knees MRI scans for clinical segmentation and detection of bone marrow lesions (BML). The proposed method successfully improved precision 14, recall 22, and Dice score 8 percent compared to a binary cross-entropy loss function. Overall, the results of this work suggest that the proposed normalized active-passive loss using soft labels successfully mitigated the effects of noisy labels.
Self-Supervised-RCNN for Medical Image Segmentation with Limited Data Annotation
Jul 17, 2022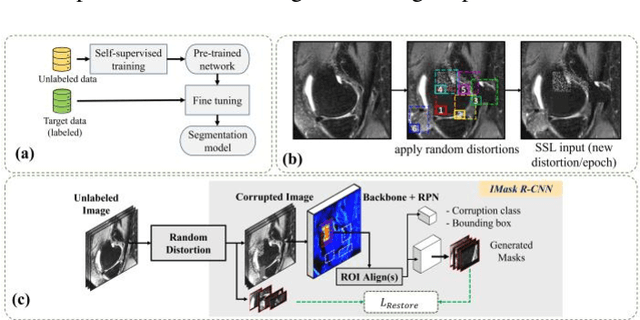
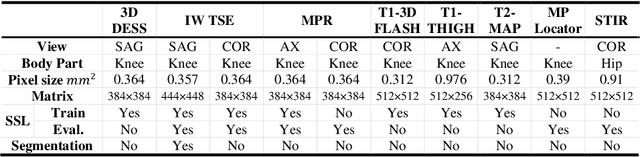
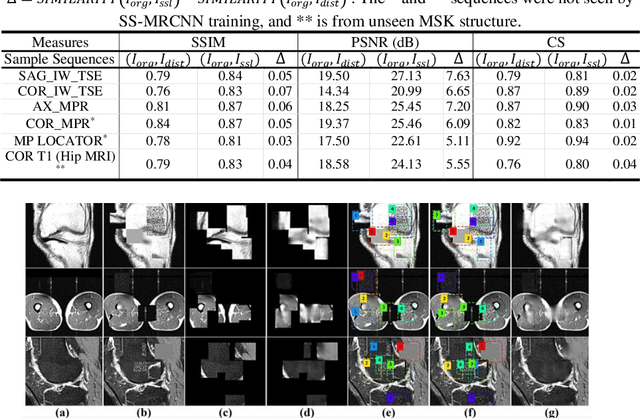
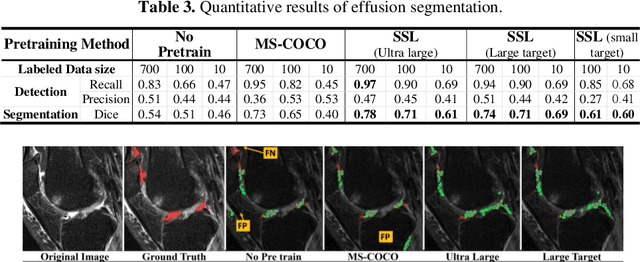
Many successful methods developed for medical image analysis that are based on machine learning use supervised learning approaches, which often require large datasets annotated by experts to achieve high accuracy. However, medical data annotation is time-consuming and expensive, especially for segmentation tasks. To solve the problem of learning with limited labeled medical image data, an alternative deep learning training strategy based on self-supervised pretraining on unlabeled MRI scans is proposed in this work. Our pretraining approach first, randomly applies different distortions to random areas of unlabeled images and then predicts the type of distortions and loss of information. To this aim, an improved version of Mask-RCNN architecture has been adapted to localize the distortion location and recover the original image pixels. The effectiveness of the proposed method for segmentation tasks in different pre-training and fine-tuning scenarios is evaluated based on the Osteoarthritis Initiative dataset. Using this self-supervised pretraining method improved the Dice score by 20% compared to training from scratch. The proposed self-supervised learning is simple, effective, and suitable for different ranges of medical image analysis tasks including anomaly detection, segmentation, and classification.
Improved-Mask R-CNN: Towards an Accurate Generic MSK MRI instance segmentation platform
Jul 27, 2021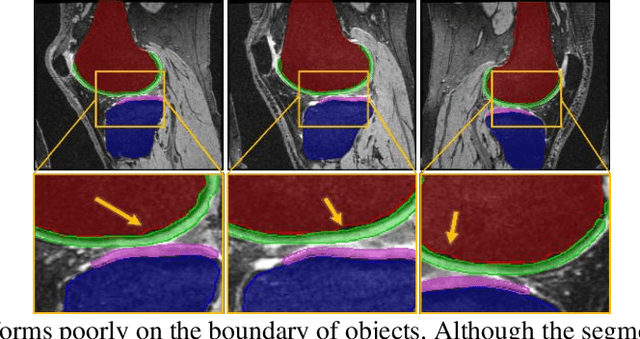
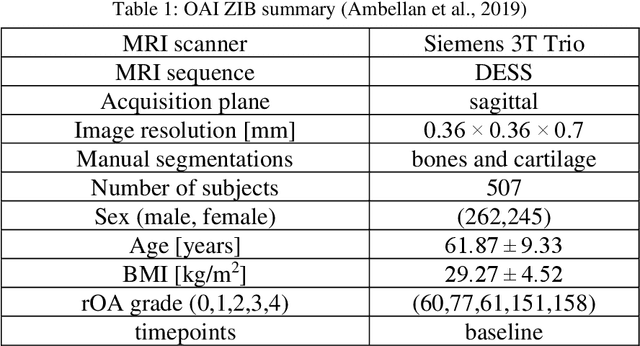
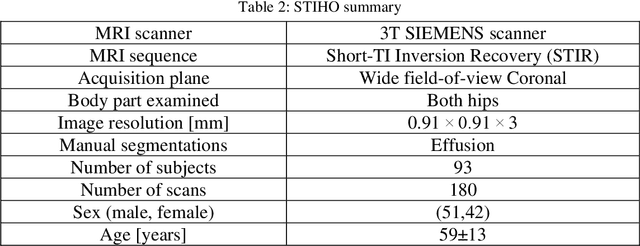
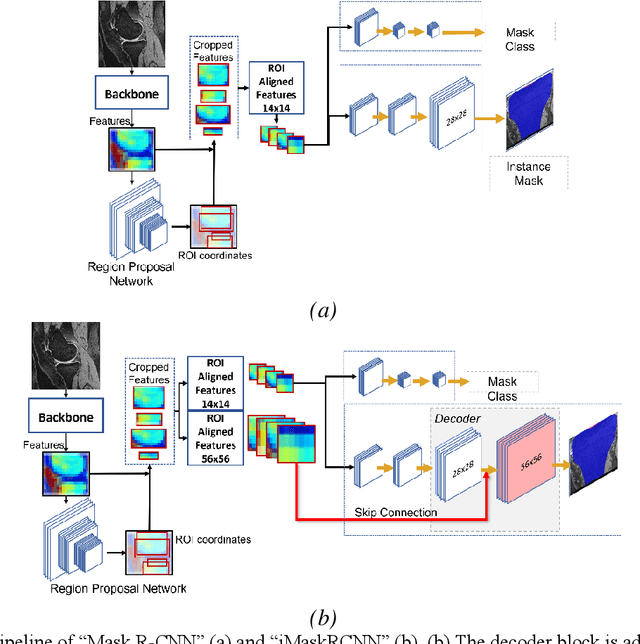
Objective assessment of Magnetic Resonance Imaging (MRI) scans of osteoarthritis (OA) can address the limitation of the current OA assessment. Segmentation of bone, cartilage, and joint fluid is necessary for the OA objective assessment. Most of the proposed segmentation methods are not performing instance segmentation and suffer from class imbalance problems. This study deployed Mask R-CNN instance segmentation and improved it (improved-Mask R-CNN (iMaskRCNN)) to obtain a more accurate generalized segmentation for OA-associated tissues. Training and validation of the method were performed using 500 MRI knees from the Osteoarthritis Initiative (OAI) dataset and 97 MRI scans of patients with symptomatic hip OA. Three modifications to Mask R-CNN yielded the iMaskRCNN: adding a 2nd ROIAligned block, adding an extra decoder layer to the mask-header, and connecting them by a skip connection. The results were assessed using Hausdorff distance, dice score, and coefficients of variation (CoV). The iMaskRCNN led to improved bone and cartilage segmentation compared to Mask RCNN as indicated with the increase in dice score from 95% to 98% for the femur, 95% to 97% for tibia, 71% to 80% for femoral cartilage, and 81% to 82% for tibial cartilage. For the effusion detection, dice improved with iMaskRCNN 72% versus MaskRCNN 71%. The CoV values for effusion detection between Reader1 and Mask R-CNN (0.33), Reader1 and iMaskRCNN (0.34), Reader2 and Mask R-CNN (0.22), Reader2 and iMaskRCNN (0.29) are close to CoV between two readers (0.21), indicating a high agreement between the human readers and both Mask R-CNN and iMaskRCNN. Mask R-CNN and iMaskRCNN can reliably and simultaneously extract different scale articular tissues involved in OA, forming the foundation for automated assessment of OA. The iMaskRCNN results show that the modification improved the network performance around the edges.
Robust Self-Supervised Learning of Deterministic Errors in Single-Plane (Monoplanar) and Dual-Plane (Biplanar) X-ray Fluoroscopy
Jan 03, 2020
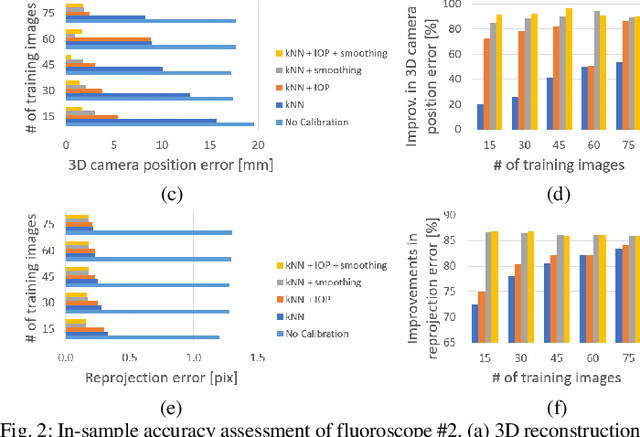
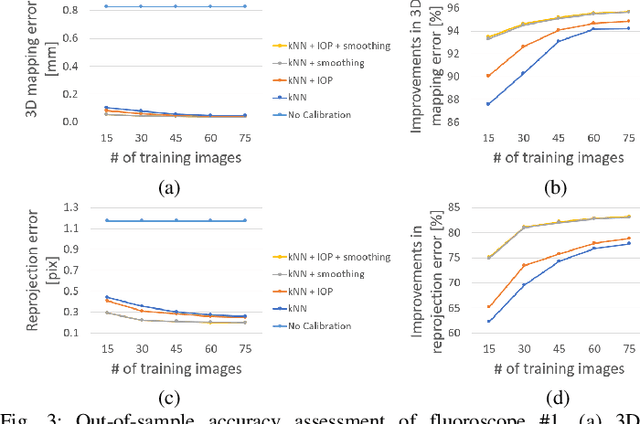

Fluoroscopic imaging that captures X-ray images at video framerates is advantageous for guiding catheter insertions by vascular surgeons and interventional radiologists. Visualizing the dynamical movements non-invasively allows complex surgical procedures to be performed with less trauma to the patient. To improve surgical precision, endovascular procedures can benefit from more accurate fluoroscopy data via calibration. This paper presents a robust self-calibration algorithm suitable for single-plane and dual-plane fluoroscopy. A three-dimensional (3D) target field was imaged by the fluoroscope in a strong geometric network configuration. The unknown 3D positions of targets and the fluoroscope pose were estimated simultaneously by maximizing the likelihood of the Student-t probability distribution function. A smoothed k-nearest neighbour (kNN) regression is then used to model the deterministic component of the image reprojection error of the robust bundle adjustment. The Maximum Likelihood Estimation step and the kNN regression step are then repeated iteratively until convergence. Four different error modeling schemes were compared while varying the quantity of training images. It was found that using a smoothed kNN regression can automatically model the systematic errors in fluoroscopy with similar accuracy as a human expert using a small training dataset. When all training images were used, the 3D mapping error was reduced from 0.61-0.83 mm to 0.04 mm post-calibration (94.2-95.7% improvement), and the 2D reprojection error was reduced from 1.17-1.31 to 0.20-0.21 pixels (83.2-83.8% improvement). When using biplanar fluoroscopy, the 3D measurement accuracy of the system improved from 0.60 mm to 0.32 mm (47.2% improvement).