 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Build AI Agents by Augmenting LLMs with Codified Human Expert Domain Knowledge? A Software Engineering Framework
Jan 21, 2026Critical domain knowledge typically resides with few experts, creating organizational bottlenecks in scalability and decision-making. Non-experts struggle to create effective visualizations, leading to suboptimal insights and diverting expert time. This paper investigates how to capture and embed human domain knowledge into AI agent systems through an industrial case study. We propose a software engineering framework to capture human domain knowledge for engineering AI agents in simulation data visualization by augmenting a Large Language Model (LLM) with a request classifier, Retrieval-Augmented Generation (RAG) system for code generation, codified expert rules, and visualization design principles unified in an agent demonstrating autonomous, reactive, proactive, and social behavior. Evaluation across five scenarios spanning multiple engineering domains with 12 evaluators demonstrates 206% improvement in output quality, with our agent achieving expert-level ratings in all cases versus baseline's poor performance, while maintaining superior code quality with lower variance. Our contributions are: an automated agent-based system for visualization generation and a validated framework for systematically capturing human domain knowledge and codifying tacit expert knowledge into AI agents, demonstrating that non-experts can achieve expert-level outcomes in specialized domains.
AI for Better UX in Computer-Aided Engineering: Is Academia Catching Up with Industry Demands? A Multivocal Literature Review
Jul 22, 2025Computer-Aided Engineering (CAE) enables simulation experts to optimize complex models, but faces challenges in user experience (UX) that limit efficiency and accessibility. While artificial intelligence (AI) has demonstrated potential to enhance CAE processes, research integrating these fields with a focus on UX remains fragmented. This paper presents a multivocal literature review (MLR) examining how AI enhances UX in CAE software across both academic research and industry implementations. Our analysis reveals significant gaps between academic explorations and industry applications, with companies actively implementing LLMs, adaptive UIs, and recommender systems while academic research focuses primarily on technical capabilities without UX validation. Key findings demonstrate opportunities in AI-powered guidance, adaptive interfaces, and workflow automation that remain underexplored in current research. By mapping the intersection of these domains, this study provides a foundation for future work to address the identified research gaps and advance the integration of AI to improve CAE user experience.
EdgeFL: A Lightweight Decentralized Federated Learning Framework
Sep 06, 2023



Federated Learning (FL) has emerged as a promising approach for collaborative machine learning, addressing data privacy concerns. However, existing FL platforms and frameworks often present challenges for software engineers in terms of complexity, limited customization options, and scalability limitations. In this paper, we introduce EdgeFL, an edge-only lightweight decentralized FL framework, designed to overcome the limitations of centralized aggregation and scalability in FL deployments. By adopting an edge-only model training and aggregation approach, EdgeFL eliminates the need for a central server, enabling seamless scalability across diverse use cases. With a straightforward integration process requiring just four lines of code (LOC), software engineers can easily incorporate FL functionalities into their AI products. Furthermore, EdgeFL offers the flexibility to customize aggregation functions, empowering engineers to adapt them to specific needs. Based on the results, we demonstrate that EdgeFL achieves superior performance compared to existing FL platforms/frameworks. Our results show that EdgeFL reduces weights update latency and enables faster model evolution, enhancing the efficiency of edge devices. Moreover, EdgeFL exhibits improved classification accuracy compared to traditional centralized FL approaches. By leveraging EdgeFL, software engineers can harness the benefits of federated learning while overcoming the challenges associated with existing FL platforms/frameworks.
5G Network on Wings: A Deep Reinforcement Learning Approach to UAV-based Integrated Access and Backhaul
Feb 07, 2022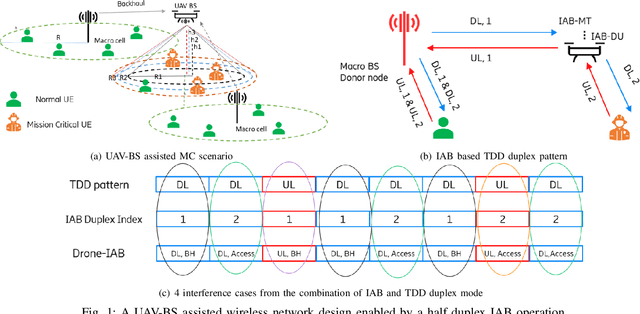
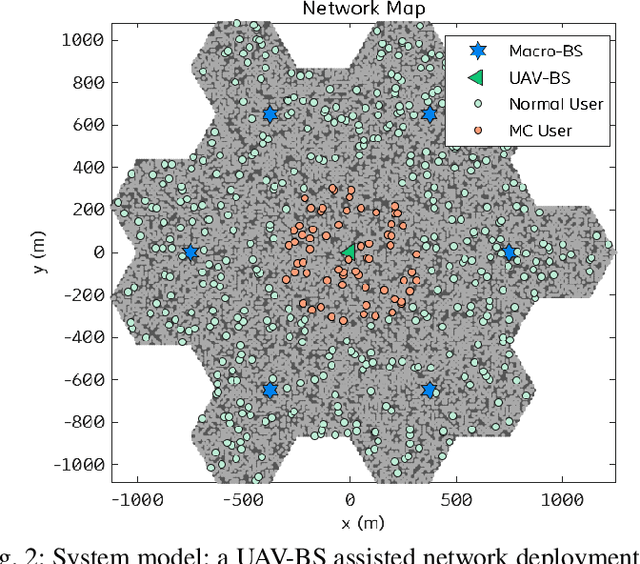
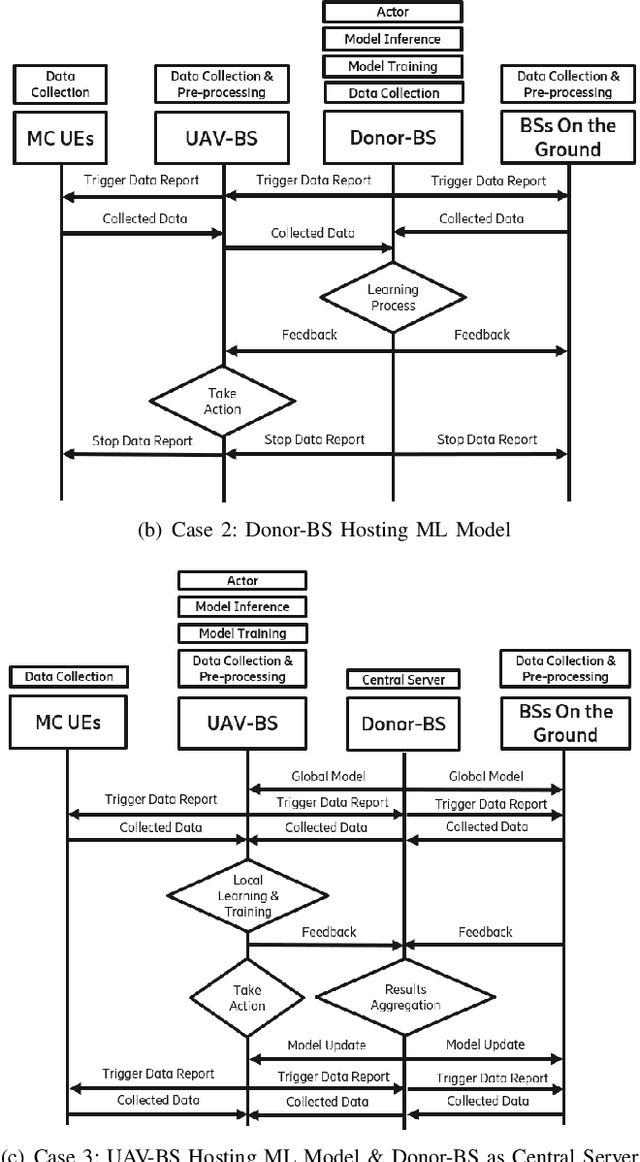
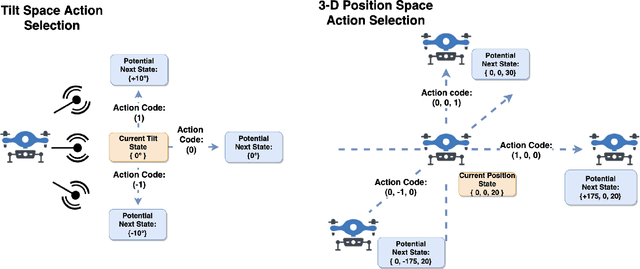
Fast and reliable wireless communication has become a critical demand in human life. When natural disasters strike, providing ubiquitous connectivity becomes challenging by using traditional wireless networks. In this context, unmanned aerial vehicle (UAV) based aerial networks offer a promising alternative for fast, flexible, and reliable wireless communications in mission-critical (MC) scenarios. Due to the unique characteristics such as mobility, flexible deployment, and rapid reconfiguration, drones can readily change location dynamically to provide on-demand communications to users on the ground in emergency scenarios. As a result, the usage of UAV base stations (UAV-BSs) has been considered as an appropriate approach for providing rapid connection in MC scenarios. In this paper, we study how to control a UAV-BS in both static and dynamic environments. We investigate a situation in which a macro BS is destroyed as a result of a natural disaster and a UAV-BS is deployed using integrated access and backhaul (IAB) technology to provide coverage for users in the disaster area. We present a data collection system, signaling procedures and machine learning applications for this use case. A deep reinforcement learning algorithm is developed to jointly optimize the tilt of the access and backhaul antennas of the UAV-BS as well as its three-dimensional placement. Evaluation results show that the proposed algorithm can autonomously navigate and configure the UAV-BS to satisfactorily serve the MC users on the ground.
Autonomous Navigation and Configuration of Integrated Access Backhauling for UAV Base Station Using Reinforcement Learning
Dec 14, 2021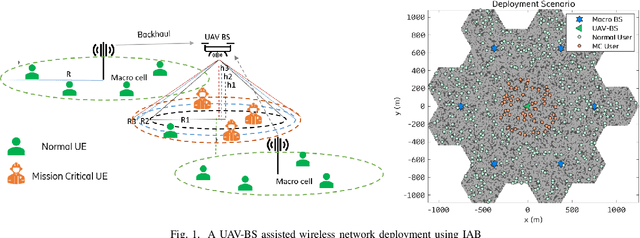
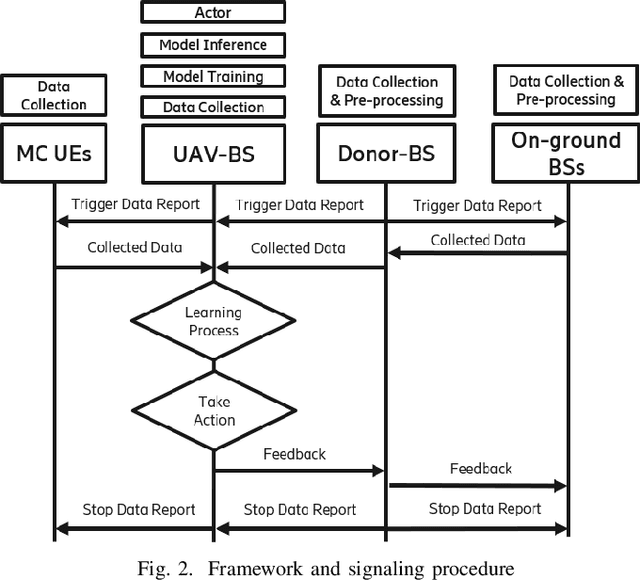
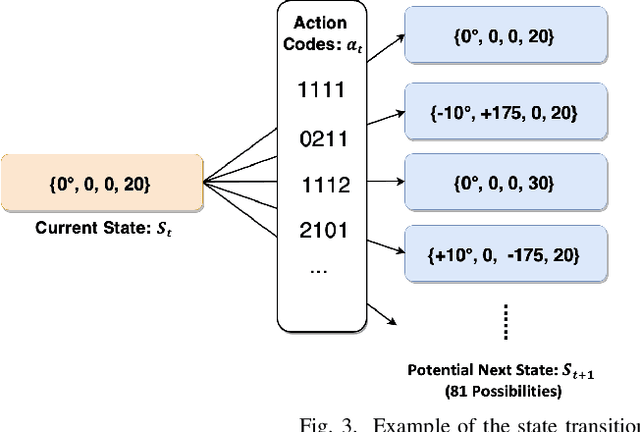
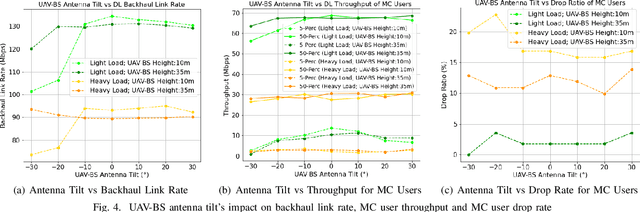
Fast and reliable connectivity is essential to enhancing situational awareness and operational efficiency for public safety mission-critical (MC) users. In emergency or disaster circumstances, where existing cellular network coverage and capacity may not be available to meet MC communication demands, deployable-network-based solutions such as cells-on-wheels/wings can be utilized swiftly to ensure reliable connection for MC users. In this paper, we consider a scenario where a macro base station (BS) is destroyed due to a natural disaster and an unmanned aerial vehicle carrying BS (UAV-BS) is set up to provide temporary coverage for users in the disaster area. The UAV-BS is integrated into the mobile network using the 5G integrated access and backhaul (IAB) technology. We propose a framework and signalling procedure for applying machine learning to this use case. A deep reinforcement learning algorithm is designed to jointly optimize the access and backhaul antenna tilt as well as the three-dimensional location of the UAV-BS in order to best serve the on-ground MC users while maintaining a good backhaul connection. Our result shows that the proposed algorithm can autonomously navigate and configure the UAV-BS to improve the throughput and reduce the drop rate of MC users.
On the Assessment of Benchmark Suites for Algorithm Comparison
Apr 15, 2021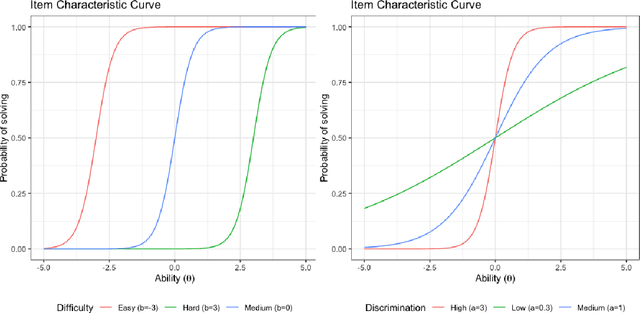
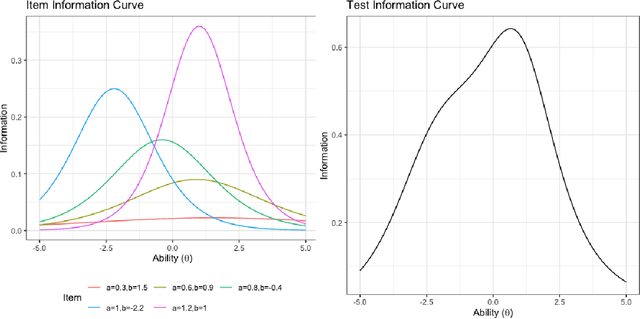
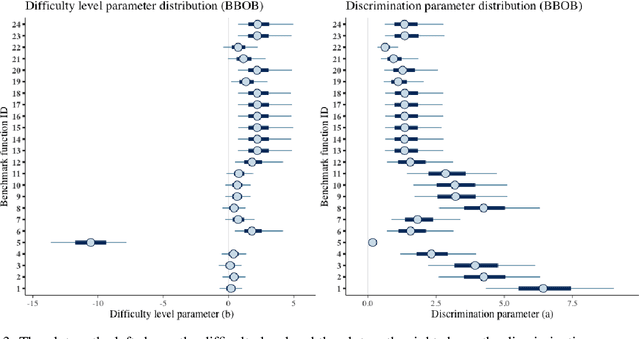
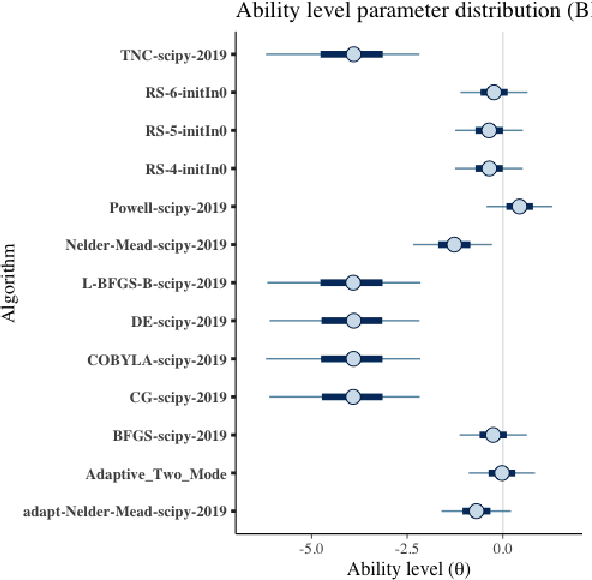
Benchmark suites, i.e. a collection of benchmark functions, are widely used in the comparison of black-box optimization algorithms. Over the years, research has identified many desired qualities for benchmark suites, such as diverse topology, different difficulties, scalability, representativeness of real-world problems among others. However, while the topology characteristics have been subjected to previous studies, there is no study that has statistically evaluated the difficulty level of benchmark functions, how well they discriminate optimization algorithms and how suitable is a benchmark suite for algorithm comparison. In this paper, we propose the use of an item response theory (IRT) model, the Bayesian two-parameter logistic model for multiple attempts, to statistically evaluate these aspects with respect to the empirical success rate of algorithms. With this model, we can assess the difficulty level of each benchmark, how well they discriminate different algorithms, the ability score of an algorithm, and how much information the benchmark suite adds in the estimation of the ability scores. We demonstrate the use of this model in two well-known benchmark suites, the Black-Box Optimization Benchmark (BBOB) for continuous optimization and the Pseudo Boolean Optimization (PBO) for discrete optimization. We found that most benchmark functions of BBOB suite have high difficulty levels (compared to the optimization algorithms) and low discrimination. For the PBO, most functions have good discrimination parameters but are often considered too easy. We discuss potential uses of IRT in benchmarking, including its use to improve the design of benchmark suites, to measure multiple aspects of the algorithms, and to design adaptive suites.
Real-time End-to-End Federated Learning: An Automotive Case Study
Mar 22, 2021


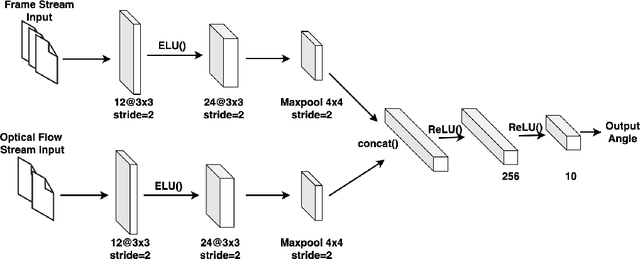
With the development and the increasing interests in ML/DL fields, companies are eager to utilize these methods to improve their service quality and user experience. Federated Learning has been introduced as an efficient model training approach to distribute and speed up time-consuming model training and preserve user data privacy. However, common Federated Learning methods apply a synchronized protocol to perform model aggregation, which turns out to be inflexible and unable to adapt to rapidly evolving environments and heterogeneous hardware settings in real-world systems. In this paper, we introduce an approach to real-time end-to-end Federated Learning combined with a novel asynchronous model aggregation protocol. We validate our approach in an industrial use case in the automotive domain focusing on steering wheel angle prediction for autonomous driving. Our results show that asynchronous Federated Learning can significantly improve the prediction performance of local edge models and reach the same accuracy level as the centralized machine learning method. Moreover, the approach can reduce the communication overhead, accelerate model training speed and consume real-time streaming data by utilizing a sliding training window, which proves high efficiency when deploying ML/DL components to heterogeneous real-world embedded systems.
Engineering AI Systems: A Research Agenda
Jan 16, 2020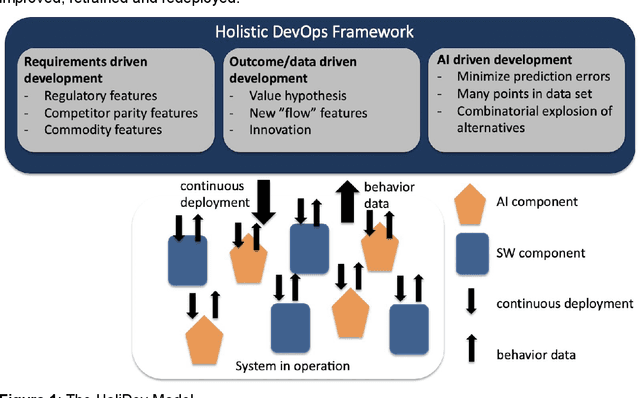
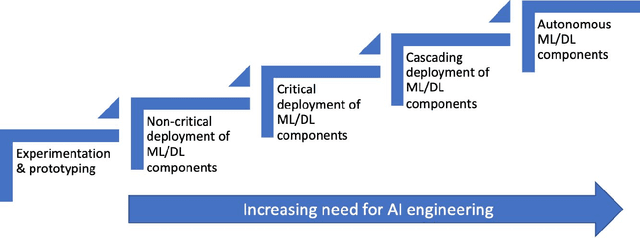

Deploying machine-, and in particular deep-learning, (ML/DL) solutions in industry-strength, production quality contexts proves to challenging. This requires a structured engineering approach to constructing and evolving systems that contain ML/DL components. In this paper, we provide a conceptualization of the typical evolution patterns that companies experience when employing ML/DL well as a framework for integrating ML/DL components in systems consisting of multiple types of components. In addition, we provide an overview of the engineering challenges surrounding AI/ML/DL solutions and, based on that, we provide a research agenda and overview of open items that need to be addressed by the research community at large.
Software Engineering Challenges of Deep Learning
Oct 29, 2018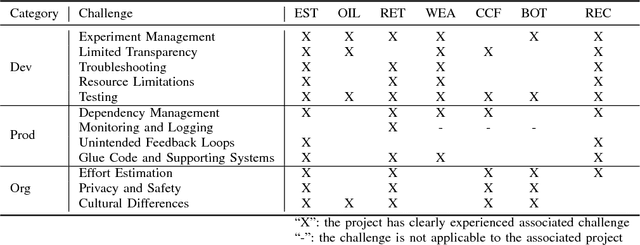
Surprisingly promising results have been achieved by deep learning (DL) systems in recent years. Many of these achievements have been reached in academic settings, or by large technology companies with highly skilled research groups and advanced supporting infrastructure. For companies without large research groups or advanced infrastructure, building high-quality production-ready systems with DL components has proven challenging. There is a clear lack of well-functioning tools and best practices for building DL systems. It is the goal of this research to identify what the main challenges are, by applying an interpretive research approach in close collaboration with companies of varying size and type. A set of seven projects have been selected to describe the potential with this new technology and to identify associated main challenges. A set of 12 main challenges has been identified and categorized into the three areas of development, production, and organizational challenges. Furthermore, a mapping between the challenges and the projects is defined, together with selected motivating descriptions of how and why the challenges apply to specific projects. Compared to other areas such as software engineering or database technologies, it is clear that DL is still rather immature and in need of further work to facilitate development of high-quality systems. The challenges identified in this paper can be used to guide future research by the software engineering and DL communities. Together, we could enable a large number of companies to start taking advantage of the high potential of the DL technology.