 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements in Medical Image Classification through Fine-Tuning Natural Domain Foundation Models
May 26, 2025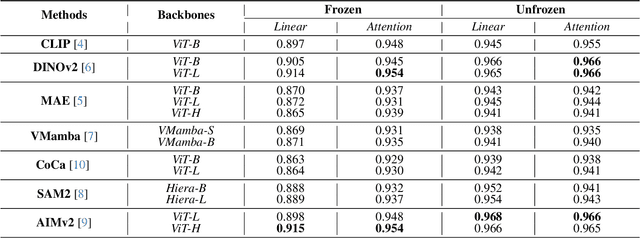
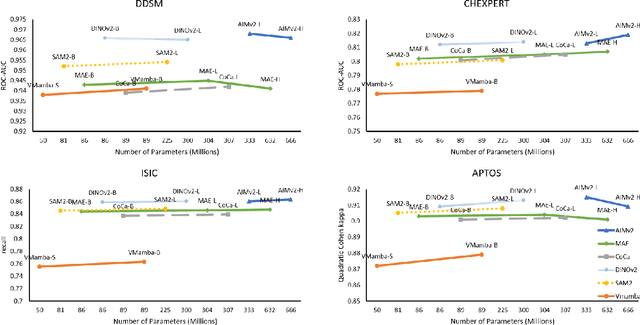
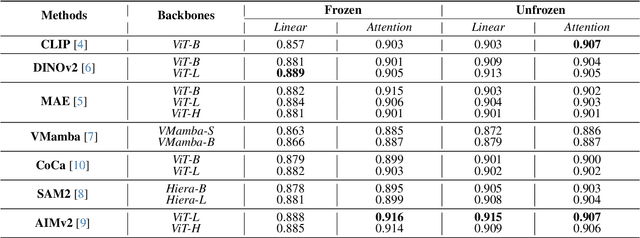
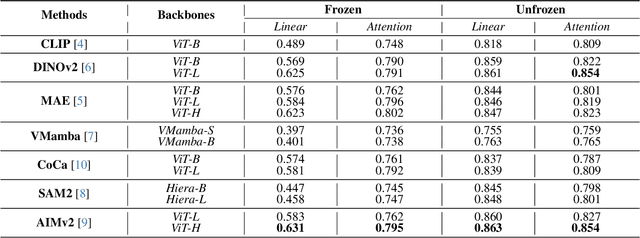
Using massive datasets, foundation models are large-scale, pre-trained models that perform a wide range of tasks. These models have shown consistently improved results with the introduction of new methods. It is crucial to analyze how these trends impact the medical field and determine whether these advancements can drive meaningful change. This study investigates the application of recent state-of-the-art foundation models, DINOv2, MAE, VMamba, CoCa, SAM2, and AIMv2, for medical image classification. We explore their effectiveness on datasets including CBIS-DDSM for mammography, ISIC2019 for skin lesions, APTOS2019 for diabetic retinopathy, and CHEXPERT for chest radiographs. By fine-tuning these models and evaluating their configurations, we aim to understand the potential of these advancements in medical image classification. The results indicate that these advanced models significantly enhance classification outcomes, demonstrating robust performance despite limited labeled data. Based on our results, AIMv2, DINOv2, and SAM2 models outperformed others, demonstrating that progress in natural domain training has positively impacted the medical domain and improved classification outcomes. Our code is publicly available at: https://github.com/sajjad-sh33/Medical-Transfer-Learning.
The Missing Point in Vision Transformers for Universal Image Segmentation
May 26, 2025Image segmentation remains a challenging task in computer vision, demanding robust mask generation and precise classification. Recent mask-based approaches yield high-quality masks by capturing global context. However, accurately classifying these masks, especially in the presence of ambiguous boundaries and imbalanced class distributions, remains an open challenge. In this work, we introduce ViT-P, a novel two-stage segmentation framework that decouples mask generation from classification. The first stage employs a proposal generator to produce class-agnostic mask proposals, while the second stage utilizes a point-based classification model built on the Vision Transformer (ViT) to refine predictions by focusing on mask central points. ViT-P serves as a pre-training-free adapter, allowing the integration of various pre-trained vision transformers without modifying their architecture, ensuring adaptability to dense prediction tasks. Furthermore, we demonstrate that coarse and bounding box annotations can effectively enhance classification without requiring additional training on fine annotation datasets, reducing annotation costs while maintaining strong performance. Extensive experiments across COCO, ADE20K, and Cityscapes datasets validate the effectiveness of ViT-P, achieving state-of-the-art results with 54.0 PQ on ADE20K panoptic segmentation, 87.4 mIoU on Cityscapes semantic segmentation, and 63.6 mIoU on ADE20K semantic segmentation. The code and pretrained models are available at: https://github.com/sajjad-sh33/ViT-P}{https://github.com/sajjad-sh33/ViT-P.
Leveraging Foundation Models for Efficient Federated Learning in Resource-restricted Edge Networks
Sep 14, 2024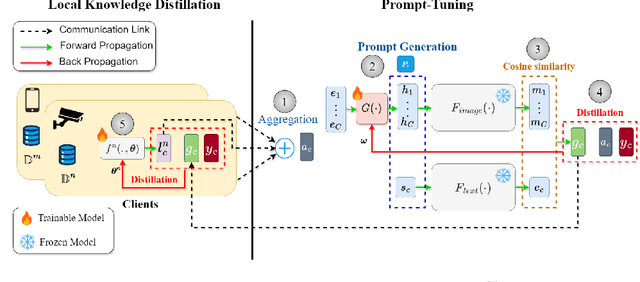

Recently pre-trained Foundation Models (FMs) have been combined with Federated Learning (FL) to improve training of downstream tasks while preserving privacy. However, deploying FMs over edge networks with resource-constrained Internet of Things (IoT) devices is under-explored. This paper proposes a novel framework, namely, Federated Distilling knowledge to Prompt (FedD2P), for leveraging the robust representation abilities of a vision-language FM without deploying it locally on edge devices. This framework distills the aggregated knowledge of IoT devices to a prompt generator to efficiently adapt the frozen FM for downstream tasks. To eliminate the dependency on a public dataset, our framework leverages perclass local knowledge from IoT devices and linguistic descriptions of classes to train the prompt generator. Our experiments on diverse image classification datasets CIFAR, OxfordPets, SVHN, EuroSAT, and DTD show that FedD2P outperforms the baselines in terms of model performance.
Self-Prompting Polyp Segmentation in Colonoscopy using Hybrid Yolo-SAM 2 Model
Sep 14, 2024



Early diagnosis and treatment of polyps during colonoscopy are essential for reducing the incidence and mortality of Colorectal Cancer (CRC). However, the variability in polyp characteristics and the presence of artifacts in colonoscopy images and videos pose significant challenges for accurate and efficient polyp detection and segmentation. This paper presents a novel approach to polyp segmentation by integrating the Segment Anything Model (SAM 2) with the YOLOv8 model. Our method leverages YOLOv8's bounding box predictions to autonomously generate input prompts for SAM 2, thereby reducing the need for manual annotations. We conducted exhaustive tests on five benchmark colonoscopy image datasets and two colonoscopy video datasets, demonstrating that our method exceeds state-of-the-art models in both image and video segmentation tasks. Notably, our approach achieves high segmentation accuracy using only bounding box annotations, significantly reducing annotation time and effort. This advancement holds promise for enhancing the efficiency and scalability of polyp detection in clinical settings https://github.com/sajjad-sh33/YOLO_SAM2.
Polyp SAM 2: Advancing Zero shot Polyp Segmentation in Colorectal Cancer Detection
Aug 12, 2024



Polyp segmentation plays a crucial role in the early detection and diagnosis of colorectal cancer. However, obtaining accurate segmentations often requires labor-intensive annotations and specialized models. Recently, Meta AI Research released a general Segment Anything Model 2 (SAM 2), which has demonstrated promising performance in several segmentation tasks. In this work, we evaluate the performance of SAM 2 in segmenting polyps under various prompted settings. We hope this report will provide insights to advance the field of polyp segmentation and promote more interesting work in the future. This project is publicly available at https://github.com/ sajjad-sh33/Polyp-SAM-2.
KnFu: Effective Knowledge Fusion
Mar 18, 2024



Federated Learning (FL) has emerged as a prominent alternative to the traditional centralized learning approach. Generally speaking, FL is a decentralized approach that allows for collaborative training of Machine Learning (ML) models across multiple local nodes, ensuring data privacy and security while leveraging diverse datasets. Conventional FL, however, is susceptible to gradient inversion attacks, restrictively enforces a uniform architecture on local models, and suffers from model heterogeneity (model drift) due to non-IID local datasets. To mitigate some of these challenges, the new paradigm of Federated Knowledge Distillation (FKD) has emerged. FDK is developed based on the concept of Knowledge Distillation (KD), which involves extraction and transfer of a large and well-trained teacher model's knowledge to lightweight student models. FKD, however, still faces the model drift issue. Intuitively speaking, not all knowledge is universally beneficial due to the inherent diversity of data among local nodes. This calls for innovative mechanisms to evaluate the relevance and effectiveness of each client's knowledge for others, to prevent propagation of adverse knowledge. In this context, the paper proposes Effective Knowledge Fusion (KnFu) algorithm that evaluates knowledge of local models to only fuse semantic neighbors' effective knowledge for each client. The KnFu is a personalized effective knowledge fusion scheme for each client, that analyzes effectiveness of different local models' knowledge prior to the aggregation phase. Comprehensive experiments were performed on MNIST and CIFAR10 datasets illustrating effectiveness of the proposed KnFu in comparison to its state-of-the-art counterparts. A key conclusion of the work is that in scenarios with large and highly heterogeneous local datasets, local training could be preferable to knowledge fusion-based solutions.
FedD2S: Personalized Data-Free Federated Knowledge Distillation
Feb 16, 2024
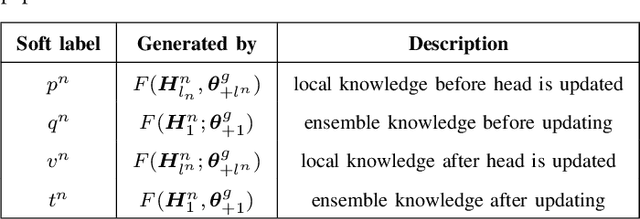
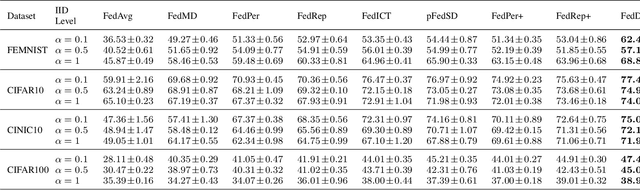
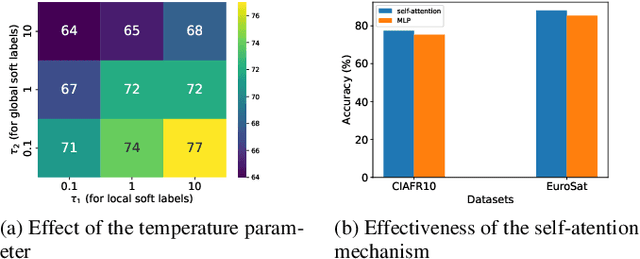
This paper addresses the challenge of mitigating data heterogeneity among clients within a Federated Learning (FL) framework. The model-drift issue, arising from the noniid nature of client data, often results in suboptimal personalization of a global model compared to locally trained models for each client. To tackle this challenge, we propose a novel approach named FedD2S for Personalized Federated Learning (pFL), leveraging knowledge distillation. FedD2S incorporates a deep-to-shallow layer-dropping mechanism in the data-free knowledge distillation process to enhance local model personalization. Through extensive simulations on diverse image datasets-FEMNIST, CIFAR10, CINIC0, and CIFAR100-we compare FedD2S with state-of-the-art FL baselines. The proposed approach demonstrates superior performance, characterized by accelerated convergence and improved fairness among clients. The introduced layer-dropping technique effectively captures personalized knowledge, resulting in enhanced performance compared to alternative FL models. Moreover, we investigate the impact of key hyperparameters, such as the participation ratio and layer-dropping rate, providing valuable insights into the optimal configuration for FedD2S. The findings demonstrate the efficacy of adaptive layer-dropping in the knowledge distillation process to achieve enhanced personalization and performance across diverse datasets and tasks.
HistoSegCap: Capsules for Weakly-Supervised Semantic Segmentation of Histological Tissue Type in Whole Slide Images
Feb 16, 2024



Digital pathology involves converting physical tissue slides into high-resolution Whole Slide Images (WSIs), which pathologists analyze for disease-affected tissues. However, large histology slides with numerous microscopic fields pose challenges for visual search. To aid pathologists, Computer Aided Diagnosis (CAD) systems offer visual assistance in efficiently examining WSIs and identifying diagnostically relevant regions. This paper presents a novel histopathological image analysis method employing Weakly Supervised Semantic Segmentation (WSSS) based on Capsule Networks, the first such application. The proposed model is evaluated using the Atlas of Digital Pathology (ADP) dataset and its performance is compared with other histopathological semantic segmentation methodologies. The findings underscore the potential of Capsule Networks in enhancing the precision and efficiency of histopathological image analysis. Experimental results show that the proposed model outperforms traditional methods in terms of accuracy and the mean Intersection-over-Union (mIoU) metric.
CLSA: Contrastive Learning-based Survival Analysis for Popularity Prediction in MEC Networks
Mar 21, 2023



Mobile Edge Caching (MEC) integrated with Deep Neural Networks (DNNs) is an innovative technology with significant potential for the future generation of wireless networks, resulting in a considerable reduction in users' latency. The MEC network's effectiveness, however, heavily relies on its capacity to predict and dynamically update the storage of caching nodes with the most popular contents. To be effective, a DNN-based popularity prediction model needs to have the ability to understand the historical request patterns of content, including their temporal and spatial correlations. Existing state-of-the-art time-series DNN models capture the latter by simultaneously inputting the sequential request patterns of multiple contents to the network, considerably increasing the size of the input sample. This motivates us to address this challenge by proposing a DNN-based popularity prediction framework based on the idea of contrasting input samples against each other, designed for the Unmanned Aerial Vehicle (UAV)-aided MEC networks. Referred to as the Contrastive Learning-based Survival Analysis (CLSA), the proposed architecture consists of a self-supervised Contrastive Learning (CL) model, where the temporal information of sequential requests is learned using a Long Short Term Memory (LSTM) network as the encoder of the CL architecture. Followed by a Survival Analysis (SA) network, the output of the proposed CLSA architecture is probabilities for each content's future popularity, which are then sorted in descending order to identify the Top-K popular contents. Based on the simulation results, the proposed CLSA architecture outperforms its counterparts across the classification accuracy and cache-hit ratio.
Graph Federated Learning for CIoT Devices in Smart Home Applications
Dec 29, 2022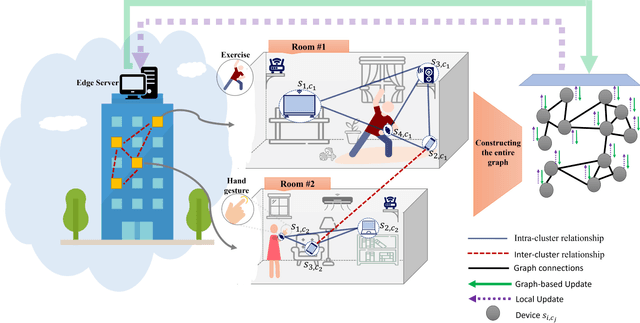
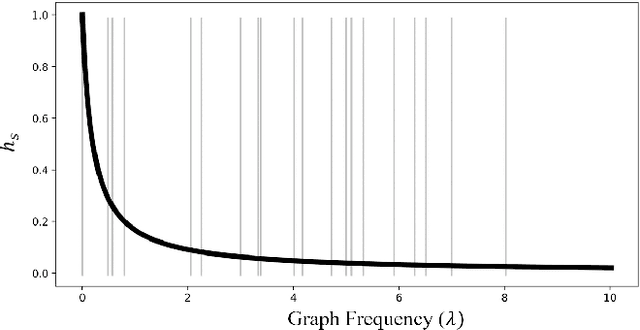
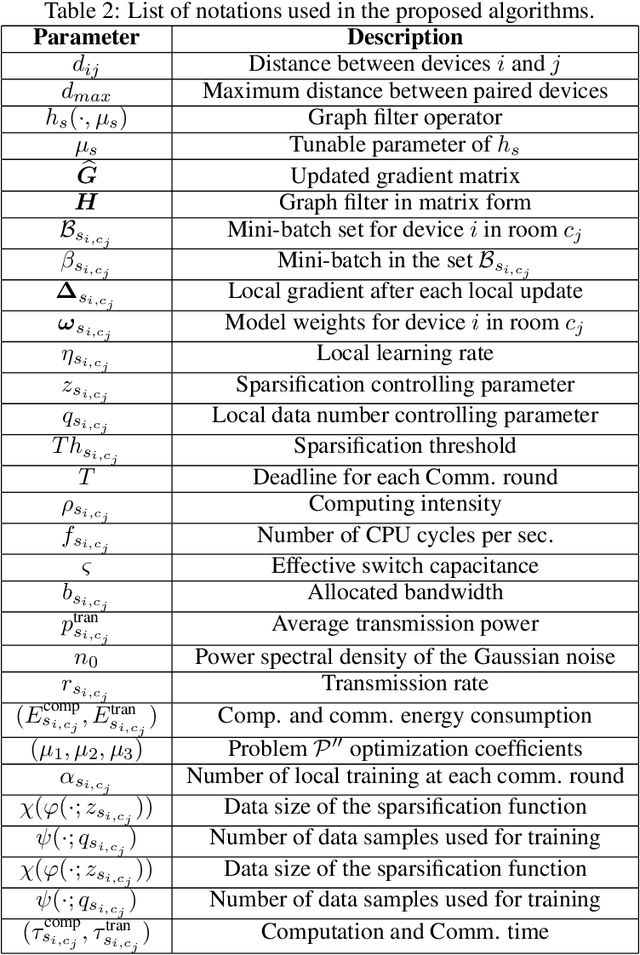
This paper deals with the problem of statistical and system heterogeneity in a cross-silo Federated Learning (FL) framework where there exist a limited number of Consumer Internet of Things (CIoT) devices in a smart building. We propose a novel Graph Signal Processing (GSP)-inspired aggregation rule based on graph filtering dubbed ``G-Fedfilt''. The proposed aggregator enables a structured flow of information based on the graph's topology. This behavior allows capturing the interconnection of CIoT devices and training domain-specific models. The embedded graph filter is equipped with a tunable parameter which enables a continuous trade-off between domain-agnostic and domain-specific FL. In the case of domain-agnostic, it forces G-Fedfilt to act similar to the conventional Federated Averaging (FedAvg) aggregation rule. The proposed G-Fedfilt also enables an intrinsic smooth clustering based on the graph connectivity without explicitly specified which further boosts the personalization of the models in the framework. In addition, the proposed scheme enjoys a communication-efficient time-scheduling to alleviate the system heterogeneity. This is accomplished by adaptively adjusting the amount of training data samples and sparsity of the models' gradients to reduce communication desynchronization and latency. Simulation results show that the proposed G-Fedfilt achieves up to $3.99\% $ better classification accuracy than the conventional FedAvg when concerning model personalization on the statistically heterogeneous local datasets, while it is capable of yielding up to $2.41\%$ higher accuracy than FedAvg in the case of testing the generalization of the models.