 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSTAM: Efficient Graph Distillation with Structural Attention-Matching
Aug 29, 2024



Graph distillation has emerged as a solution for reducing large graph datasets to smaller, more manageable, and informative ones. Existing methods primarily target node classification, involve computationally intensive processes, and fail to capture the true distribution of the full graph dataset. To address these issues, we introduce Graph Distillation with Structural Attention Matching (GSTAM), a novel method for condensing graph classification datasets. GSTAM leverages the attention maps of GNNs to distill structural information from the original dataset into synthetic graphs. The structural attention-matching mechanism exploits the areas of the input graph that GNNs prioritize for classification, effectively distilling such information into the synthetic graphs and improving overall distillation performance. Comprehensive experiments demonstrate GSTAM's superiority over existing methods, achieving 0.45% to 6.5% better performance in extreme condensation ratios, highlighting its potential use in advancing distillation for graph classification tasks (Code available at https://github.com/arashrasti96/GSTAM).
Graph Federated Learning for CIoT Devices in Smart Home Applications
Dec 29, 2022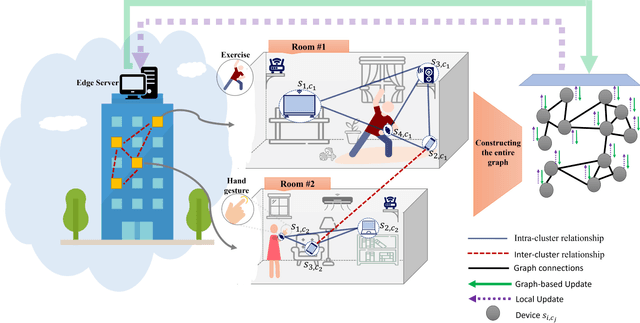
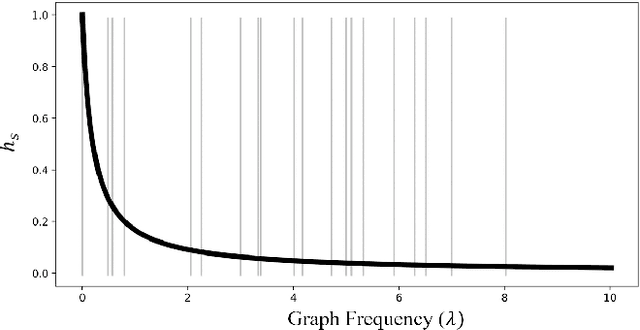
This paper deals with the problem of statistical and system heterogeneity in a cross-silo Federated Learning (FL) framework where there exist a limited number of Consumer Internet of Things (CIoT) devices in a smart building. We propose a novel Graph Signal Processing (GSP)-inspired aggregation rule based on graph filtering dubbed ``G-Fedfilt''. The proposed aggregator enables a structured flow of information based on the graph's topology. This behavior allows capturing the interconnection of CIoT devices and training domain-specific models. The embedded graph filter is equipped with a tunable parameter which enables a continuous trade-off between domain-agnostic and domain-specific FL. In the case of domain-agnostic, it forces G-Fedfilt to act similar to the conventional Federated Averaging (FedAvg) aggregation rule. The proposed G-Fedfilt also enables an intrinsic smooth clustering based on the graph connectivity without explicitly specified which further boosts the personalization of the models in the framework. In addition, the proposed scheme enjoys a communication-efficient time-scheduling to alleviate the system heterogeneity. This is accomplished by adaptively adjusting the amount of training data samples and sparsity of the models' gradients to reduce communication desynchronization and latency. Simulation results show that the proposed G-Fedfilt achieves up to $3.99\% $ better classification accuracy than the conventional FedAvg when concerning model personalization on the statistically heterogeneous local datasets, while it is capable of yielding up to $2.41\%$ higher accuracy than FedAvg in the case of testing the generalization of the models.