 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAD: Bidirectional Auto-regressive Diffusion for Text-to-Motion Generation
Sep 17, 2024



Autoregressive models excel in modeling sequential dependencies by enforcing causal constraints, yet they struggle to capture complex bidirectional patterns due to their unidirectional nature. In contrast, mask-based models leverage bidirectional context, enabling richer dependency modeling. However, they often assume token independence during prediction, which undermines the modeling of sequential dependencies. Additionally, the corruption of sequences through masking or absorption can introduce unnatural distortions, complicating the learning process. To address these issues, we propose Bidirectional Autoregressive Diffusion (BAD), a novel approach that unifies the strengths of autoregressive and mask-based generative models. BAD utilizes a permutation-based corruption technique that preserves the natural sequence structure while enforcing causal dependencies through randomized ordering, enabling the effective capture of both sequential and bidirectional relationships. Comprehensive experiments show that BAD outperforms autoregressive and mask-based models in text-to-motion generation, suggesting a novel pre-training strategy for sequence modeling. The codebase for BAD is available on https://github.com/RohollahHS/BAD.
KnFu: Effective Knowledge Fusion
Mar 18, 2024



Federated Learning (FL) has emerged as a prominent alternative to the traditional centralized learning approach. Generally speaking, FL is a decentralized approach that allows for collaborative training of Machine Learning (ML) models across multiple local nodes, ensuring data privacy and security while leveraging diverse datasets. Conventional FL, however, is susceptible to gradient inversion attacks, restrictively enforces a uniform architecture on local models, and suffers from model heterogeneity (model drift) due to non-IID local datasets. To mitigate some of these challenges, the new paradigm of Federated Knowledge Distillation (FKD) has emerged. FDK is developed based on the concept of Knowledge Distillation (KD), which involves extraction and transfer of a large and well-trained teacher model's knowledge to lightweight student models. FKD, however, still faces the model drift issue. Intuitively speaking, not all knowledge is universally beneficial due to the inherent diversity of data among local nodes. This calls for innovative mechanisms to evaluate the relevance and effectiveness of each client's knowledge for others, to prevent propagation of adverse knowledge. In this context, the paper proposes Effective Knowledge Fusion (KnFu) algorithm that evaluates knowledge of local models to only fuse semantic neighbors' effective knowledge for each client. The KnFu is a personalized effective knowledge fusion scheme for each client, that analyzes effectiveness of different local models' knowledge prior to the aggregation phase. Comprehensive experiments were performed on MNIST and CIFAR10 datasets illustrating effectiveness of the proposed KnFu in comparison to its state-of-the-art counterparts. A key conclusion of the work is that in scenarios with large and highly heterogeneous local datasets, local training could be preferable to knowledge fusion-based solutions.
FedD2S: Personalized Data-Free Federated Knowledge Distillation
Feb 16, 2024
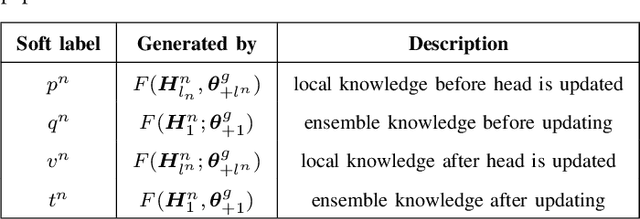
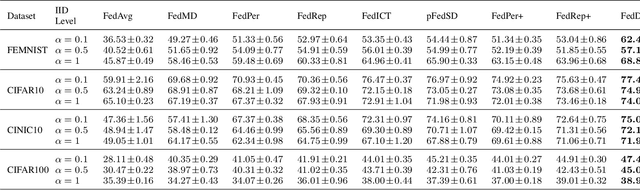
This paper addresses the challenge of mitigating data heterogeneity among clients within a Federated Learning (FL) framework. The model-drift issue, arising from the noniid nature of client data, often results in suboptimal personalization of a global model compared to locally trained models for each client. To tackle this challenge, we propose a novel approach named FedD2S for Personalized Federated Learning (pFL), leveraging knowledge distillation. FedD2S incorporates a deep-to-shallow layer-dropping mechanism in the data-free knowledge distillation process to enhance local model personalization. Through extensive simulations on diverse image datasets-FEMNIST, CIFAR10, CINIC0, and CIFAR100-we compare FedD2S with state-of-the-art FL baselines. The proposed approach demonstrates superior performance, characterized by accelerated convergence and improved fairness among clients. The introduced layer-dropping technique effectively captures personalized knowledge, resulting in enhanced performance compared to alternative FL models. Moreover, we investigate the impact of key hyperparameters, such as the participation ratio and layer-dropping rate, providing valuable insights into the optimal configuration for FedD2S. The findings demonstrate the efficacy of adaptive layer-dropping in the knowledge distillation process to achieve enhanced personalization and performance across diverse datasets and tasks.