 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundation Models for Efficient Federated Learning in Resource-restricted Edge Networks
Sep 14, 2024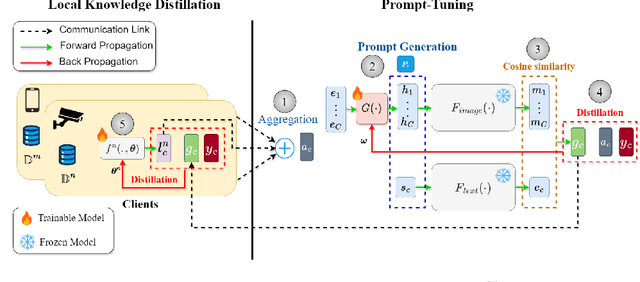

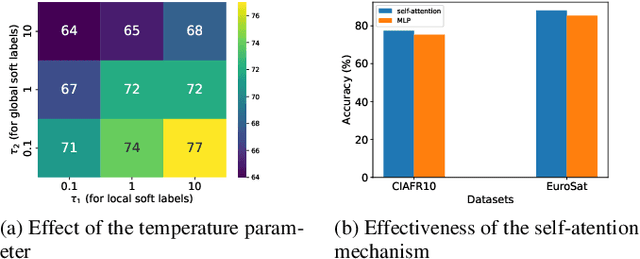
Recently pre-trained Foundation Models (FMs) have been combined with Federated Learning (FL) to improve training of downstream tasks while preserving privacy. However, deploying FMs over edge networks with resource-constrained Internet of Things (IoT) devices is under-explored. This paper proposes a novel framework, namely, Federated Distilling knowledge to Prompt (FedD2P), for leveraging the robust representation abilities of a vision-language FM without deploying it locally on edge devices. This framework distills the aggregated knowledge of IoT devices to a prompt generator to efficiently adapt the frozen FM for downstream tasks. To eliminate the dependency on a public dataset, our framework leverages perclass local knowledge from IoT devices and linguistic descriptions of classes to train the prompt generator. Our experiments on diverse image classification datasets CIFAR, OxfordPets, SVHN, EuroSAT, and DTD show that FedD2P outperforms the baselines in terms of model performance.
KnFu: Effective Knowledge Fusion
Mar 18, 2024



Federated Learning (FL) has emerged as a prominent alternative to the traditional centralized learning approach. Generally speaking, FL is a decentralized approach that allows for collaborative training of Machine Learning (ML) models across multiple local nodes, ensuring data privacy and security while leveraging diverse datasets. Conventional FL, however, is susceptible to gradient inversion attacks, restrictively enforces a uniform architecture on local models, and suffers from model heterogeneity (model drift) due to non-IID local datasets. To mitigate some of these challenges, the new paradigm of Federated Knowledge Distillation (FKD) has emerged. FDK is developed based on the concept of Knowledge Distillation (KD), which involves extraction and transfer of a large and well-trained teacher model's knowledge to lightweight student models. FKD, however, still faces the model drift issue. Intuitively speaking, not all knowledge is universally beneficial due to the inherent diversity of data among local nodes. This calls for innovative mechanisms to evaluate the relevance and effectiveness of each client's knowledge for others, to prevent propagation of adverse knowledge. In this context, the paper proposes Effective Knowledge Fusion (KnFu) algorithm that evaluates knowledge of local models to only fuse semantic neighbors' effective knowledge for each client. The KnFu is a personalized effective knowledge fusion scheme for each client, that analyzes effectiveness of different local models' knowledge prior to the aggregation phase. Comprehensive experiments were performed on MNIST and CIFAR10 datasets illustrating effectiveness of the proposed KnFu in comparison to its state-of-the-art counterparts. A key conclusion of the work is that in scenarios with large and highly heterogeneous local datasets, local training could be preferable to knowledge fusion-based solutions.