 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Distance-based Expansion of Low-Density Latent Regions for Unknown Class Detection
Jan 19, 2024This paper addresses the significant challenge in open-set object detection (OSOD): the tendency of state-of-the-art detectors to erroneously classify unknown objects as known categories with high confidence. We present a novel approach that effectively identifies unknown objects by distinguishing between high and low-density regions in latent space. Our method builds upon the Open-Det (OD) framework, introducing two new elements to the loss function. These elements enhance the known embedding space's clustering and expand the unknown space's low-density regions. The first addition is the Class Wasserstein Anchor (CWA), a new function that refines the classification boundaries. The second is a spectral normalisation step, improving the robustness of the model. Together, these augmentations to the existing Contrastive Feature Learner (CFL) and Unknown Probability Learner (UPL) loss functions significantly improve OSOD performance. Our proposed OpenDet-CWA (OD-CWA) method demonstrates: a) a reduction in open-set errors by approximately 17%-22%, b) an enhancement in novelty detection capability by 1.5%-16%, and c) a decrease in the wilderness index by 2%-20% across various open-set scenarios. These results represent a substantial advancement in the field, showcasing the potential of our approach in managing the complexities of open-set object detection.
Program Generation from Diverse Video Demonstrations
Feb 01, 2023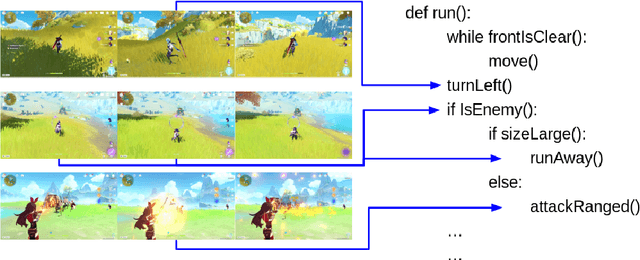
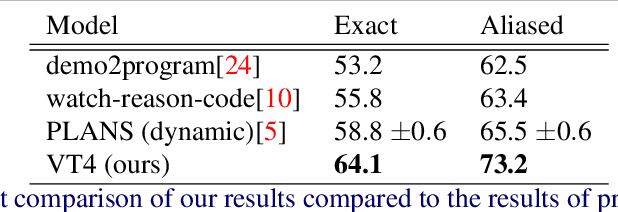
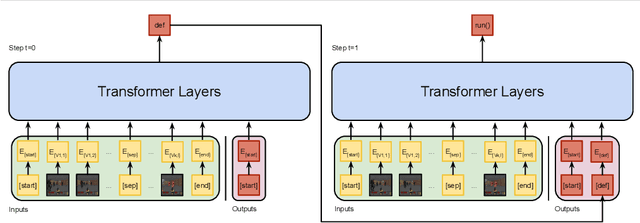

The ability to use inductive reasoning to extract general rules from multiple observations is a vital indicator of intelligence. As humans, we use this ability to not only interpret the world around us, but also to predict the outcomes of the various interactions we experience. Generalising over multiple observations is a task that has historically presented difficulties for machines to grasp, especially when requiring computer vision. In this paper, we propose a model that can extract general rules from video demonstrations by simultaneously performing summarisation and translation. Our approach differs from prior works by framing the problem as a multi-sequence-to-sequence task, wherein summarisation is learnt by the model. This allows our model to utilise edge cases that would otherwise be suppressed or discarded by traditional summarisation techniques. Additionally, we show that our approach can handle noisy specifications without the need for additional filtering methods. We evaluate our model by synthesising programs from video demonstrations in the Vizdoom environment achieving state-of-the-art results with a relative increase of 11.75% program accuracy on prior works
GARF: Gaussian Activated Radiance Fields for High Fidelity Reconstruction and Pose Estimation
Apr 12, 2022
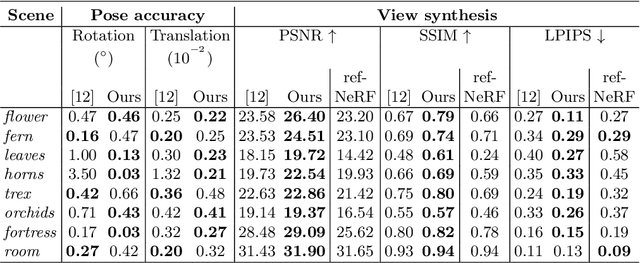


Despite Neural Radiance Fields (NeRF) showing compelling results in photorealistic novel views synthesis of real-world scenes, most existing approaches require accurate prior camera poses. Although approaches for jointly recovering the radiance field and camera pose exist (BARF), they rely on a cumbersome coarse-to-fine auxiliary positional embedding to ensure good performance. We present Gaussian Activated neural Radiance Fields (GARF), a new positional embedding-free neural radiance field architecture - employing Gaussian activations - that outperforms the current state-of-the-art in terms of high fidelity reconstruction and pose estimation.
Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery
Jun 08, 2016
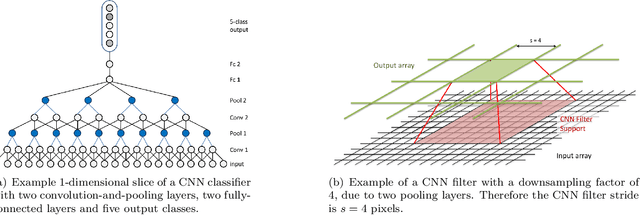
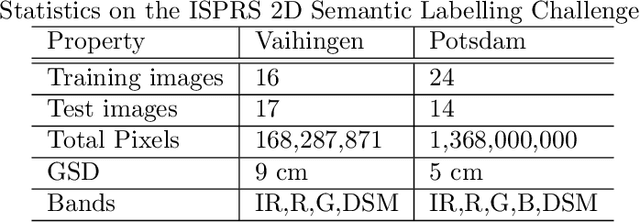
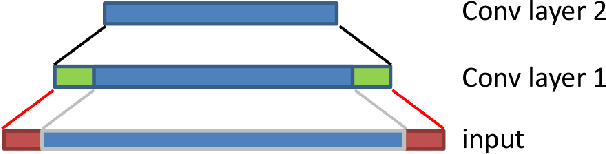
The trend towards higher resolution remote sensing imagery facilitates a transition from land-use classification to object-level scene understanding. Rather than relying purely on spectral content, appearance-based image features come into play. In this work, deep convolutional neural networks (CNNs) are applied to semantic labelling of high-resolution remote sensing data. Recent advances in fully convolutional networks (FCNs) are adapted to overhead data and shown to be as effective as in other domains. A full-resolution labelling is inferred using a deep FCN with no downsampling, obviating the need for deconvolution or interpolation. To make better use of image features, a pre-trained CNN is fine-tuned on remote sensing data in a hybrid network context, resulting in superior results compared to a network trained from scratch. The proposed approach is applied to the problem of labelling high-resolution aerial imagery, where fine boundary detail is important. The dense labelling yields state-of-the-art accuracy for the ISPRS Vaihingen and Potsdam benchmark data sets.
Performance Evaluation of Random Set Based Pedestrian Tracking Algorithms
Oct 25, 2012
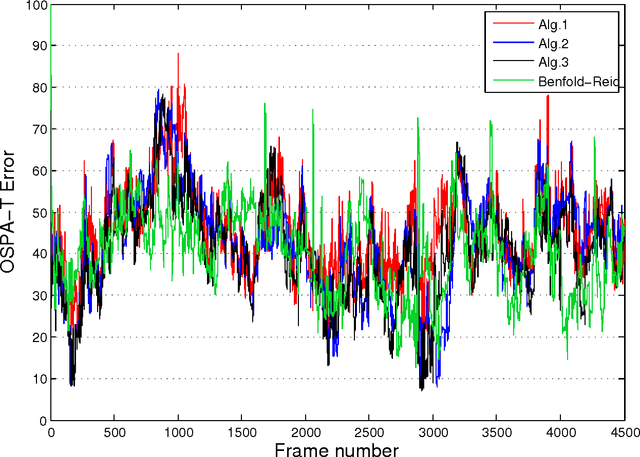
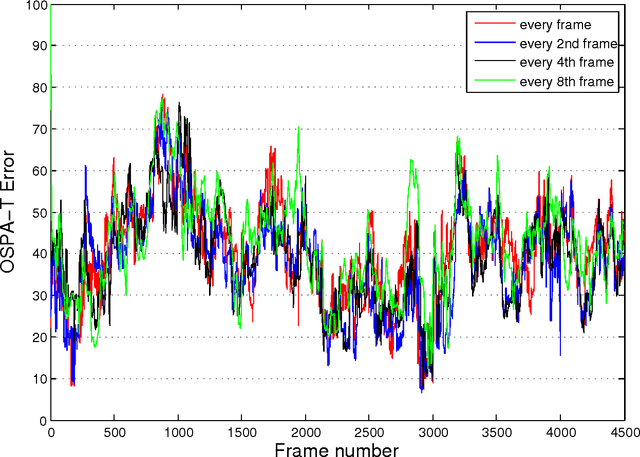

The paper evaluates the error performance of three random finite set based multi-object trackers in the context of pedestrian video tracking. The evaluation is carried out using a publicly available video dataset of 4500 frames (town centre street) for which the ground truth is available. The input to all pedestrian tracking algorithms is an identical set of head and body detections, obtained using the Histogram of Oriented Gradients (HOG) detector. The tracking error is measured using the recently proposed OSPA metric for tracks, adopted as the only known mathematically rigorous metric for measuring the distance between two sets of tracks. A comparative analysis is presented under various conditions.