 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram Generation from Diverse Video Demonstrations
Feb 01, 2023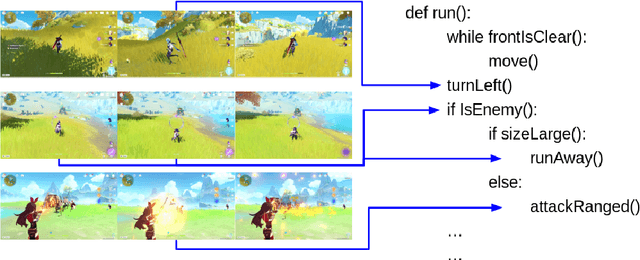
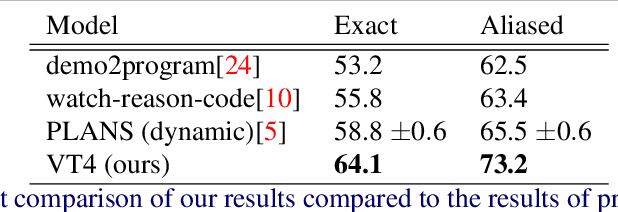
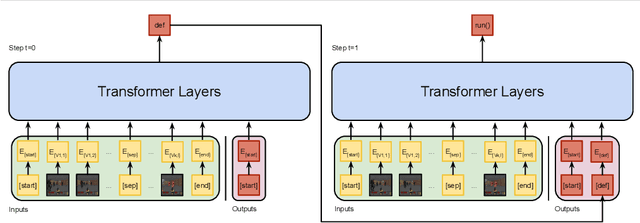

The ability to use inductive reasoning to extract general rules from multiple observations is a vital indicator of intelligence. As humans, we use this ability to not only interpret the world around us, but also to predict the outcomes of the various interactions we experience. Generalising over multiple observations is a task that has historically presented difficulties for machines to grasp, especially when requiring computer vision. In this paper, we propose a model that can extract general rules from video demonstrations by simultaneously performing summarisation and translation. Our approach differs from prior works by framing the problem as a multi-sequence-to-sequence task, wherein summarisation is learnt by the model. This allows our model to utilise edge cases that would otherwise be suppressed or discarded by traditional summarisation techniques. Additionally, we show that our approach can handle noisy specifications without the need for additional filtering methods. We evaluate our model by synthesising programs from video demonstrations in the Vizdoom environment achieving state-of-the-art results with a relative increase of 11.75% program accuracy on prior works
Reinforcement Learning with Attention that Works: A Self-Supervised Approach
Apr 06, 2019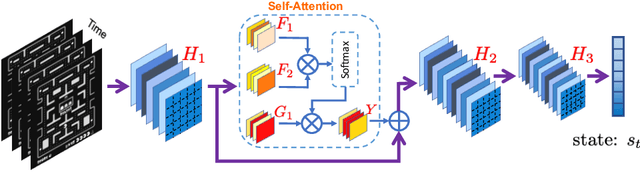
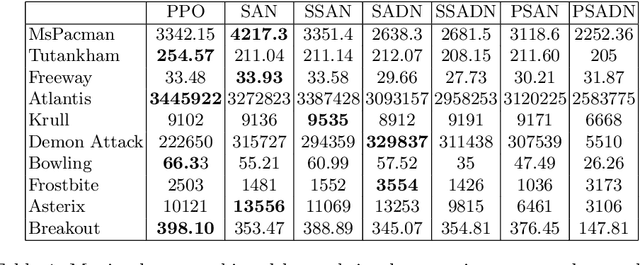
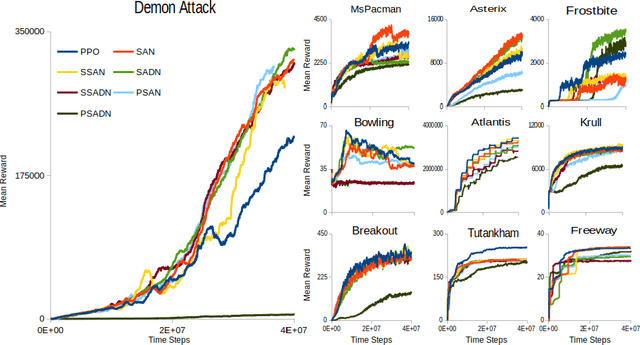
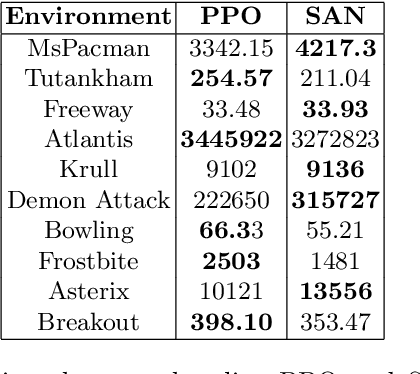
Attention models have had a significant positive impact on deep learning across a range of tasks. However previous attempts at integrating attention with reinforcement learning have failed to produce significant improvements. We propose the first combination of self attention and reinforcement learning that is capable of producing significant improvements, including new state of the art results in the Arcade Learning Environment. Unlike the selective attention models used in previous attempts, which constrain the attention via preconceived notions of importance, our implementation utilises the Markovian properties inherent in the state input. Our method produces a faithful visualisation of the policy, focusing on the behaviour of the agent. Our experiments demonstrate that the trained policies use multiple simultaneous foci of attention, and are able to modulate attention over time to deal with situations of partial observability.