 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen are Local Queries Useful for Robust Learning?
Oct 12, 2022

Distributional assumptions have been shown to be necessary for the robust learnability of concept classes when considering the exact-in-the-ball robust risk and access to random examples by Gourdeau et al. (2019). In this paper, we study learning models where the learner is given more power through the use of local queries, and give the first distribution-free algorithms that perform robust empirical risk minimization (ERM) for this notion of robustness. The first learning model we consider uses local membership queries (LMQ), where the learner can query the label of points near the training sample. We show that, under the uniform distribution, LMQs do not increase the robustness threshold of conjunctions and any superclass, e.g., decision lists and halfspaces. Faced with this negative result, we introduce the local equivalence query (LEQ) oracle, which returns whether the hypothesis and target concept agree in the perturbation region around a point in the training sample, as well as a counterexample if it exists. We show a separation result: on one hand, if the query radius $\lambda$ is strictly smaller than the adversary's perturbation budget $\rho$, then distribution-free robust learning is impossible for a wide variety of concept classes; on the other hand, the setting $\lambda=\rho$ allows us to develop robust ERM algorithms. We then bound the query complexity of these algorithms based on online learning guarantees and further improve these bounds for the special case of conjunctions. We finish by giving robust learning algorithms for halfspaces with margins on both $\{0,1\}^n$ and $\mathbb{R}^n$.
Sample Complexity Bounds for Robustly Learning Decision Lists against Evasion Attacks
May 12, 2022A fundamental problem in adversarial machine learning is to quantify how much training data is needed in the presence of evasion attacks. In this paper we address this issue within the framework of PAC learning, focusing on the class of decision lists. Given that distributional assumptions are essential in the adversarial setting, we work with probability distributions on the input data that satisfy a Lipschitz condition: nearby points have similar probability. Our key results illustrate that the adversary's budget (that is, the number of bits it can perturb on each input) is a fundamental quantity in determining the sample complexity of robust learning. Our first main result is a sample-complexity lower bound: the class of monotone conjunctions (essentially the simplest non-trivial hypothesis class on the Boolean hypercube) and any superclass has sample complexity at least exponential in the adversary's budget. Our second main result is a corresponding upper bound: for every fixed $k$ the class of $k$-decision lists has polynomial sample complexity against a $\log(n)$-bounded adversary. This sheds further light on the question of whether an efficient PAC learning algorithm can always be used as an efficient $\log(n)$-robust learning algorithm under the uniform distribution.
On the Hardness of Robust Classification
Sep 12, 2019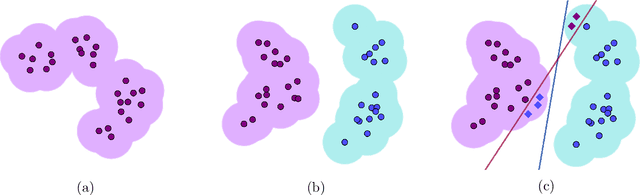
It is becoming increasingly important to understand the vulnerability of machine learning models to adversarial attacks. In this paper we study the feasibility of robust learning from the perspective of computational learning theory, considering both sample and computational complexity. In particular, our definition of robust learnability requires polynomial sample complexity. We start with two negative results. We show that no non-trivial concept class can be robustly learned in the distribution-free setting against an adversary who can perturb just a single input bit. We show moreover that the class of monotone conjunctions cannot be robustly learned under the uniform distribution against an adversary who can perturb $\omega(\log n)$ input bits. However if the adversary is restricted to perturbing $O(\log n)$ bits, then the class of monotone conjunctions can be robustly learned with respect to a general class of distributions (that includes the uniform distribution). Finally, we provide a simple proof of the computational hardness of robust learning on the boolean hypercube. Unlike previous results of this nature, our result does not rely on another computational model (e.g. the statistical query model) nor on any hardness assumption other than the existence of a hard learning problem in the PAC framework.
Nonnegative Matrix Factorization Requires Irrationality
Mar 22, 2017
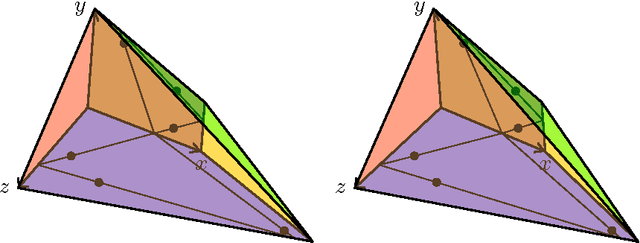
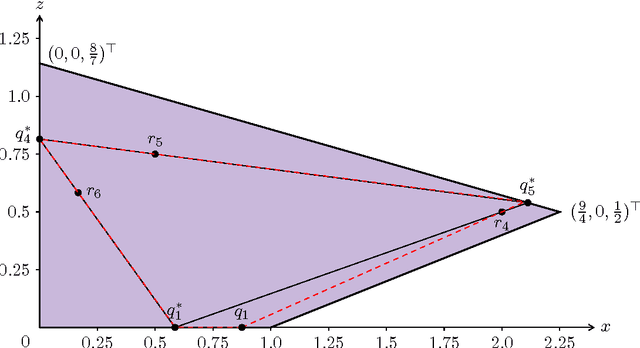
Nonnegative matrix factorization (NMF) is the problem of decomposing a given nonnegative $n \times m$ matrix $M$ into a product of a nonnegative $n \times d$ matrix $W$ and a nonnegative $d \times m$ matrix $H$. A longstanding open question, posed by Cohen and Rothblum in 1993, is whether a rational matrix $M$ always has an NMF of minimal inner dimension $d$ whose factors $W$ and $H$ are also rational. We answer this question negatively, by exhibiting a matrix for which $W$ and $H$ require irrational entries.
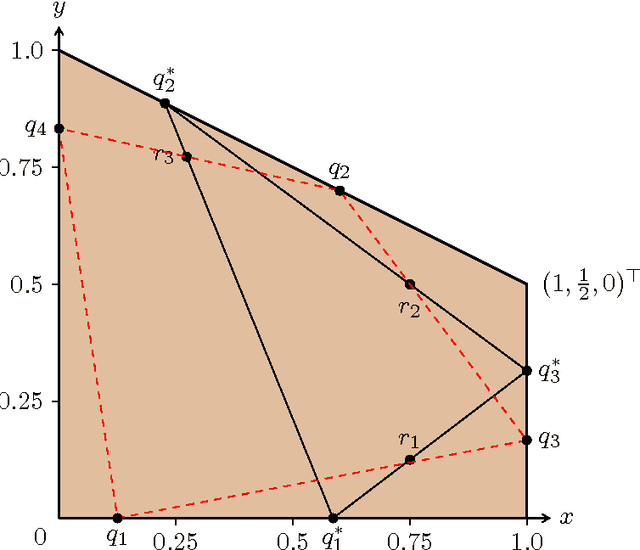
On Restricted Nonnegative Matrix Factorization
May 23, 2016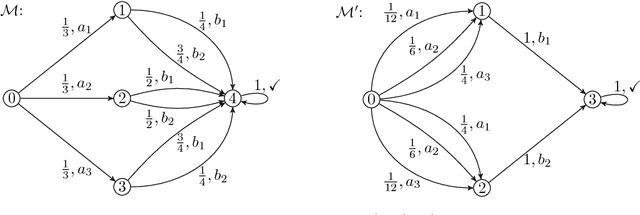

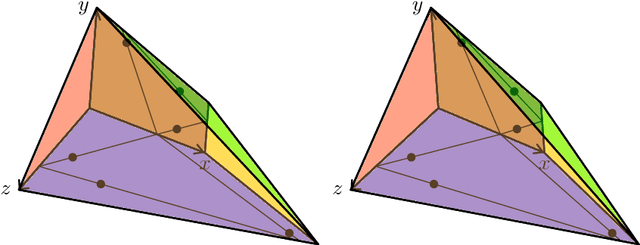

Nonnegative matrix factorization (NMF) is the problem of decomposing a given nonnegative $n \times m$ matrix $M$ into a product of a nonnegative $n \times d$ matrix $W$ and a nonnegative $d \times m$ matrix $H$. Restricted NMF requires in addition that the column spaces of $M$ and $W$ coincide. Finding the minimal inner dimension $d$ is known to be NP-hard, both for NMF and restricted NMF. We show that restricted NMF is closely related to a question about the nature of minimal probabilistic automata, posed by Paz in his seminal 1971 textbook. We use this connection to answer Paz's question negatively, thus falsifying a positive answer claimed in 1974. Furthermore, we investigate whether a rational matrix $M$ always has a restricted NMF of minimal inner dimension whose factors $W$ and $H$ are also rational. We show that this holds for matrices $M$ of rank at most $3$ and we exhibit a rank-$4$ matrix for which $W$ and $H$ require irrational entries.
Complexity of Equivalence and Learning for Multiplicity Tree Automata
Nov 27, 2014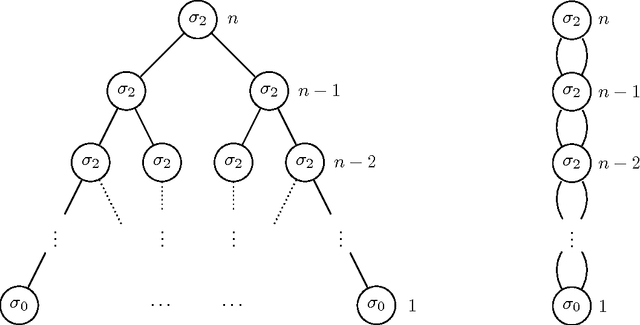

We consider the complexity of equivalence and learning for multiplicity tree automata, i.e., weighted tree automata over a field. We first show that the equivalence problem is logspace equivalent to polynomial identity testing, the complexity of which is a longstanding open problem. Secondly, we derive lower bounds on the number of queries needed to learn multiplicity tree automata in Angluin's exact learning model, over both arbitrary and fixed fields. Habrard and Oncina (2006) give an exact learning algorithm for multiplicity tree automata, in which the number of queries is proportional to the size of the target automaton and the size of a largest counterexample, represented as a tree, that is returned by the Teacher. However, the smallest tree-counterexample may be exponential in the size of the target automaton. Thus the above algorithm does not run in time polynomial in the size of the target automaton, and has query complexity exponential in the lower bound. Assuming a Teacher that returns minimal DAG representations of counterexamples, we give a new exact learning algorithm whose query complexity is quadratic in the target automaton size, almost matching the lower bound, and improving the best previously-known algorithm by an exponential factor.