 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Information Flow: A Network Flow Model for Tool Attributions in RAG Systems
Feb 04, 2026Many tool-based Retrieval Augmented Generation (RAG) systems lack precise mechanisms for tracing final responses back to specific tool components -- a critical gap as systems scale to complex multi-agent architectures. We present \textbf{Atomic Information Flow (AIF)}, a graph-based network flow model that decomposes tool outputs and LLM calls into atoms: indivisible, self-contained units of information. By modeling LLM orchestration as a directed flow of atoms from tool and LLM nodes to a response super-sink, AIF enables granular attribution metrics for AI explainability. Motivated by the max-flow min-cut theorem in network flow theory, we train a lightweight Gemma3 (4B parameter) language model as a context compressor to approximate the minimum cut of tool atoms using flow signals computed offline by AIF. We note that the base Gemma3-4B model struggles to identify critical information with \textbf{54.7\%} accuracy on HotpotQA, barely outperforming lexical baselines (BM25). However, post-training on AIF signals boosts accuracy to \textbf{82.71\%} (+28.01 points) while achieving \textbf{87.52\%} (+1.85\%) context token compression -- bridging the gap with the Gemma3-27B variant, a model nearly $7\times$ larger.
A YOLO-Based Semi-Automated Labeling Approach to Improve Fault Detection Efficiency in Railroad Videos
Apr 01, 2025



Manual labeling for large-scale image and video datasets is often time-intensive, error-prone, and costly, posing a significant barrier to efficient machine learning workflows in fault detection from railroad videos. This study introduces a semi-automated labeling method that utilizes a pre-trained You Only Look Once (YOLO) model to streamline the labeling process and enhance fault detection accuracy in railroad videos. By initiating the process with a small set of manually labeled data, our approach iteratively trains the YOLO model, using each cycle's output to improve model accuracy and progressively reduce the need for human intervention. To facilitate easy correction of model predictions, we developed a system to export YOLO's detection data as an editable text file, enabling rapid adjustments when detections require refinement. This approach decreases labeling time from an average of 2 to 4 minutes per image to 30 seconds to 2 minutes, effectively minimizing labor costs and labeling errors. Unlike costly AI based labeling solutions on paid platforms, our method provides a cost-effective alternative for researchers and practitioners handling large datasets in fault detection and other detection based machine learning applications.
SwarmCVT: Centroidal Voronoi Tessellation-Based Path Planning for Very-Large-Scale Robotics
Oct 03, 2024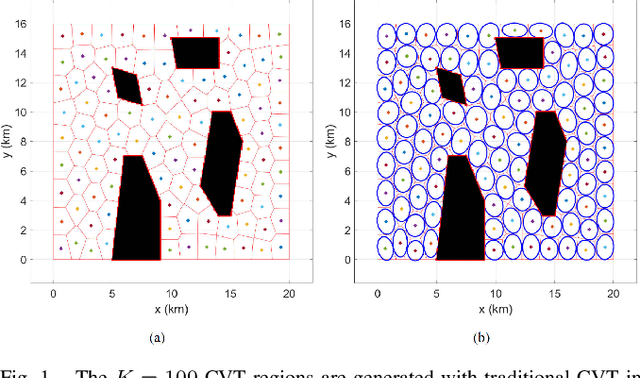

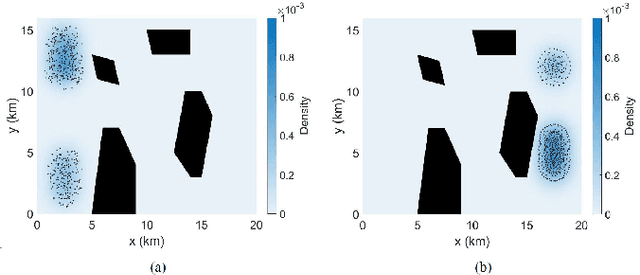
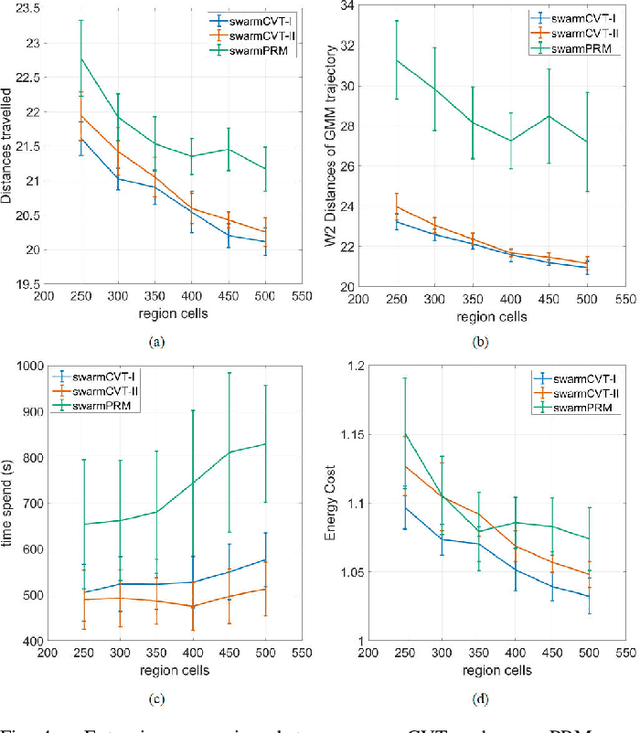
Swarm robotics, or very large-scale robotics (VLSR), has many meaningful applications for complicated tasks. However, the complexity of motion control and energy costs stack up quickly as the number of robots increases. In addressing this problem, our previous studies have formulated various methods employing macroscopic and microscopic approaches. These methods enable microscopic robots to adhere to a reference Gaussian mixture model (GMM) distribution observed at the macroscopic scale. As a result, optimizing the macroscopic level will result in an optimal overall result. However, all these methods require systematic and global generation of Gaussian components (GCs) within obstacle-free areas to construct the GMM trajectories. This work utilizes centroidal Voronoi tessellation to generate GCs methodically. Consequently, it demonstrates performance improvement while also ensuring consistency and reliability.