 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial recovery of agent rewards from latent spaces of the limit order book
Dec 09, 2019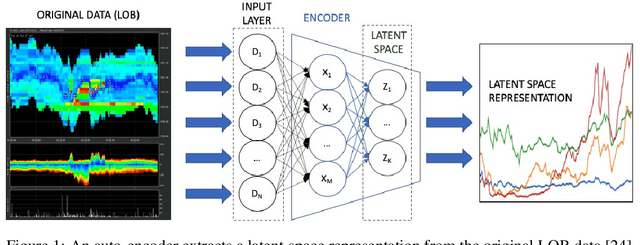
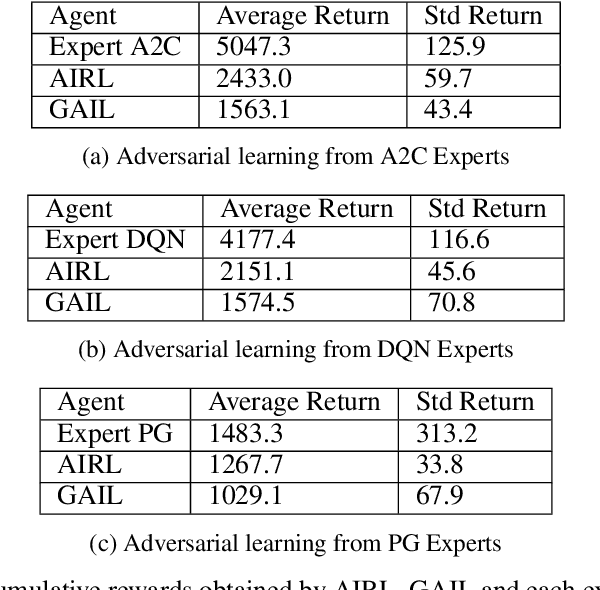
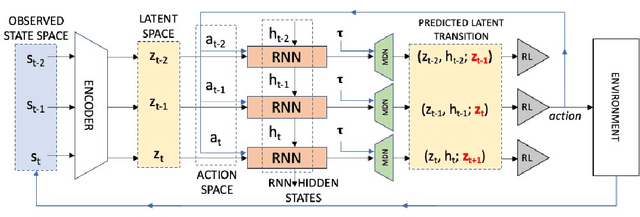
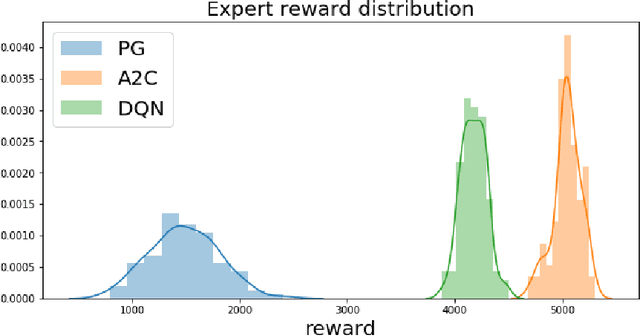
Inverse reinforcement learning has proved its ability to explain state-action trajectories of expert agents by recovering their underlying reward functions in increasingly challenging environments. Recent advances in adversarial learning have allowed extending inverse RL to applications with non-stationary environment dynamics unknown to the agents, arbitrary structures of reward functions and improved handling of the ambiguities inherent to the ill-posed nature of inverse RL. This is particularly relevant in real time applications on stochastic environments involving risk, like volatile financial markets. Moreover, recent work on simulation of complex environments enable learning algorithms to engage with real market data through simulations of its latent space representations, avoiding a costly exploration of the original environment. In this paper, we explore whether adversarial inverse RL algorithms can be adapted and trained within such latent space simulations from real market data, while maintaining their ability to recover agent rewards robust to variations in the underlying dynamics, and transfer them to new regimes of the original environment.
Towards Inverse Reinforcement Learning for Limit Order Book Dynamics
Jun 11, 2019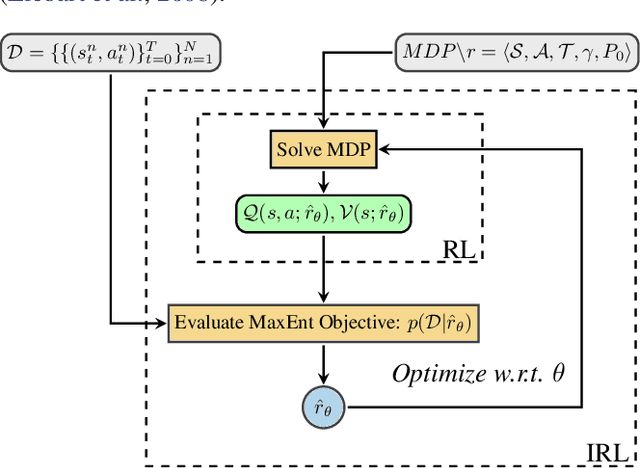

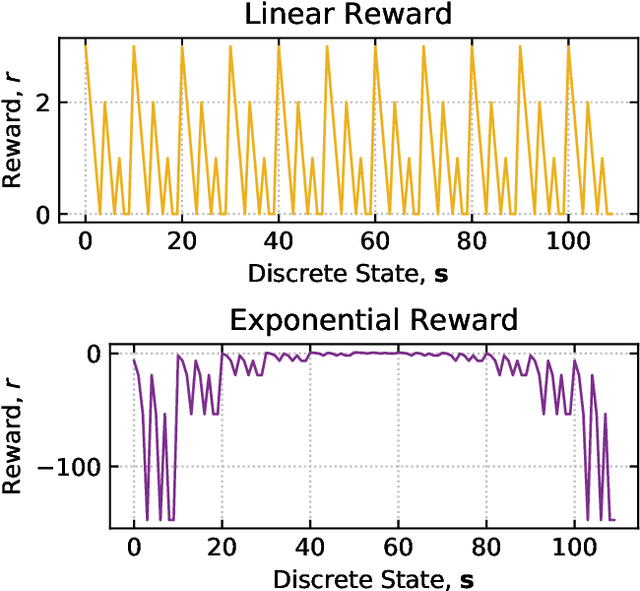
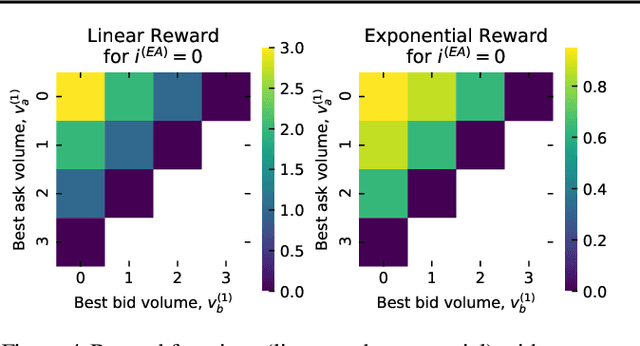
Multi-agent learning is a promising method to simulate aggregate competitive behaviour in finance. Learning expert agents' reward functions through their external demonstrations is hence particularly relevant for subsequent design of realistic agent-based simulations. Inverse Reinforcement Learning (IRL) aims at acquiring such reward functions through inference, allowing to generalize the resulting policy to states not observed in the past. This paper investigates whether IRL can infer such rewards from agents within real financial stochastic environments: limit order books (LOB). We introduce a simple one-level LOB, where the interactions of a number of stochastic agents and an expert trading agent are modelled as a Markov decision process. We consider two cases for the expert's reward: either a simple linear function of state features; or a complex, more realistic non-linear function. Given the expert agent's demonstrations, we attempt to discover their strategy by modelling their latent reward function using linear and Gaussian process (GP) regressors from previous literature, and our own approach through Bayesian neural networks (BNN). While the three methods can learn the linear case, only the GP-based and our proposed BNN methods are able to discover the non-linear reward case. Our BNN IRL algorithm outperforms the other two approaches as the number of samples increases. These results illustrate that complex behaviours, induced by non-linear reward functions amid agent-based stochastic scenarios, can be deduced through inference, encouraging the use of inverse reinforcement learning for opponent-modelling in multi-agent systems.