 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial recovery of agent rewards from latent spaces of the limit order book
Paper and Code
Dec 09, 2019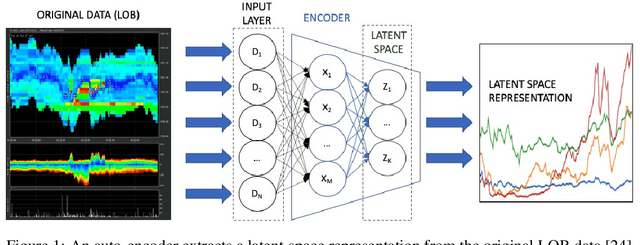
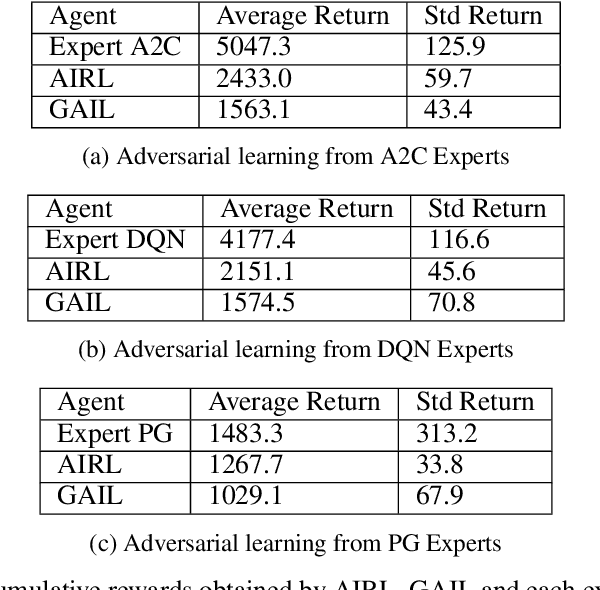
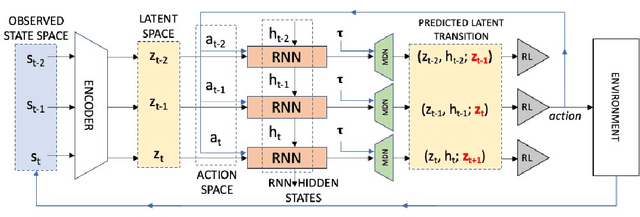
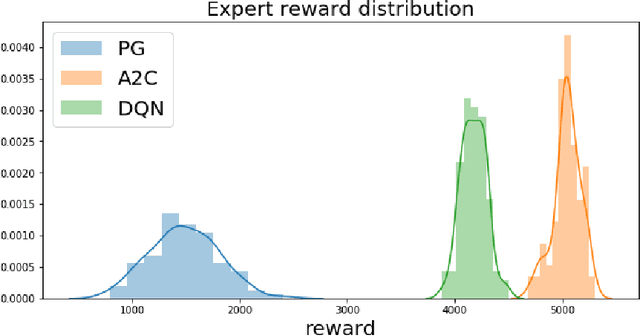
Inverse reinforcement learning has proved its ability to explain state-action trajectories of expert agents by recovering their underlying reward functions in increasingly challenging environments. Recent advances in adversarial learning have allowed extending inverse RL to applications with non-stationary environment dynamics unknown to the agents, arbitrary structures of reward functions and improved handling of the ambiguities inherent to the ill-posed nature of inverse RL. This is particularly relevant in real time applications on stochastic environments involving risk, like volatile financial markets. Moreover, recent work on simulation of complex environments enable learning algorithms to engage with real market data through simulations of its latent space representations, avoiding a costly exploration of the original environment. In this paper, we explore whether adversarial inverse RL algorithms can be adapted and trained within such latent space simulations from real market data, while maintaining their ability to recover agent rewards robust to variations in the underlying dynamics, and transfer them to new regimes of the original environment.