 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Directly Training Joint Energy-Based Models for Conditional Synthesis and Calibrated Prediction of Multi-Attribute Data
Jul 19, 2021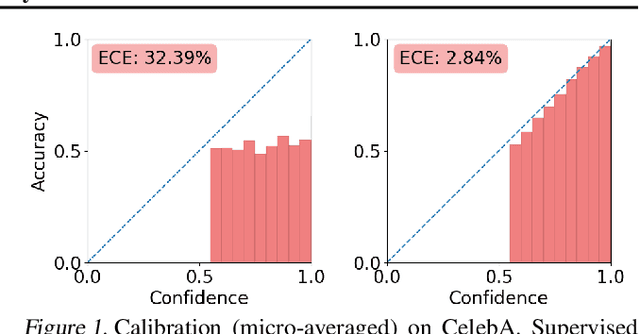

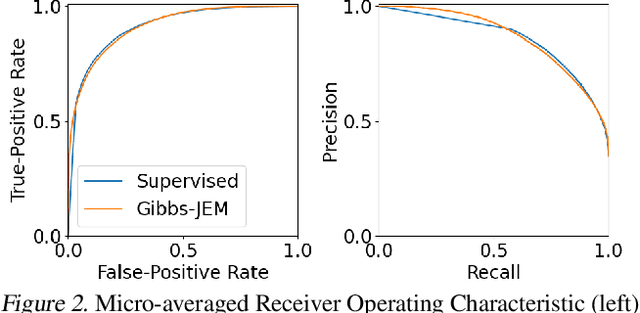
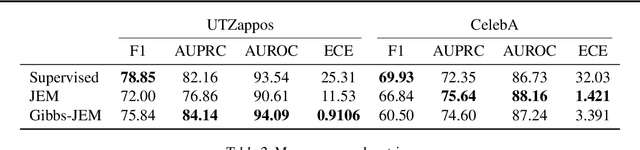
Multi-attribute classification generalizes classification, presenting new challenges for making accurate predictions and quantifying uncertainty. We build upon recent work and show that architectures for multi-attribute prediction can be reinterpreted as energy-based models (EBMs). While existing EBM approaches achieve strong discriminative performance, they are unable to generate samples conditioned on novel attribute combinations. We propose a simple extension which expands the capabilities of EBMs to generating accurate conditional samples. Our approach, combined with newly developed techniques in energy-based model training, allows us to directly maximize the likelihood of data and labels under the unnormalized joint distribution. We evaluate our proposed approach on high-dimensional image data with high-dimensional binary attribute labels. We find our models are capable of both accurate, calibrated predictions and high-quality conditional synthesis of novel attribute combinations.
No MCMC for me: Amortized sampling for fast and stable training of energy-based models
Oct 14, 2020
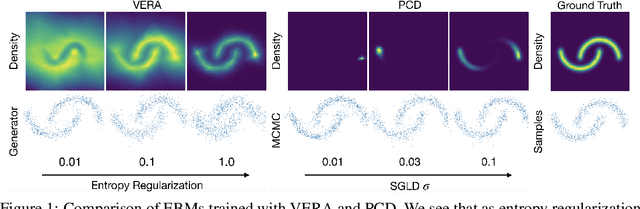


Energy-Based Models (EBMs) present a flexible and appealing way to represent uncertainty. Despite recent advances, training EBMs on high-dimensional data remains a challenging problem as the state-of-the-art approaches are costly, unstable, and require considerable tuning and domain expertise to apply successfully. In this work, we present a simple method for training EBMs at scale which uses an entropy-regularized generator to amortize the MCMC sampling typically used in EBM training. We improve upon prior MCMC-based entropy regularization methods with a fast variational approximation. We demonstrate the effectiveness of our approach by using it to train tractable likelihood models. Next, we apply our estimator to the recently proposed Joint Energy Model (JEM), where we match the original performance with faster and stable training. This allows us to extend JEM models to semi-supervised classification on tabular data from a variety of continuous domains.
Learning Differential Equations that are Easy to Solve
Jul 09, 2020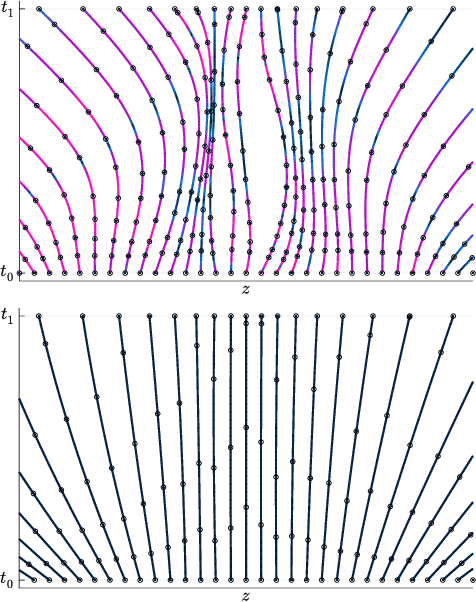

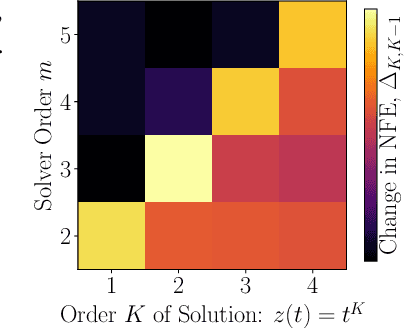

Differential equations parameterized by neural networks become expensive to solve numerically as training progresses. We propose a remedy that encourages learned dynamics to be easier to solve. Specifically, we introduce a differentiable surrogate for the time cost of standard numerical solvers, using higher-order derivatives of solution trajectories. These derivatives are efficient to compute with Taylor-mode automatic differentiation. Optimizing this additional objective trades model performance against the time cost of solving the learned dynamics. We demonstrate our approach by training substantially faster, while nearly as accurate, models in supervised classification, density estimation, and time-series modelling tasks.